
소개
안녕하세요, KT에서 추천 모델을 개발하고 있는 이호엽입니다. 저희 D-Insight팀에서는 다양한 고객 데이터를 활용하여, 고객이 필요한 상품과 서비스를 놓치지 않도록 하기 위한 추천 모델을 중점적으로 연구, 개발하고 있습니다. 추천 모델은 고객이 남긴 행동 데이터를 기반으로 고객을 이해하는 것에서부터 시작하여 고객에게 적합한 상품을 제공하기까지 많은 이해관계자가 연관되어 있는 매우 매력적인 도메인입니다.
1) 고객을 잘 이해하기 위해 어떤 데이터를 남겨야 하는지 고민도 하고, 2) 데이터를 효율적으로 수집 및 보관하는 방법과, 3) 수집한 데이터를 기반으로 고객이 필요할 것으로 생각하는 상품과 서비스를 발견해주는 모델에 대한 고민, 4) 수많은 고객의 요청에 대해서 지연 없이 제공하기 위한 기술과, 5) 고객이 필요하다고 생각하는 상품과 서비스를 기획하고, 6) 저희가 제공한 추천을 고객이 만족했는지 모니터링 하는 방법에 대한 고민까지, 모두 KT에서 추천을 잘 하기 위해서 고민하고 있는 것들입니다. KT에서는 이런 각 요소들을 더 발전시키기 위해서, 데이터 엔지니어, 데이터 사이언티스트, 백엔드 개발자, 서비스 기획자 등이 함께 머리를 맞대고 있습니다.
이 글에서는 위의 모든 고민들 중에 세 번째에 있는 “수집한 데이터를 기반으로 고객이 필요할 것으로 생각하는 상품과 서비스를 찾는 모델”를 중점으로 설명드리고자 합니다. 더 구체적으로는, 고전적인 협업 필터링(collaborative filtering; CF)기반의 추천부터 최신 LLM(large language model)을 활용한 추천 모델까지 어떤 흐름으로 발전해왔는지에 대해서 말씀드리고자 합니다.
데이터 소개
추천 모델을 설명 드리기에 앞서, 가장 기본이 되는 데이터에 대해서 설명 드리겠습니다. 아마도 이 부분을 잘 설명드려야 모델도 더 잘 이해하실 수 있으실 겁니다.
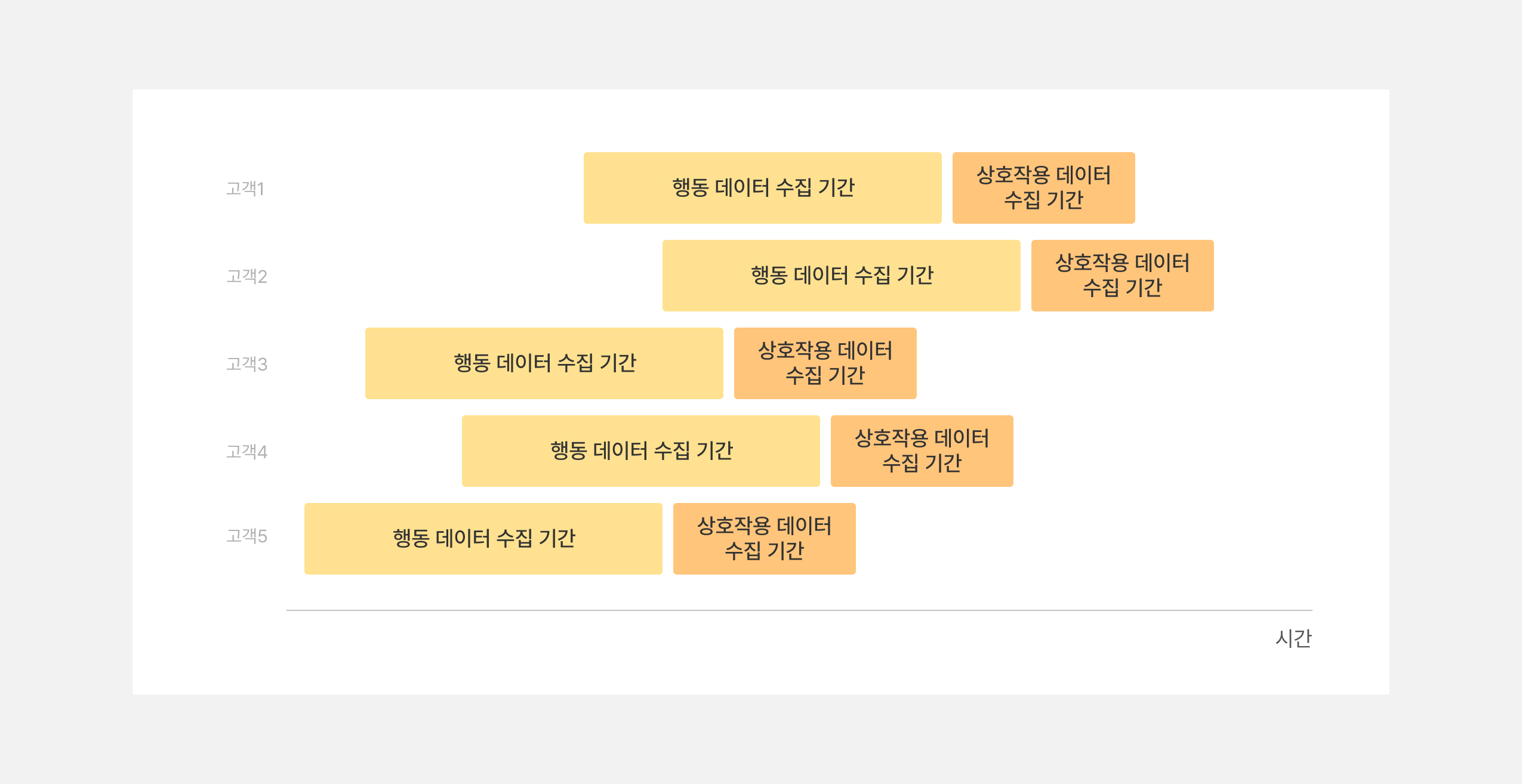
추천을 위한 데이터는 아래 그림과 같이 구성됩니다. 그림에서 가로 축은 시간을 의미하고, 세로 축은 각 고객들을 의미합니다. 그리고 각 고객별로 노란색으로 표시한 ’행동 데이터 수집 기간’과 주황색으로 표시한 ‘상호작용 데이터 수집 기간’이 있는데요, 모델 학습을 위해서는 이 둘은 항상 꼭 쌍으로 붙어다닙니다. 이 때, 고객의 행동 데이터를 수집하는 기간과 고객이 상품과 서비스와 상호작용(예시: 구매)한 것을 수집하는 기간이 나뉘어있다는 부분이 매우 중요합니다. 일반적으로, 추천에서 상품과 서비스는 ‘아이템’이라고 하며, 고객과 아이템의 상호작용은 고객이 아이템을 구매하거나, 클릭하거나, 장바구니에 담는 모든 행위가 포함될 수 있습니다. 하지만, 이 글에서는 독자분들의 이해를 편하게 하기 위해서 “상호작용=구매”로 한정지어서 말씀드리겠습니다. 이와 같이 두 종류의 데이터 수집 기간을 분리함으로써, 아이템을 구매하는 고객이 구매 이전에 어떤 행동 패턴을 보이는지 추천 모델이 학습할 수 있게 됩니다.
