
우리는 Azure AI 서비스를 이렇게 구축했습니다
안녕하세요, Cloud엔지니어링팀 김정준 전임입니다. 저는 팀에서 GPU 서비스 파트, 주로 R&D존과 Azure GPU 상품의 거버넌스 관련 업무를 담당하고 있습니다.
이 아티클을 통해 KT Azure 테넌트 내에서 랜딩존과 R&D존 AI 학습 인프라를 안정적으로 운영할 수 있도록, Azure AI 서비스(Azure Machine Learning, CycleCloud, AI Foundry)를 기반으로 인프라를 구축한 과정을 공유하려고 합니다. 이번 프로젝트는 단순한 서비스 연결을 넘어서, Private 설정 기반 보안 강화와 표준화된 학습 환경 제공에 초점을 맞췄습니다.
시작점 – 우리는 왜 새롭게 인프라를 구성해야 했을까?
기존 On-premise 환경에서 Azure 클라우드로 전환하여 H100 GPU 기반의 학습 인프라를 구축하게 된 데에는 명확한 과제가 있었습니다.
기존 AI 학습 환경은 다음 두 가지 핵심 문제에 직면해 있었습니다:
-
GPU 노드 운영의 비효율성과 장애 발생 시 긴 리드타임
→ 고성능 GPU 자원의 확보 및 유지보수가 어려웠고, 장애 발생 시 복구에 많은 시간이 소요되었습니다.
-
사용자별 자원 및 권한, 네트워크 정책 관리의 복잡성
→ 팀이나 사용자마다 다른 자원 요구사항과 접근 권한을 수작업으로 관리해야 했으며, 방화벽 정책 설정 역시 반복적이고 오류 가능성이 높았습니다.
이러한 문제를 해결하기 위해,Azure의 클라우드 네이티브 서비스를 기반으로 AI 학습에 최적화된 안전하고 확장 가능한 인프라를 새롭게 설계하고 구축하게 되었습니다.
어떤 환경에 구축했나 - Landing Zone과 R&D Zone
현재 Azure KT 테넌트에는 크게 두 가지의 Zone이 존재합니다. Landing Zone과R&D Zone입니다.
각 Zone은 목적과 보안 수준, 사용자 권한 구성 측면에서 뚜렷하게 구분되며, 서비스의 안전성과 유연성을 동시에 확보하기 위한 이중 구조로 설계되었습니다.
-
Landing Zone은 KT의 클라우드 운영 표준에 따라,운영 환경의 안정성과 보안성을 보장하는 기반 인프라역할을 수행합니다.
-
반면,R&D Zone은 개인정보를 취급하지 않는 전제하에,완화된 보안 정책과 높은 자율성을 제공하는 실험 중심의 공간입니다.
이제 각 Zone의 목적과 구조를 하나씩 살펴보겠습니다.
✅ Landing Zone
목적
주요 특징
-
Hub & Spoke 아키텍처 기반의 네트워크 설계
중앙 통제형 VNet(Hub)을 중심으로 각 환경(Spoke)이 연결되는 구조를 채택하여,트래픽 흐름 제어와 보안 정책 통합 관리가 가능하도록 구성하였습니다.
-
전면 Private 통신 경로 구성
모든 핵심 리소스는Private Endpoint + Private DNS Zone을 통해 통신하며, 외부 노출 없이 내부적으로만 안전하게 접근이 이루어집니다.
-
정책 기반 자동화 템플릿 적용
Azure Policy, RBAC(Role-Based Access Control), NSG(Network Security Group), UDR(User Defined Route) 등을 포함한표준화된 거버넌스 템플릿을 IaC로 자동 배포함으로써,보안 및 운영 표준을 일관되게 적용합니다.
