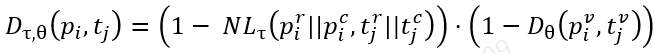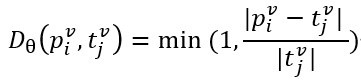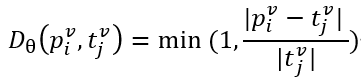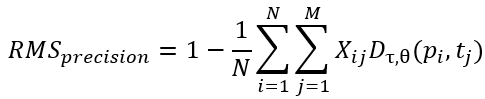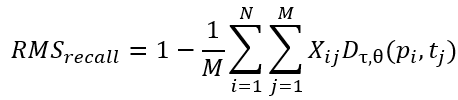안녕하세요. KT의 Document AI 모델 및 시스템 개발을 담당하는 Gen AI Lab 조직의 한연지(yeonjee.han)입니다. 저희 팀에서는 국내외 다양한 B2B/G 고객 문서(표, 차트, 그림이 포함된 비정형 문서)를 완벽에 가까운 디지털 데이터로 변환할 수 있도록 모델 및 시스템 중심의 개발을 진행하고 있습니다.
이번 글에서 HWPX, DOCX, XLSX 등 디지털 텍스트 문서(Searchable Document)부터 PDF, JPEG, PNG 등 검색이 불가능한(Non-searchable Document) 이미지 기반 문서를 분석하는 기술인 Document Parser, Docu-See를 소개합니다.
1. KT Document Parser, Docu-See란?
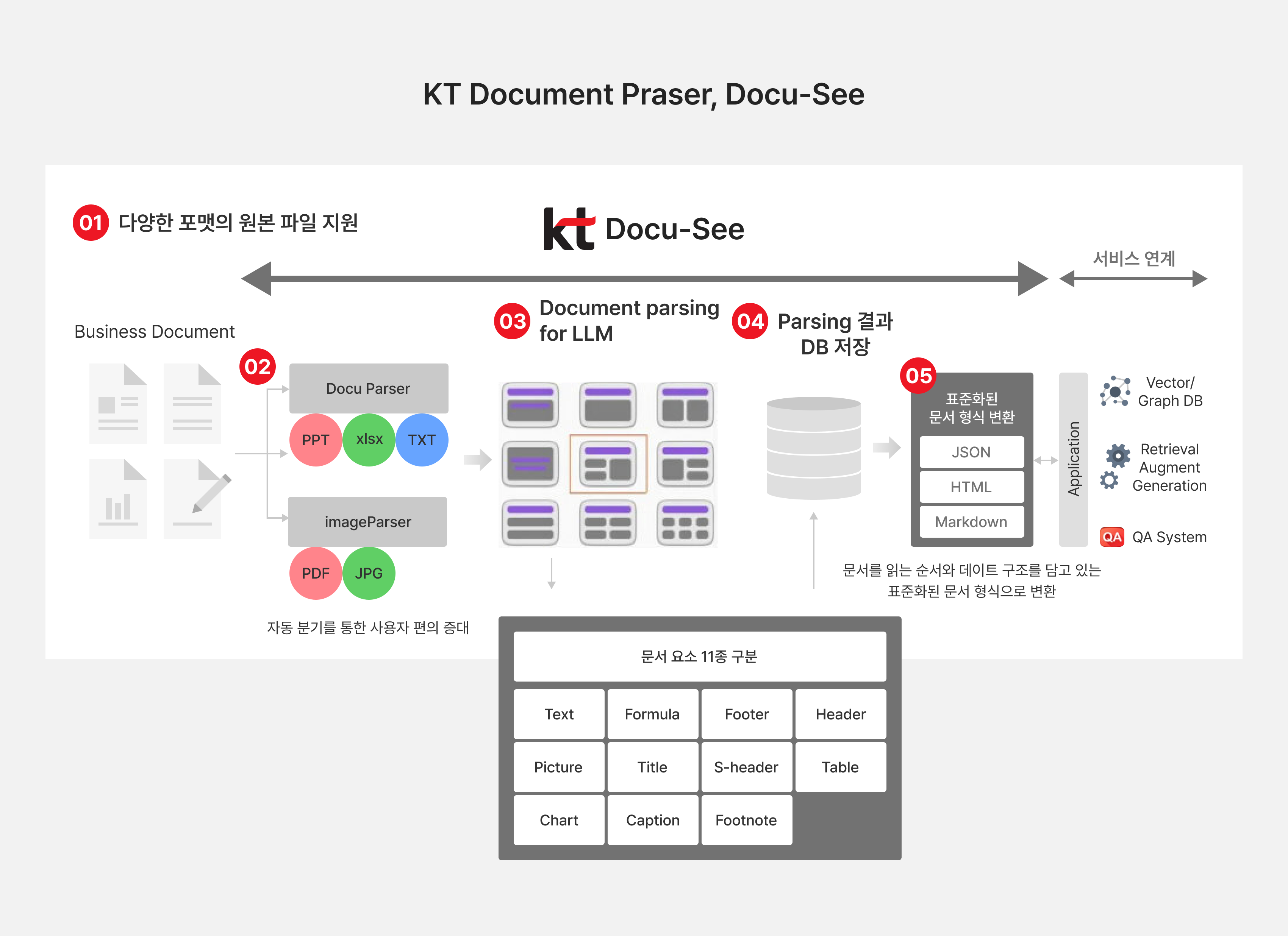
KT Docu-See는 문서 내 구조와 시각적 레이아웃 구조를 자동으로 분석하는 고도화된 AI Document Parser로, LLM(Large Language Model)과 RAG(Retrieval-Augmented Generation)기반 생성형 AI 시스템에 최적화된 입력 데이터를 제공하는 통합형 End-to-End 솔루션입니다.