행동 데이터와 상호작용 데이터라고 구분하여 두 개가 다르다고 생각이 드실 수도 있는데요, 사실 이 두 개는 같은 형태의 데이터입니다. 예시로 설명드리겠습니다. 넷플릭스나 유튜브와 같은 영상 스트리밍 서비스에서는 고객이 어떤 영상을 몇 분동안 살펴봤는지, 언제 출시한 영상을 봤는지, 어떤 영상에 ‘좋아요’를 남겼는지에 대한 정보를 얻을 수 있습니다. 주로 저녁에 영상을 보며, 최근에 출시한 영상을 주로 찾아보는 유저가 있다고 가정해보겠습니다. 해당 고객은 행동 데이터 수집 기간에 다음과 같은 데이터를 수집하게 됩니다.
- 20xx년 x월 9일 오후 8시에 A 영상을 30분동안 봤다.
- 20xx년 x월 10일 오후 8시에 B 영상을 40분동안 봤다.
- 20xx년 x월 10일 오후 9시에 C 영상을 20분동안 봤다.
그리고 상호작용 데이터 수집기간에도 이와 유사하게 ‘20xx년 x월 12일 오후 8시에 D 영상을 30분동안 봤다.'와 같은 데이터가 수집됩니다. 행동 데이터와 상호작용 데이터의 차이는 수집 시점과 사용하는 데이터라고 볼 수 있습니다. 추천 모델은 행동 데이터에서 수집한 데이터를 거의 전부다 활용하고, 상호작용 데이터에서는 '어떤 유저가 D 영상을 봤다’는 상호작용에 초점을 맞춥니다. 이를 통해서 추천 모델은 고객의 행동 데이터 패턴으로 다음에 소비할 아이템들의 구매(=시청) 여부를 학습하여, 추천을 통해 고객이 놓칠 수도 있는 아이템을 리마인드 시켜줍니다.
많은 서비스들이 고객들에게 추천을 더 잘하기 위해서 행동 데이터를 더 많이 수집하고 있습니다. 하지만, 레거시(legacy) 등으로 인하여 행동 데이터를 수집하기 어려운 경우에는 고객의 식별자(id)만을 이용하기도 합니다. 행동 데이터가 많이 수집된다고 항상 좋은 것은 아닙니다. 앞서 말씀드린 것처럼 추천 모델이 자동으로 구매 이전의 행동 패턴을 학습하지만, 너무 많은 데이터는 주요한 행동 패턴 탐지를 방해하기도 합니다. 따라서, 추천 모델의 학습 과정에 필요한 행동 데이터만을 선별하여 입력하는 것이 중요합니다. 이를 피처 엔지니어링(feature engineering)이라고 부르며, 좋은 입력 데이터를 발굴하기 위해 많은 분들이 현업에서 피처 엔지니어링에 힘써주고 계십니다. 하지만, 이 글에서는 모델을 중점적으로 다룰 예정이기에, 피처 엔지니어링이 중요하다고만 언급하고 본론으로 넘어가겠습니다.
추천 모델 연구 동향
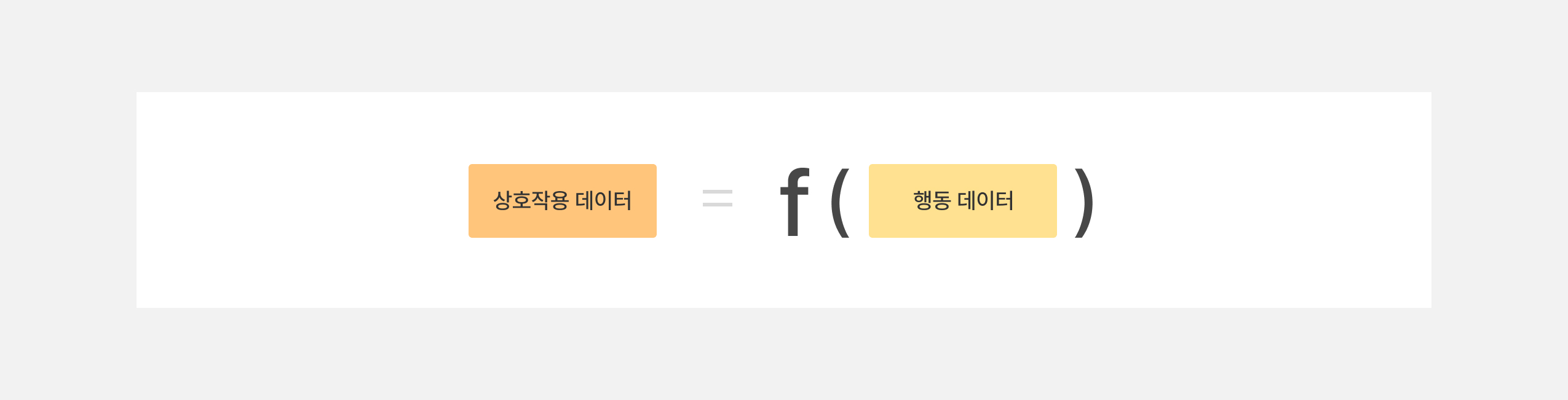
위와 같은 데이터로부터 추천 모델을 학습한다는 것은 아래 수식이 잘 맞는 함수 f를 찾는다는 것을 의미합니다. 앞으로 소개드리는 추천 모델 연구 동향은 아래 그림에서 f를 어떻게 설계했는지 달라졌다고 생각해주시면 됩니다. 추천 모델이 행동 데이터를 어떻게 사용하고 활용하고 있는지를 중점적으로 설명드리겠습니다.