✅ R&D Zone
목적
개인정보를 취급하지 않는 전제하에, 완화된 보안 정책을 적용하여 연구 및 개발 조직이 자유롭게 모델을 학습하고 실험할 수 있는 환경을 제공합니다. 이는 반복적인 실험과 빠른 프로토타이핑이 요구되는 AI 개발 특성에 최적화된 인프라로, 실사용 중심의 환경을 목표로 설계되었습니다.
주요 특징
-
자율성을 고려한 권한 설계
Landing Zone에 비해개별 사용자 및 팀 단위의 리소스 제어 권한을 확대하여, 보다 자율적인 리소스 운영과 실험이 가능하도록 구성했습니다.
-
Service Endpoint 기반 내부 통신
네트워크 연결은Service Endpoint를 활용하여간결하면서도 통제 가능한 통신 경로를 유지합니다. 이는 Private Endpoint 대비 복잡도를 낮추고, 실험용 워크로드에 적합한 성능을 제공합니다.
-
사내망과 완전히 분리된 독립 실행 환경
내부 사내망과의 연결이분리된 클라우드 네트워크를 기반으로, 보안 정책은 완화하되위험 노출 최소화를 유지할 수 있도록 설계했습니다.
-
유연한 정책 적용
고정된 템플릿보다유연한 거버넌스를 우선시하여, 사용자가 주도적으로 AI 실험과 학습을 진행할 수 있도록 하였습니다.
Azure AI 서비스별 구축 후기
현재 각 환경 별 구축되어 있는 Azure AI 서비스의 아키텍처는 아래와 같습니다.
기본적으로 전부 Public → Private 한 설정으로 개별 설정을 변경하면서 테스트 및 구축을 진행하였고 환경 별로 변경이 필요한 부분은 주로 네트워킹 설정을 변경하여 구축을 완료하였습니다.
Azure Machine Learning
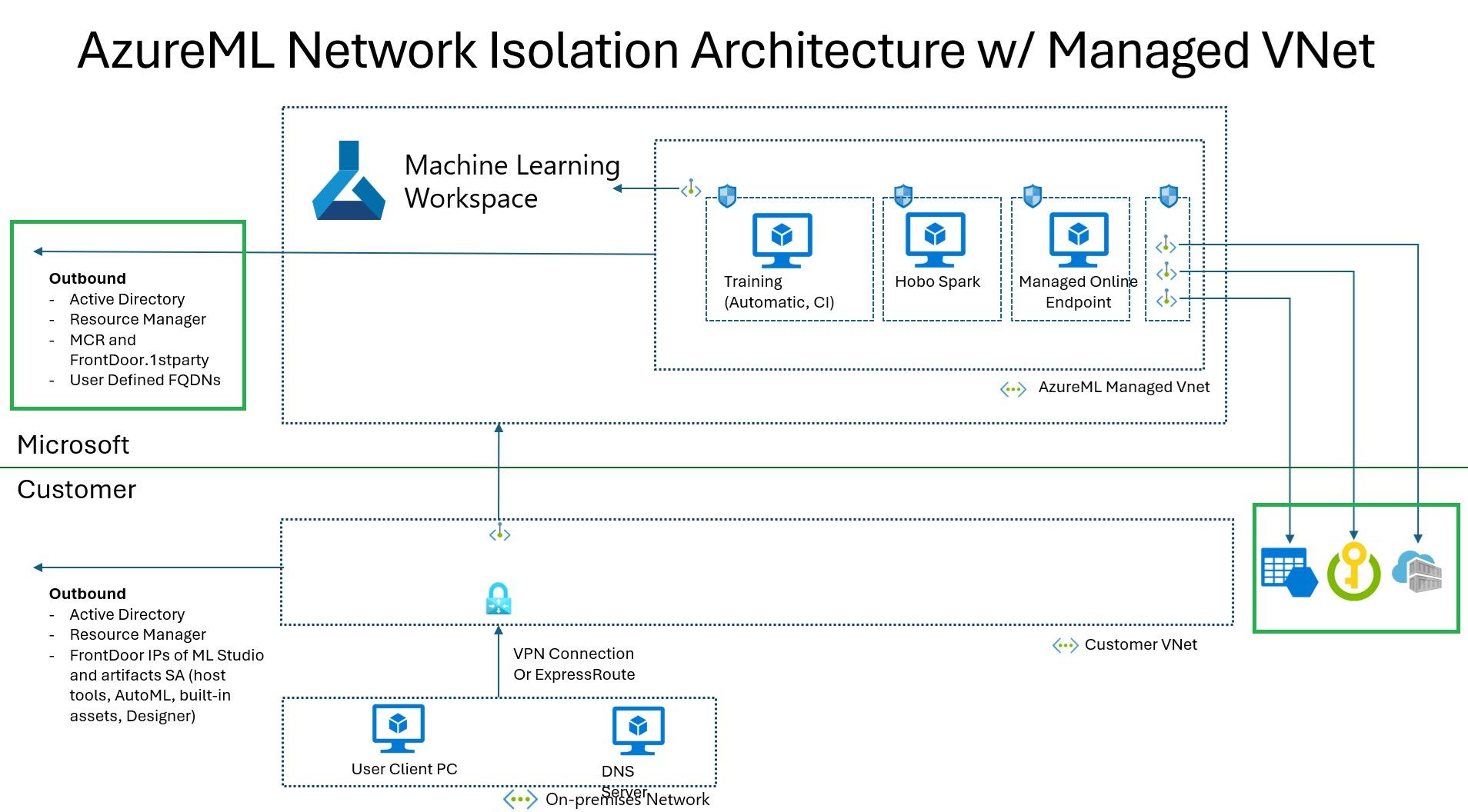
그림1. Azure Machine Learning Workspace의 아키텍처
Azure Machine Learning은 PaaS(Platform-as-a-Service) 상품으로 아래와 같은 특징을 가지고 있습니다.
-
플랫폼 제공: 인프라 관리 없이 모델 개발, 학습, 배포까지 가능한 플랫폼을 제공합니다.
-
추상화 수준: 사용자에게 VM이나 컨테이너 관리 부담 없이 ML 워크플로우를 구축할 수 있게 합니다.
-
확장성 및 자동화 지원: AutoML, MLOps, 파이프라인 등 고급 기능을 플랫폼 차원에서 지원합니다.
즉, Azure Machine Learning은 사용자가 모델 개발과 운영에 집중할 수 있도록 플랫폼을 제공하는PaaS형 AI 개발 환경입니다.
Azure Machine Learning은 아키텍처에서 보이듯이 Key Vault, Storage Account, Container Registry가 필수적으로 연결이 필요합니다. 기본적으로 Private 설정으로 구축을 하기 위해 모든 리소스는 기본적으로 Private endpoint를 생성하여 연결하였고 연결된 리소스에 접근 또한 RBAC 통해 안전하게 접근하도록 구축하였습니다.