1. 일반적인 추천 모델
협업 필터링 모델1
협업 필터링(CF)은 추천 시스템에서 널리 사용되는 추천 모델입니다. 이 방법은 “비슷한 사람은 비슷한 아이템을 좋아한다”는 단순한 아이디어에서 출발한 추천 기법입니다.
이런 협업 필터링에는 크게 세 가지 접근 방식이 있습니다. 하나는 사용자 기반(user-based) CF이고, 다른 하나는 아이템 기반(item-based) CF입니다. 마지막으로는 행렬 분해(matrix factorization)에 기반한 CF입니다. 사용자 기반 CF는 “나랑 비슷한 취향을 가진 사람은 뭘 좋아했을까?”를 찾아보는 방식입니다. 예를 들어, 내가 A, B 영화를 좋아했는데, 나랑 비슷한 고객은 A, B, 그리고 C 영화를 좋아했다면, C 영화를 내게도 추천해주는 방식입니다. 아이템 기반 CF는 “내가 좋아한 영화랑 비슷한 영화는 뭐가 있을까?”라는 관점에서 접근합니다. 예를 들어, 영화 A를 본 많은 사람들이 영화 C, D도 함께 보았고, 내가 A 영화를 좋아한다면 C와 D 영화를 내게 추천해주는 거죠. 이 방식은 특히 아이템 수가 많고, 사용자 수가 변동이 심할 때(예시: 쇼핑몰이나 OTT 서비스)에 더 안정적으로 작동하는 경우가 많다고 합니다. 두 접근 방식 모두 원리는 비슷한데, ‘무엇을 중심으로 유사도를 계산하느냐’에 따라 나뉘는 거라고 생각하시면 됩니다. 사용자 기반 CF는 사용자를 중심으로, 아이템 기반 CF는 아이템을 중심으로 유사도를 계산하는 것이죠. 실제 서비스에서는 이 두 방법을 섞어서 쓰거나, 상황에 맞게 선택하기도 합니다. 각 방식마다 장단점이 있어서, 서비스 특성과 데이터 구조에 따라 어떤 방식이 더 잘 맞는지가 달라지기 때문에 실제 적용을 위해서는 서비스에 대한 많은 이해가 필요합니다.
행렬 분해 기반의 CF 모델은 사용자와 아이템 사이의 유사도를 직접 측정하도록 합니다. 이를 위해 행렬 분해 기반 CF는 사용자와 아이템을 임의의 벡터 공간으로 매핑시키고, 사용자 벡터와 아이템 벡터 사이의 내적을 통해 유사도를 측정합니다. 아래 그림은 행렬 분해를 통한 CF 모델이 어떻게 작동하는지를 보여줍니다. 먼저, 가장 왼쪽은 사용자-아이템 행렬을 나타내고 있습니다. 사용자-아이템 행렬에서 행(row)은 사용자, 열(column)은 아이템으로 합니다. 그리고 각 행렬의 값을 상호작용 값으로 채워넣습니다. 상호작용은 앞서 말씀드린 것처럼 사용자의 아이템 구매 여부, 클릭 횟수 등이 될 수 있습니다. 이 때, 만약 사용자와 아이템 사이에 상호작용이 없다면, 그림에서 보이는 것처럼 행렬 값은 빈 값으로 둡니다.
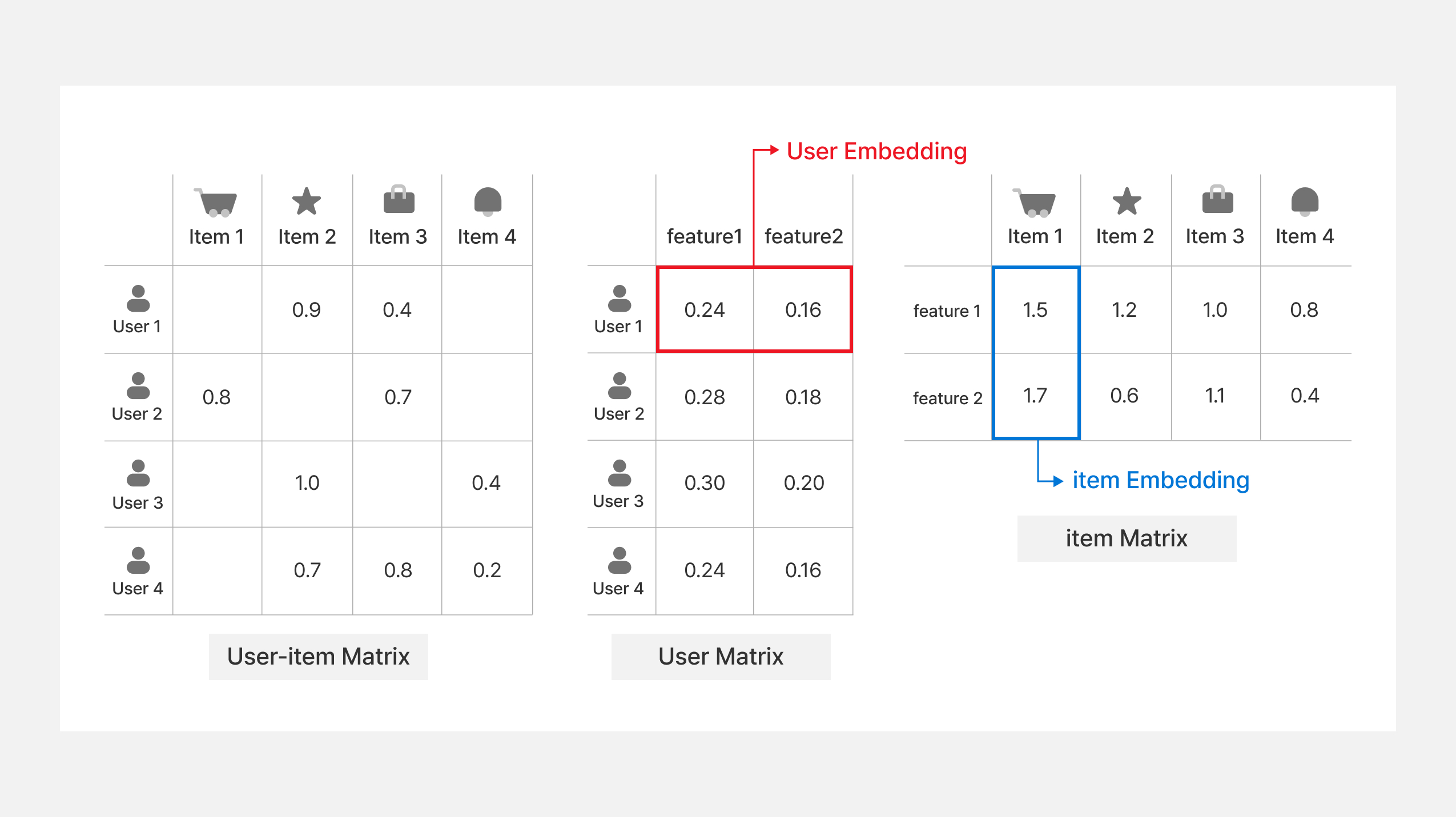
행렬 분해에 기반한 CF는 사용자-아이템 행렬을 그림의 오른쪽에 있는 사용자 행렬과 아이템 행렬로 분해합니다. 위 그림에서는 사용자와 아이템을 두 개의 차원을 갖도록 행렬 분해를 하고 있는 것을 나타내고 있습니다. 이 때, 유저 1은 어떤 임의의 공간의 (0.24, 0.16)이라는 벡터 값을 갖도록 분해가 되었는데, 이를 사용자 임베딩(user embedding)이라고 칭합니다. 유저와 마찬가지로, 아이템 1은 어떤 임의의 공간의 (1.5, 1.7)이라는 벡터 값을 갖도록 분해가 되었는데, 이는 아이템 임베딩(item embedding)이라고 합니다. 이런 사용자와 아이템 임베딩으로 분해를 할 때는 아래 수식을 만족하도록 합니다.
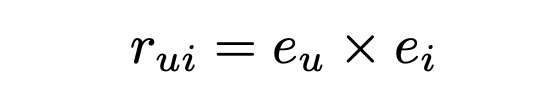

위 수식에서도 볼 수 있는 CF 모델의 매우 중요한 특징은 고객과 아이템의 내용 자체가 어떤지는 몰라도 상관없다는 점입니다. 다시 말하면, CF 계열의 모델은 위 데이터 부분에서 서술했던 고객의 행동 데이터는 사용하지 않습니다. 오직 사람들의 상호작용 패턴만을 가지고도 꽤 괜찮은 추천이 가능합니다. 이러한 특징 덕분에 저희가 고객이나 아이템에 대한 설명 정보가 부족할 때도 유용하게 쓸 수 있습니다. 사람들이 실제로 뭘 좋아했는지를 기반으로 하기 때문에, 추천 결과가 자연스럽고 믿을 만한 경우가 많습니다. 즉, 추천 모델이 고객과 아이템이 어떤 정보를 담고 있는지 이해하지 않아도 사람들 사이의 취향 관계만 잘 파악하면 충분히 괜찮은 추천이 됩니다.
하지만 이 CF 모델도 완벽하지는 않습니다. 예를 들어, 처음 온 신규 고객은 아직 아무런 상호작용 데이터가 없기 때문에, 어떤 아이템을 추천해야 할지 알 수 없는 콜드 스타트 문제가 생기게 됩니다. 게다가 사용자-아이템 행렬을 보면 대부분 비어 있는 희소성 문제로 인하여, 유사도를 정확히 계산하기 어려워 추천 품질이 떨어지기도 합니다. 또 하나, 자주 클릭되거나 많이 본 인기 아이템 위주로만 추천이 쏠리는 인기 편향 문제도 발생할 수 있습니다. 그래도 이런 한계에도 불구하고, 협업 필터링은 오늘날 많은 추천 시스템의 기본 뼈대 역할을 하고 있습니다. 심지어 딥러닝 기반 최신 모델들도 이 아이디어를 변형해서 쓰고 있습니다. 처음 시작한 아이디어는 단순하지만, 여전히 강력한 방식입니다.
Two-Tower 모델2

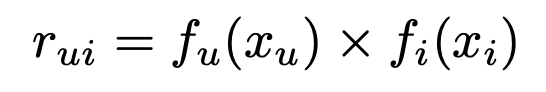

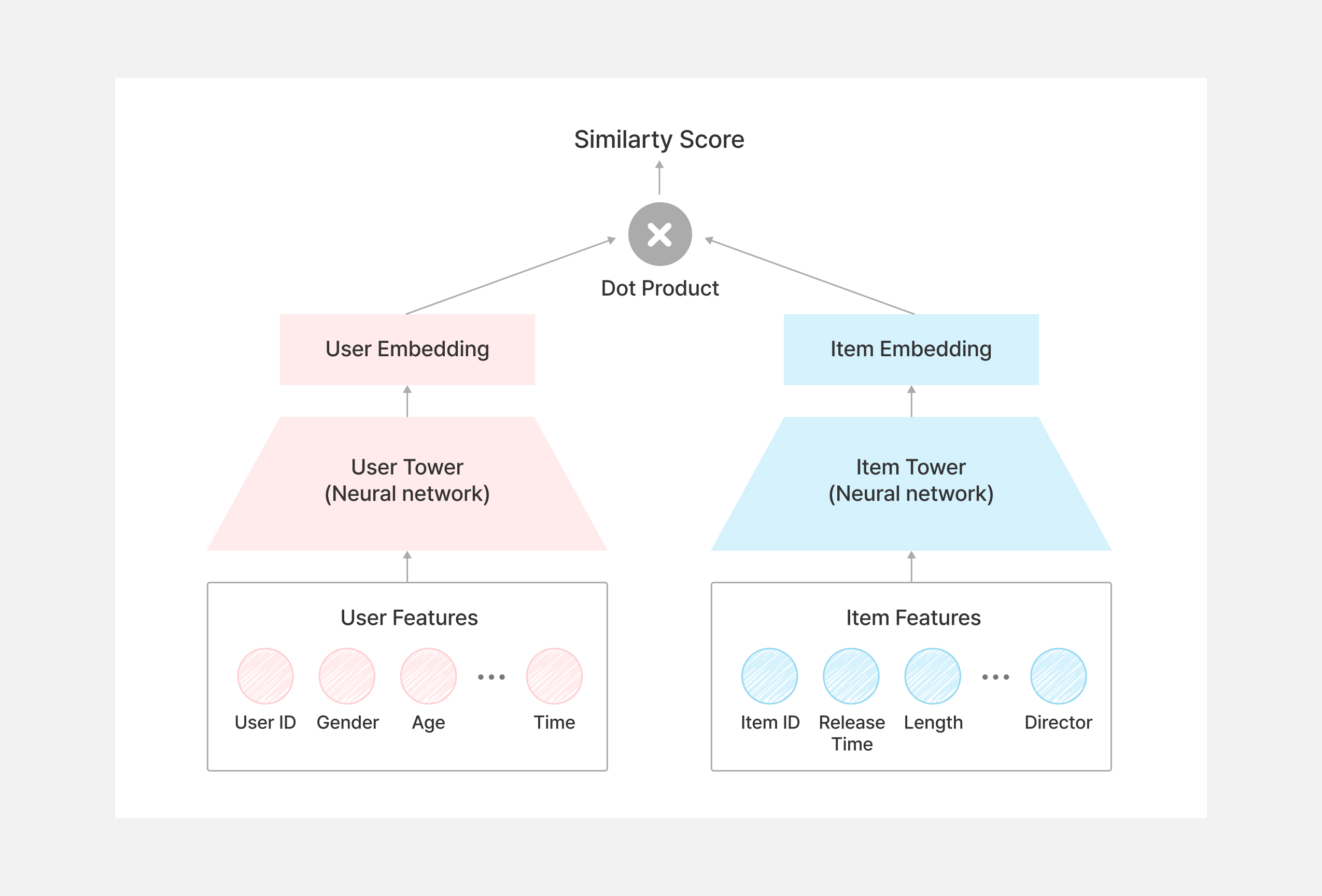
Two-Tower 모델과 MF 기반의 CF 모델과 가장 큰 차이점은 사용자와 아이템의 피처를 포함하고 있는지 유무입니다. Two-Tower 모델은 사용자와 아이템의 피처를 포함함으로써, 기존 모델의 단점을 완화시킵니다. 먼저, Two-Tower 모델은 콜드 스타트 문제를 완화시킬 수 있습니다. 앞서 설명드린 것처럼 Two-Tower 모델은 상호작용 데이터 외에 사용자 프로필과 아이템 설명 등의 부가적인 피처 정보를 선호도 예측에 활용하고 있습니다. 따라서, 상호작용 데이터가 없더라도 부가적인 피처 정보만으로도 사용자와 아이템의 벡터를 생성할 수 있습니다. 결과적으로, 상호작용 데이터가 부족한 콜드 스타트 상황에서도 추천 모델이 새로운 사용자나 아이템을 추천에 활용할 수 있게 됩니다. 다음으로 Two-Tower 모델은 희소성 문제를 완화시킬 수 있습니다. 사용자-아이템 행렬이 비어있는 경우에는, 평가한 아이템이 거의 없는 사용자들 간의 비교가 매우 부정확해질 수 밖에 없습니다. 하지만, Two-Tower 모델은 이런 한계를 표현 학습 기반의 방식으로 풀어냅니다. 사용자와 아이템은 각각의 인코더(Tower)를 통해 임베딩 공간에서 벡터로 표현되며, 이 벡터들 사이의 유사도를 기반으로 추천이 이루어집니다. 행렬에서 직접 유사도를 계산하지 않고, 임베딩 공간에서 계산을 하기 때문에 희소한 상호작용만으로도 효과적으로 추천 모델을 학습할 수 있습니다. 게다가 다양한 피처 정보를 인코더에 포함시킬 수 있어, 데이터가 희소하더라도 모델이 더 풍부한 의미를 학습할 수 있게 됩니다.