Azure AI Foundry
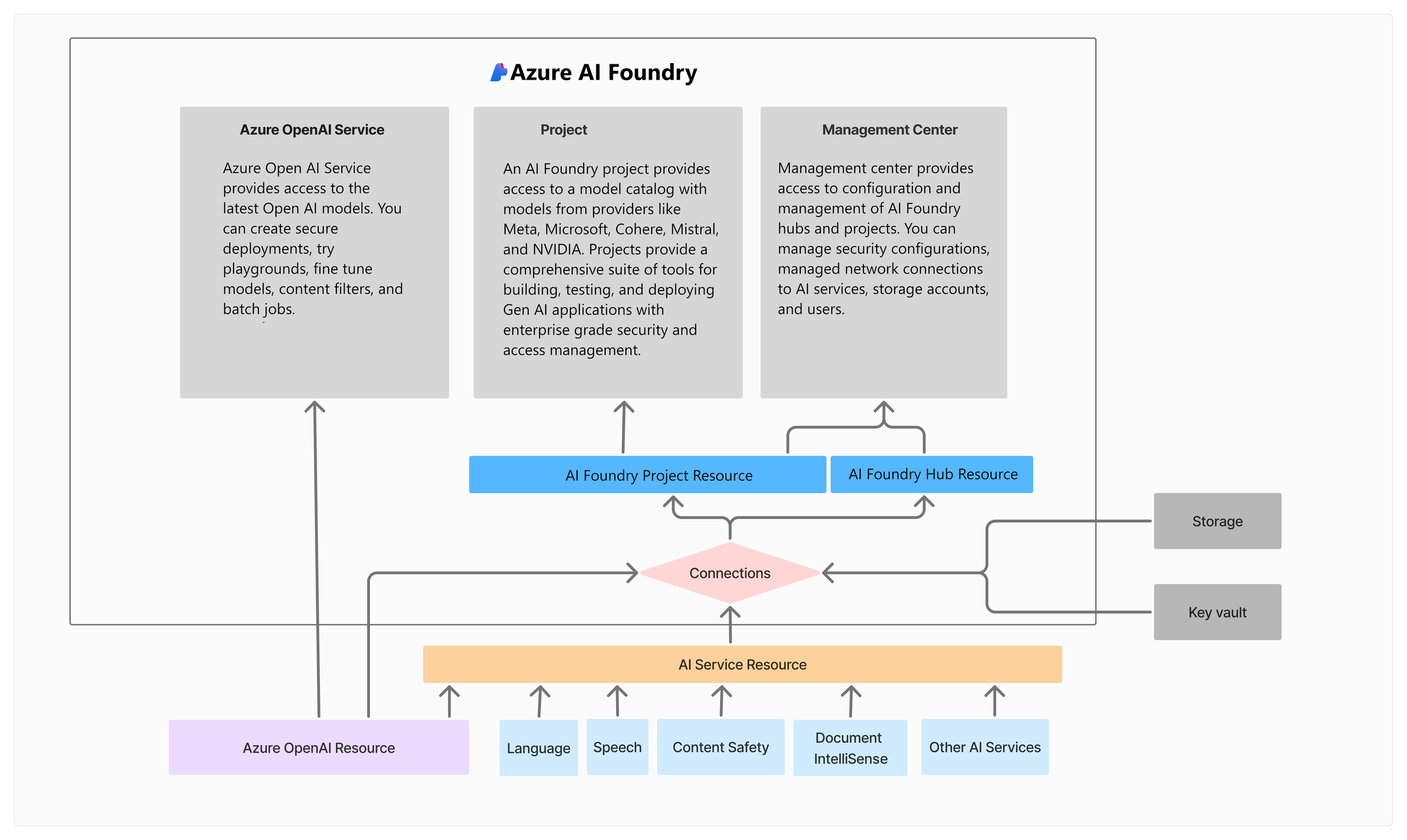
그림2. Azure AI Foundry의 아키텍처
Azure AI Foundry는 기본적으로 Azure Machine Learning의 기능과 인프라를 확장하여 구성된 상위 개념의 PaaS 상품입니다.
-
Hub 와 Project 구조: 인프라 및 권한을 중앙에서 관리하는Hub와, 실제 모델 학습 및 AI 개발이 이루어지는 독립적인 작업 공간인Project로 구성됩니다.
Hub는 네트워크, 데이터 접근, 정책, 리소스 할당 등 공통 인프라를 제어하며, 여러 Project에 일관된 보안과 거버넌스를 제공합니다.
반면, Project는 각 팀이나 워크로드별로 분리된 환경을 제공하여, 유연한 개발과 협업이 가능하도록 지원합니다.
-
AI Service 연결: AI Search, Azure OpenAI 등의 다양한 Azure AI 서비스와 손쉽게 연동할 수 있으며, 이를 통해 고도화된AI Agent를 빠르게 개발하고 배포할 수 있습니다. 이러한 서비스들은 Foundry Project 내에서 통합되어 사용 가능하며, 자연어 처리, 검색 최적화, 문서 요약 등 다양한 AI 시나리오를 구현하는 데 활용됩니다.