이렇게 기존 모델의 단점을 극복하는 것 이외에도 Two-Tower 모델만의 장점이 있습니다. Two-Tower 모델의 가장 큰 강점 중 하나는 대규모 시스템 환경에서도 효율적으로 확장 가능하다는 점입니다. 이 구조에서는 사용자 타워와 아이템 타워가 각각 독립적으로 임베딩을 생성하기 때문에, 아이템 임베딩은 사전에 미리 계산해두고 저장해둘 수 있습니다. 이렇게 하면 실시간으로 사용자에게 추천을 해야할 때, 사용자 임베딩만 계산한 뒤 미리 생성해둔 수백만 개의 아이템 벡터와 근사 최근접 탐색(approximate nearest neighbor)을 통해 빠르게 유사도를 비교하고 아이템을 추천할 수 있죠. 덕분에 대규모 데이터셋에서도 높은 효율성과 응답 속도를 유지할 수 있어, Two-Tower 모델은 실시간 개인화 추천 시스템의 핵심 기술로 널리 사용되고 있습니다. 하지만 더 정밀한 순위 예측이 필요한 경우에는 re-ranking 단계나 다른 ranking 모델이 별도로 필요합니다. Two-Tower 모델은 추천 시에 사용자 임베딩과 아이템 임베딩의 유사도를 계산해 가장 가까운 아이템을 찾는 방식입니다. 이 구조는 효율적이지만, 정교한 ranking에는 한계가 있기 때문입니다.
장점이 많은 Two-Tower 모델이지만, 단점도 존재합니다. 바로, 사용자와 아이템 피처를 하나씩 모두 신경써가며 정의해야 한다는 점입니다. 앞선 예시에서와 같이 영화에 대한 피처를 만드는 경우를 생각해보죠. 가장 먼저, 감독, 영화배우, 장르, 개봉일, 러닝 타임, 영화 등급, 배급사 등을 피처로 사용할 수 있을 것 같습니다. 하지만, 영화에 많은 정보를 담고 있는 시놉시스는 어떻게 해야할까요? 고객을 유치하기 위해 영화 제작진이 정성껏 쓴 시놉시스를 Two-Tower 모델에 넣을 때 피처를 일일이 직접 정의해가는 것은 많은 시간이 소요되는 일입니다. 따라서, 다양한 형태의 피처를 효과적으로 활용하려면 텍스트와 같은 비정형 데이터를 처리할 수 있는 인코딩 전략이나, 이를 다룰 수 있는 설계도 함께 고민되어야 합니다.
2. LLM과 추천 모델
2.1. LLM을 추천 모델로 활용3
생성형 AI(artificial intelligence)의 눈부신 발전으로 인하여, ChatGPT나 Gemini와 같은 LLM은 하루가 멀다하고 점점 더 많이 똑똑해지고 있습니다. 이와 같이 똑똑해지는 LLM은 많은 사전 지식을 내포하고 있습니다. 예를 들어, 엄청 최신 영화가 아니라면 영화 제목만으로도 LLM은 감독, 배우 등을 알고 있습니다. (물론 거짓말일 수도 있지만요.) 이러한 특징으로 인해서 LLM을 활용하여 추천을 수행한 연구들이 있습니다. LLM에 사용자 정보와 아이템 정보를 입력했을 때, 우리가 원하는 아이템을 추천하거나 추천 아이템에 대한 설명을 출력하는 형태입니다. 문자 그대로 LLM 자체를 추천 모델로 활용하는 것입니다.