Azure Machine Learning 기반의 PaaS 상품이다 보니, 초기 구축 시에는 Azure AI Foundry 고유 기능보다는 Azure Machine Learning의 기존 설정을 그대로 활용하여 환경을 구성하였습니다. Foundry 자체보다는, 연결 가능한 AI 서비스들과 Agent 기능 구현에 더 중점을 두고 프로젝트를 진행하였습니다.
Cyclecloud
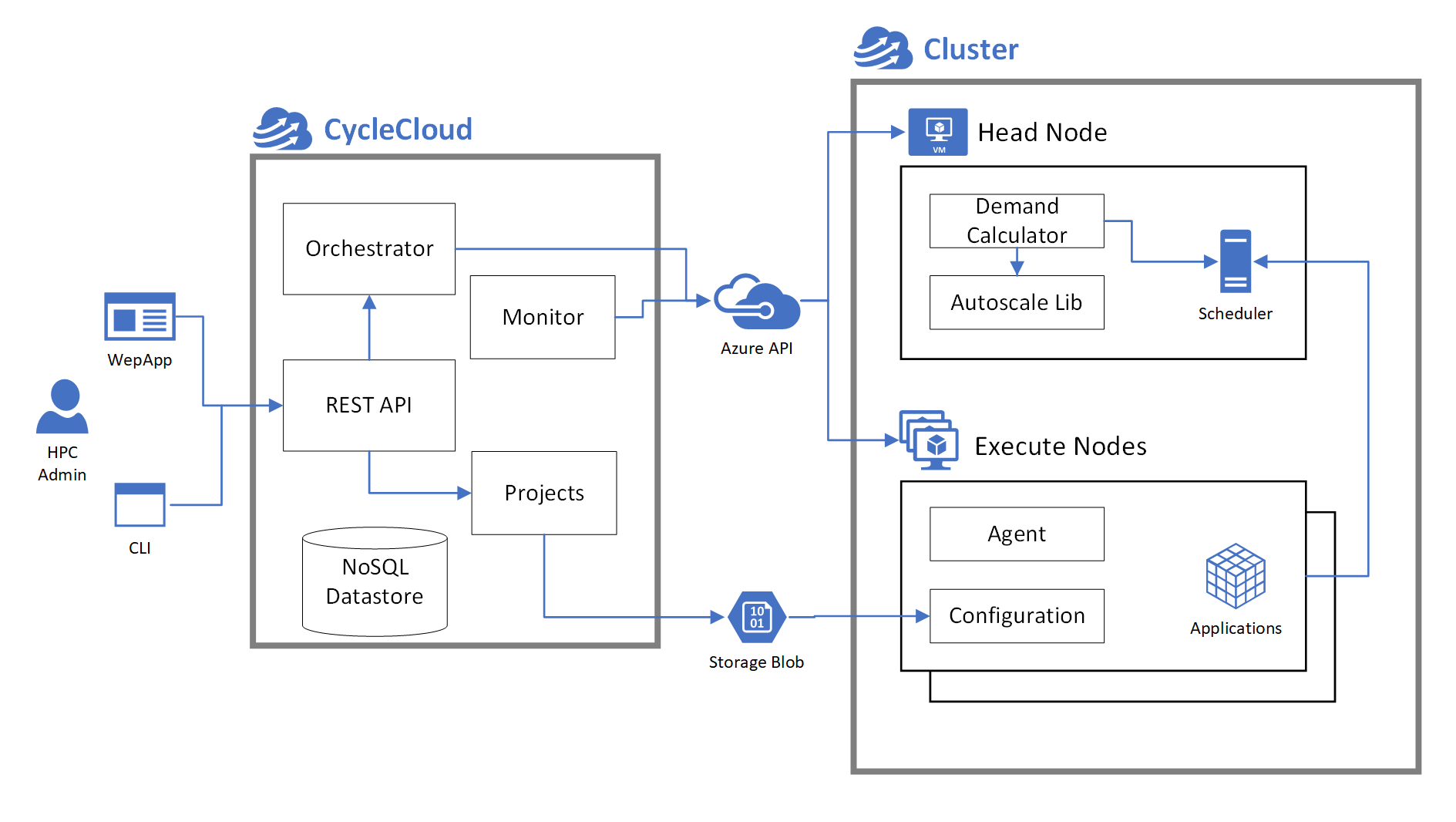
그림3. Cyclecloud의 아키텍처
CycleCloud는 HPC(High Performance Computing) 워크로드를 Azure 상에서 유연하게 관리할 수 있도록 지원하는 플랫폼으로, 다음과 같은 구조를 가집니다:
-
Scheduler VM (헤드 노드)
클러스터의 중심 역할을 하는 노드로, Slurm과 같은 스케줄러가 설치되어 있으며, 작업 스케줄링 및 클러스터 제어 기능을 수행합니다.
이 노드는 메타정보를 기반으로 클러스터 상태를 관리하며, Slurm 명령어를 통해 Autoscaling을 제어합니다.
-
Execute Nodes (실행 노드)
실제 계산 작업을 수행하는 노드들로, 필요에 따라Azure VMSS (Virtual Machine Scale Set)형태로 자동 생성 및 제거됩니다.
GPU 워크로드의 경우, GPU 기반 VM이 자동으로 프로비저닝되며, 작업 부하에 따라 탄력적으로 확장/축소됩니다.
Cyclecloud는 Azure 자원과 통신하며 클러스터 템플릿 기반으로 인프라를 배포하고, 사용자가 정의한 설정에 따라 클러스터를 자동화된 방식으로 운영합니다. 실제 학습 및 클러스터 운영은 Slurm 명령어를 사용하여 작업 제출(sbatch), 상태 확인(squeue), 노드 제어(scontrol) 등 HPC 환경에서의 표준 workflow를 그대로 유지하면서 수행됩니다.
초기 CycleCloud 및 HPC 환경 구축 과정에서는 다음과 같은 다양한 이슈를 경험하며, 실질적인 운영 노하우가 축적 되었습니다:
-
Outbound 트래픽 제한으로 인한 연결 실패
방화벽 정책상 Outbound가 차단되어 있어, CycleCloud 구성 요소 및 스케줄러가 필수 리소스에 접근하지 못하는 문제가 발생.
→ 필요한FQDN 및 포트 정보를 식별하고 방화벽 예외를 등록하는 작업에 시간이 소요됨.
-
OS 버전 및 컨테이너 이미지 비호환 문제
특정 VM 이미지 또는 커널 버전이 HPC 워크로드(특히 GPU 및 MPI 기반 통신)와 호환되지 않아, 수차례 테스트를 통해 적절한 조합을 찾아야 했음.
특히NVIDIA 드라이버 및 CUDA 호환성문제도 빈번히 발생함.
-
GPU 노드 간 Infiniband 통신 설정 이슈
고속 네트워크 통신을 위해 필수적인 Infiniband 설정에서 노드 간 RDMA 연결 오류가 발생.
IB 장비 및 드라이버 설치 외에도MPI 통신 검증을 위한 수동 테스트가 필요했음.
-
Azure 데이터 센터 내 GPU 노드의 불안정성
특정 지역(AZ) 내 GPU VM의 할당 불가 또는 GPU Missing 등의 현상이 간헐적으로 발생.