아래 그림은 LLM을 추천 모델로 활용하는 구조를 나타냅니다. LLM을 추천 모델로 사용하기 위해서는 가장 먼저 기존의 사용자와 아이템 정보를 프롬프트 지시문 양식에 맞도록 변경합니다. 프롬프트 지시문에는 LLM에게 추천 모델로써 행동하는 지시문을 포함하고 있으며, 사용자 피처 정보, 그리고 추천에 사용할 아이템 피처 정보를 양식에 맞게 입력합니다. 아이템과 관련해서는, 앞서 설명드린 Two-Tower 모델 구조와 달리, 아래 그림처럼 추천에 사용할 모든 후보 아이템에 대한 정보를 모두 입력해야 합니다. 이렇게 프롬프트 지시문이 최종적으로 완성되면, LLM에게 해당 지시문을 전달하여 해당 사용자가 어떤 아이템을 좋아하는지 답변을 생성하도록 합니다. 이처럼 LLM은 LLM 자체가 지닌 다양한 도메인에 대한 지식에 기반하여 추천 모델 설계자가 입력한 프롬프트 지시문을 따라 사용자에게 적합한 아이템을 잘 추천해줄 수 있고, 또한 LLM을 추가로 학습(fine-tuning)하여 추천 성능을 개선시키기도 합니다.
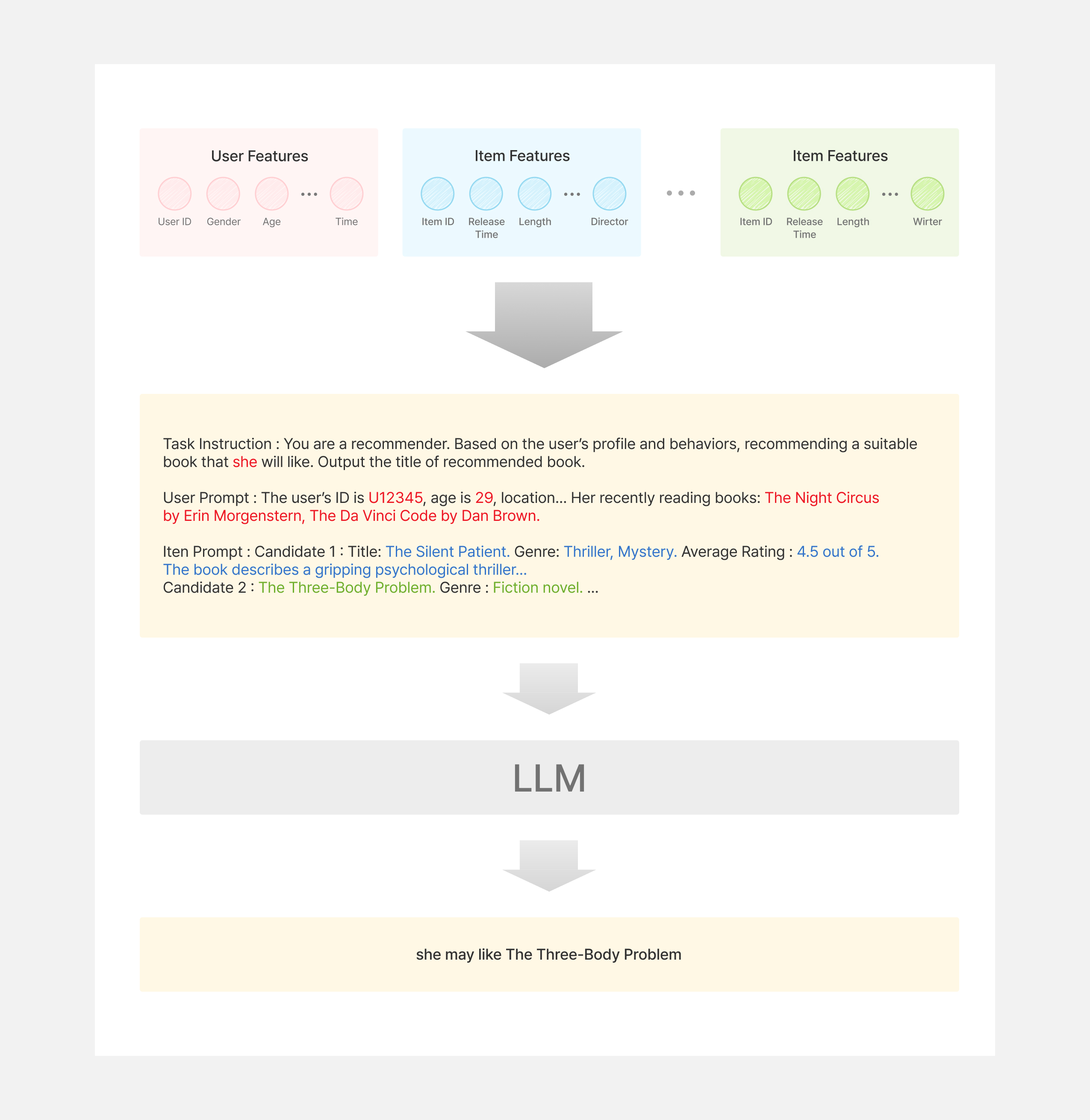
하지만, LLM 자체가 추천 모델로 활용되는 경우, 비용이 비싸고 계산 시간이 오래걸린다는 매우 치명적인 단점이 있습니다. LLM은 크고 복잡한 모델입니다. 따라서 일반적인 CF나 Two-Tower 모델과 비교했을 때 응답 시간(latency)이 훨씬 길고, 운영 비용도 매우 높습니다. 실시간 추천이 필요한 서비스에서는 이런 속도 문제 때문에 LLM을 추천 모델로 활용하는 것이 제한적입니다. 이러한 치명적인 단점으로 인하여, 최근에는 LLM을 추천 모델로 활용하는 것보다, LLM을 추천 모델의 성능 향상에 활용하고 있습니다.
2.2. LLM을 추천 모델 성능 향상에 활용4
LLM을 활용하여 추천 모델의 성능 향상에 활용되는 방법은 크게 두 가지 방향이 있습니다. 각 방향에 대해서는 후술하고, 먼저 LLM을 활용한 추천이 어떻게 구성되는지 그림을 통해 설명 드리겠습니다. 아래 그림에서 노란색 상자는 사용자와 아이템 데이터의 상호작용 데이터를 나타내고, 초록색 상자는 추천 모델, 그리고 검정색 상자는 LLM을 나타냅니다. 앞서 설명드린 추천 모델들의 경우는 노란색 상자에 속한 데이터 만을 활용하여 추천 모델을 학습하고 고객들에게 서비스를 제공합니다. LLM을 활용하여 추천 모델의 성능을 향상시키는 방법으로는, 빨간색 화살표처럼 사용자와 아이템 정보를 추가로 생성하거나, 파란색 점선 화살표처럼 상호작용 데이터를 추가로 생성하여 노란색 상자에 속한 데이터를 더 풍부하게 만든 다음에 추천 모델에 풍성해진 정보를 입력하는 방식으로 구성됩니다. 이렇게 추가로 데이터를 생성하여 활용하는 방법은 사용자와 아이템에 대해서 LLM으로 한 번 추론하여 미리 저장해둘 수 있기 때문에, 기존에 비용이 비싸고 계산 시간이 오래걸린다는 단점을 극복할 수 있습니다.