→ Support Request를 통해 문제있는 노드 식별 후 제외 처리
| 구축 중 가장 어렵고 시간이 많이 소요되었던 작업
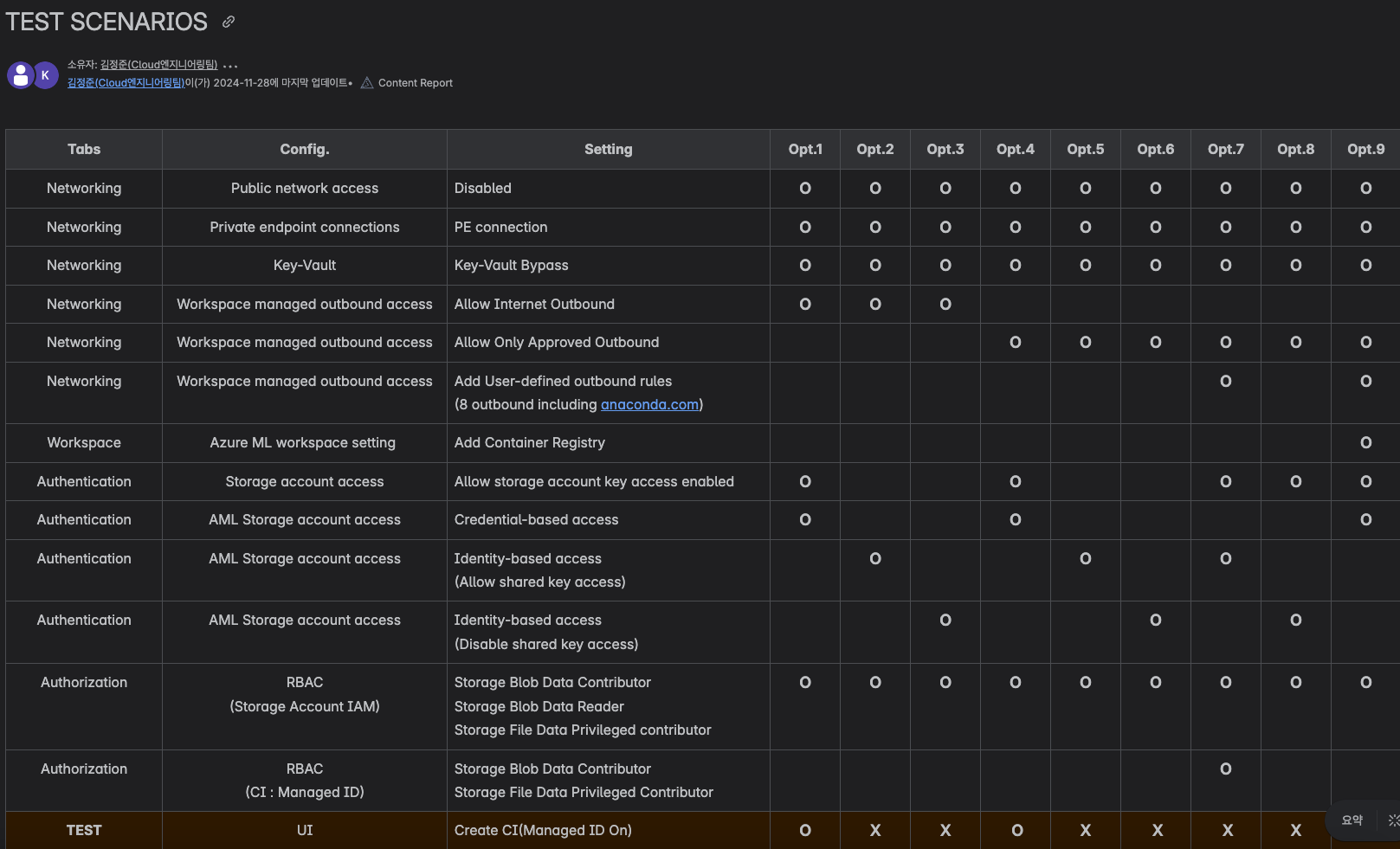
그림4. Azure ML TEST SCENARIO 사례 (총 9개의 옵션으로 진행)
-
복잡한 테스트 구성
Azure Machine Learning의 다양한 구성 옵션을 검증하기 위해 총 9개의 테스트 시나리오를 수행하였으며, 이로 인해 환경별 설정 및 비교 분석에 상당한 시간이 소요되었습니다.