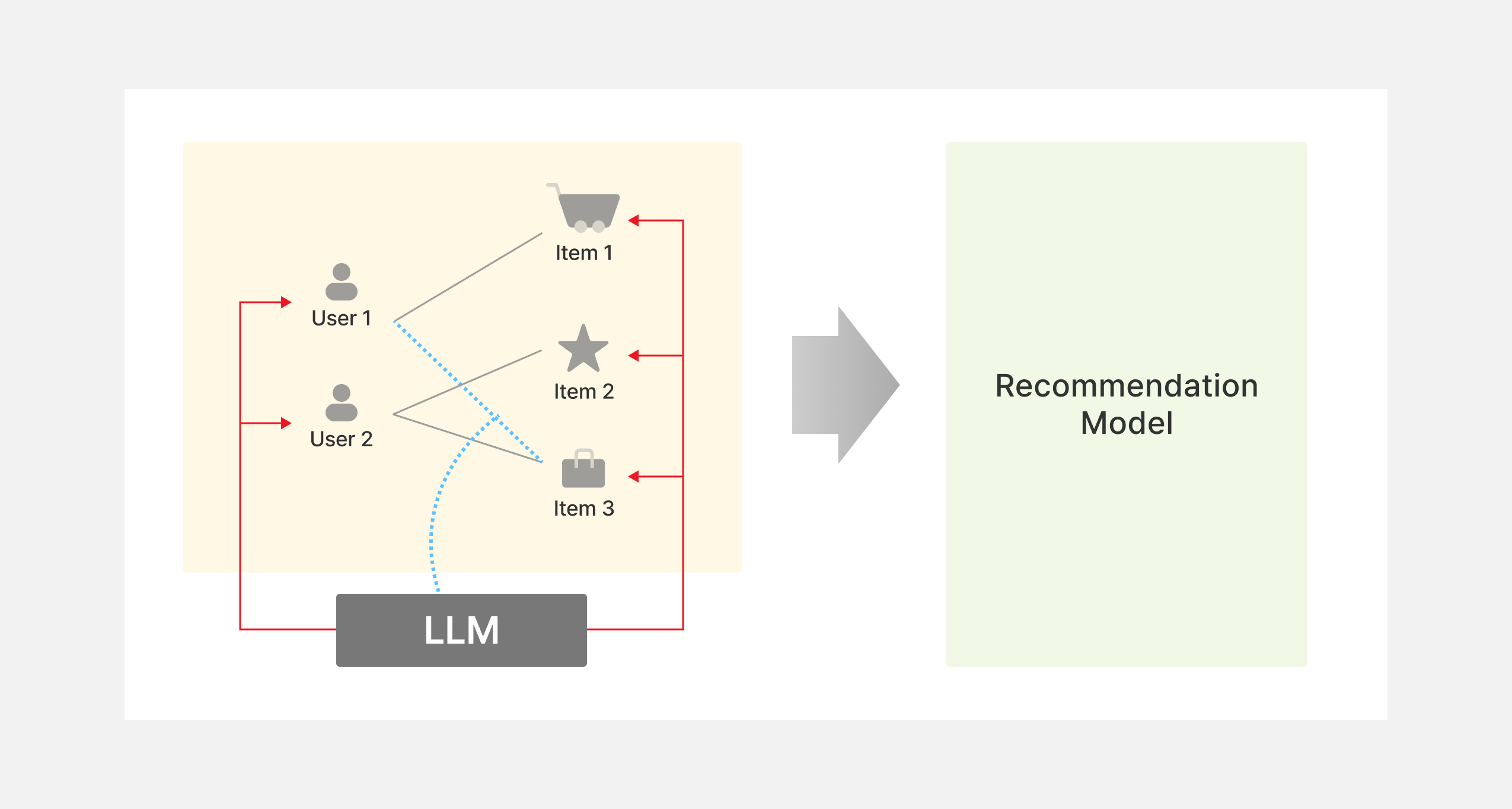
이제 활용되는 방향에 대해서 소개드리겠습니다. 첫 번째 방향은 위 그림의 빨간색 화살표로 표시된 부분입니다. 이는 지식 향상(knowledge enhancement)을 통해 성능 향상을 꾀하는 방향입니다. LLM은 내재적으로 가지고 있는 다양한 도메인에 대한 지식에 기반하여 새로운 지식을 생성할 수 있습니다. 이에 따라, 사용자와 아이템에 대한 텍스트 정보에 기반하여 저희가 수집하기 어렵지만 추천에 도움이 되는 정보를 LLM은 추론할 수 있습니다. 더 구체적으로, 지식 향상은 아래 그림과 같은 절차를 통해서 이루어집니다. 먼저, 아이템(또는 사용자) 피처를 정해진 프롬프트 지시문에 맞게 내용을 입력합니다. 프롬프트 지시문에는 아이템에 대한 요약 정보를 생성하는 등의 문장을 생성하도록 하는 내용이 포함되어 있습니다. 이렇게 완성된 지시문을 LLM에 입력하여 아이템과 관련된 문장을 생성합니다. 생성된 문장을 텍스트 인코더에 넣어서 아이템과 관련한 주요한 피처를 생성합니다.