-
방화벽 설정을 위한 FQDN 식별
샘플 학습 코드 실행에 필요한최소 FQDN 목록을 파악하고 이를 방화벽에 등록하는 과정이 명확히 문서화되어 있지 않아, 반복적인 테스트와 분석을 통해 직접 도출해야 했습니다.
-
Private 환경 구축 시의 미비한 레퍼런스
기능적으로는 지원되지만 실제로 Private 환경에서의 구축 사례나 공식 문서가 거의 없어, 예상치 못한 설정 충돌 및 권한 문제 등이 자주 발생하였습니다.
-
미표기된 Preview 기능 관련 이슈
사용자 인증과 관련된 일부 기능이 Preview 상태였음에도 불구하고 공식 문서에 명시되지 않아, 여러 차례 Support Request를 통해서야 해당 기능이 현재 사용 불가능하다는 점을 확인할 수 있었습니다.
-
AI 서비스의 지속적인 변경 사항
AI Foundry는 여전히 제품 업데이트가 활발히 진행 중인 상황으로, 문서와 실제 동작 간의 차이로 인해 PoC 및 환경 설정 단계에서 많은 시행착오가 발생하였습니다.
❙ 기억에 남는 작업
-
제품 개선에 기여한 피드백 경험
구축 중 발견한 기술적 이슈들을 분석하여 Microsoft Product Group에 공유하였고, 이 중 일부가Action Item으로 채택되어 공식 피드백을 받는 등 제품 개선에 직접 기여할 수 있었습니다.
-
문서 반영 성과
Support Request를 통해 제기한 기술 문의 사항이 Microsoft 공식 문서에 반영되어 내용이 업데이트되는 등,기술 커뮤니티와의 실질적인 협업 성과를 체감할 수 있었습니다.
보안은 이렇게 강화했습니다 - Private by default
각 환경 별 특성에 맞도록 Policy를 통해 Public 접근을 차단하고 내부 전용 네트워크 기반의 인프라를 구성하기 위해 다음과 같은 설정을 적용했습니다. 여기에 추가로 ZTNA와 Entra ID 인증 기반으로 외부 노출 없이도 각 환경 내에서 안정적인 학습 및 배포가 가능해졌습니다.
✅ Landing Zone
-
AI 서비스 모두Private Endpoint로만 접근 가능
-
Azure Machine Learning, Azure AI Foundry의 Outbound 허용을 보안 협의 후 설정
-
Key Vault, Storage, Container Registry 등도 전부 Private Endpoint로 연결
✅ R&D Zone
-
AI 서비스 모두Service Endpoint(특정 IP 및 VNET)로 접근 가능
-
Azure Machine Learning, Azure AI Foundry의 Outbound 허용을 사용자가 직접 설정 가능
-
Key Vault, Storage, Container Registry 등 필요한 서비스는 Service Endpoint 설정
회고 - 인프라 그 이상을 만든 경험
이번 프로젝트는 단순한 인프라 구축이 아니라, AI 개발을 위한 체계적인 "플랫폼"을 만드는 과정이었습니다.
-
“Private by default”전략으로 보안성과 정책 일관성 확보
-
CycleCloud 기반 클러스터로 고성능 학습 환경 제공
-
Azure Machine Learning, Azure AI Foundry를 통해 인프라 관리 없이 편리한 학습 환경 제공
무엇보다 중요한 것은 “표준을 정의했다는 것”입니다. 이 표준은 이후 다른 조직, 다른 프로젝트에도 반복 가능하다는 점에서 큰 의미가 있다고 생각합니다.
지금은 이 인프라 위에서 실제 AI 모델 학습이 진행되고 있습니다.
앞으로는 MLOps 파이프라인 구축과 GPU 자원 효율화 전략에 대해 또 다른 이야기를 들려드릴 수 있길 기대합니다.