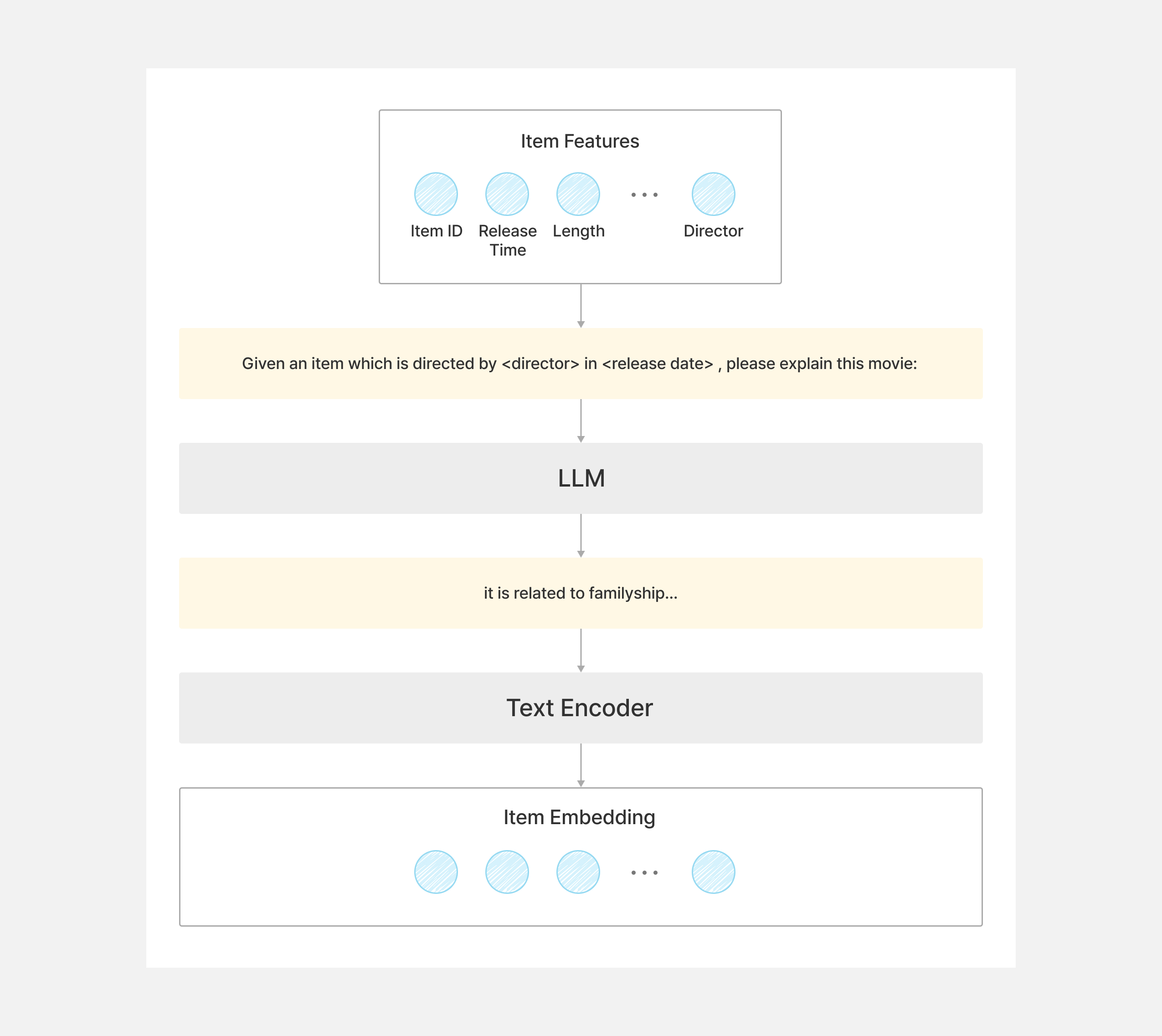
두 번째 방향은 위 그림의 파란색 점선 화살표로 표시된 부분입니다. 이는 상호작용 향상(interaction enhancement)을 통해 추천 모델의 성능 향상을 도모하는 방향입니다. 앞서 설명드린 것처럼 LLM의 지식에 기반하여 사용자와 아이템의 정보를 새롭게 생성할 수도 있지만, 상호작용도 새롭게 생성할 수 있습니다. 이 때는, 1) 사용자와 아이템이 기존에 상호작용한 데이터와 새로운 후보 아이템 데이터를 입력하거나, 2) 상호작용 데이터 샘플을 입력하여 LLM이 새로운 상호작용 데이터를 생성하도록 합니다. 이렇게 생성된 상호작용 데이터를 추천 모델 학습에 사용하면 성능을 향상시킬 수 있다고 합니다.
이처럼, 실제 서비스에서는 LLM을 추천 모델로 활용하기보다는, 추천에 필요한 피처나 데이터를 생성하도록 하고 있습니다. 이렇게 활용하는 것이 비용 뿐만 아니라 고객이 추천받기까지 기다리는 시간을 줄여줄 수 있기 때문입니다. LLM을 이용하여 추천 모델에 사용할 피처를 생성하는 것은 단순하게 단어 자체를 피처로 사용하는 것보다 글을 통해 맥락을 이해한 피처를 생성했기 때문에 더 좋은 추천 모델을 학습할 수 있습니다.
맺음말
이 글에서는 추천 시스템의 다양한 고려 요소들 중에서 추천 모델이 어떤 흐름으로 연구되고 있는지 설명드렸습니다. 사실, 추천 모델은 이 글에서 소개드린 것보다 훨씬 더 다양한 모델이 연구되고 있으며, 실제 서비스에 적용되고 있습니다. 다양한 추천 모델이 적용되는 것은 각 추천 모델은 장단점이 있기 때문인데요, 넷플릭스나 유튜브에서도 다양한 추천 모델이 적용되어 있습니다. KT는 고객이 필요한 상품을 놓치지 않기 위해 다양한 추천 모델을 적재적소에 배치하고 있습니다. 다양한 모델을 탐색하는 것에서 더 나아가서, 추천 모델 성능 향상을 위해 적합한 피처를 발굴하기 위한 업무도 지속하고 있으니, 앞으로 KT의 개인화 추천 여정에도 많은 관심과 응원을 부탁드리겠습니다.
참고문헌
- Su, X., & Khoshgoftaar, T. M. (2009). A survey of collaborative filtering techniques. Advances in artificial intelligence, 2009(1), 421425.
- Huang, P. S., He, X., Gao, J., Deng, L., Acero, A., & Heck, L. (2013). Learning deep structured semantic models for web search using clickthrough data. In Proceedings of the 22nd ACM international conference on Information & Knowledge Management.
- Wu, L., Zheng, Z., Qiu, Z., Wang, H., Gu, H., Shen, T., Qin, C., Zhu, C., Zhu, H., Liu, Q., Xiong, H., & Chen, E. (2024). A survey on large language models for recommendation. World Wide Web, 27(5), 60.
- Liu, Q., Zhao, X., Wang, Y., Wang, Y., Zhang, Z., Sun, Y., Li, X., Wang, M., Jia, P., Chen, C., Huang, W., & Tian, F. (2024). Large language model enhanced recommender systems: Taxonomy, trend, application and future. arXiv.