특히 디자인이 다양한 한국형 문서, 스캔 문서, 금융 문서의 수식과 한자 등 디지털화가 까다로운 요소들을 효과적으로 처리할 수 있도록 설계되어, 복잡한 문서 환경에서도 정밀한 정보 추출이 가능합니다.
그림1. KT Docu-See 솔루션 전체 흐름도
KT Docu-See는 디지털 텍스트 문서를 처리하는 DocuParser 모듈과 이미지 문서를 처리하는 ImageParser를 병합(Merging)하는 기법으로 놓치는 문자 없이 디지털화 효율을 극대화하였습니다[그림 1].
또한, 문서 읽기 순서 모델, 표 구조 인식 모델, 차트 인식 모델을 포함하여 지금까지 쌓아온 노하우를 바탕으로 한국형 벤치마크 데이터셋을 제안하고 검증을 통해 단기간에 글로벌 경쟁력을 입증했습니다.
이번 글에서는 KT Docu-See 주요 기능에 대해 간단히 소개하고, Docu-See를 구성하는 모델 성능을 끌어올린 과정과 성능에 대한 자세한 정량 수치를 상세하게 설명 드리겠습니다.
1-1. KT Docu-See 주요 기능 및 특징
기존 문서 분석 기술들과 달리 KT 문서 Parser는 다양한 형태의 문서를 정확하고 일관성 있게 해석하는 데 중점을 둔 한국 특화 문서 분석 엔진입니다. 이는 LLM 기반 생성형 AI 시스템의 성능을 극대화하기 위한 핵심 전처리 단계로, 경쟁력 확보를 위해서는 문서의 내용을 정확하게 추출하는 것이 필수적입니다[표 1].
표1. 문서 분석 프로세스 및 입/출력 형식
KT Docu-See의 차별화 요소는 다음과 같습니다.
- 문서 레이아웃 구조 분석 기반 일관된 문서 읽기 순서 구성
→ 헤더·푸터·단 구분·열 위치 등을 고려해 LLM 입력 시 맥락 흐름 유지 가능
- 한글, 영어 외에도 한자, 수학 단위, 물리 단위 등 특수 기호 인식
→ 일반 OCR이 놓치는 정보를 정확히 복원, 기술 문서·금융 문서 등에서도 활용 가능
- 구분선이 없는 표나 병합 셀이 있는 복잡한 테이블 구조 인식
→ 시각적 구조에 의존하지 않고 의미 단위로 재구성하여 데이터 활용도 증대
- 막대그래프, 선그래프 등 시각자료를 구조화 데이터로 변환
→ 그래픽 요소도 텍스트/수치 정보로 변환되어 LLM의 reasoning 기반 질의 가능
- 문단 내 계층 구조, 목록(Bullet), 강조 스타일 등 문서 서식 인식
→ 문서의 논리적 흐름 보존 및 요약·질의응답 정확도 향상
- 스캔 문서와 디지털 문서 모두 지원 (Hybrid 문서 처리)
→ 다양한 문서 환경에 대해 포맷 제약 없이 통합 처리 가능
이러한 Docu-See의 차별화된 문서 분석 기술은 문서의 구조적·논리적 의미를 보존하며 AI가 이해할 수 있는 형태로 변환함으로써, 정확한 정보 추출과 문서 기반 질의응답 시스템의 신뢰도 향상에 핵심적인 역할을 합니다.
이는 곧, LLM 기반 서비스에서 정보 왜곡 없이 정확한 응답을 생성하는 기반이 되며, 기업 내 문서 자동화 및 AI 문서 검색 정확도를 획기적으로 향상시킬 수 있는 요소입니다.
2. KT Docu-See 내 AI 모델 구성
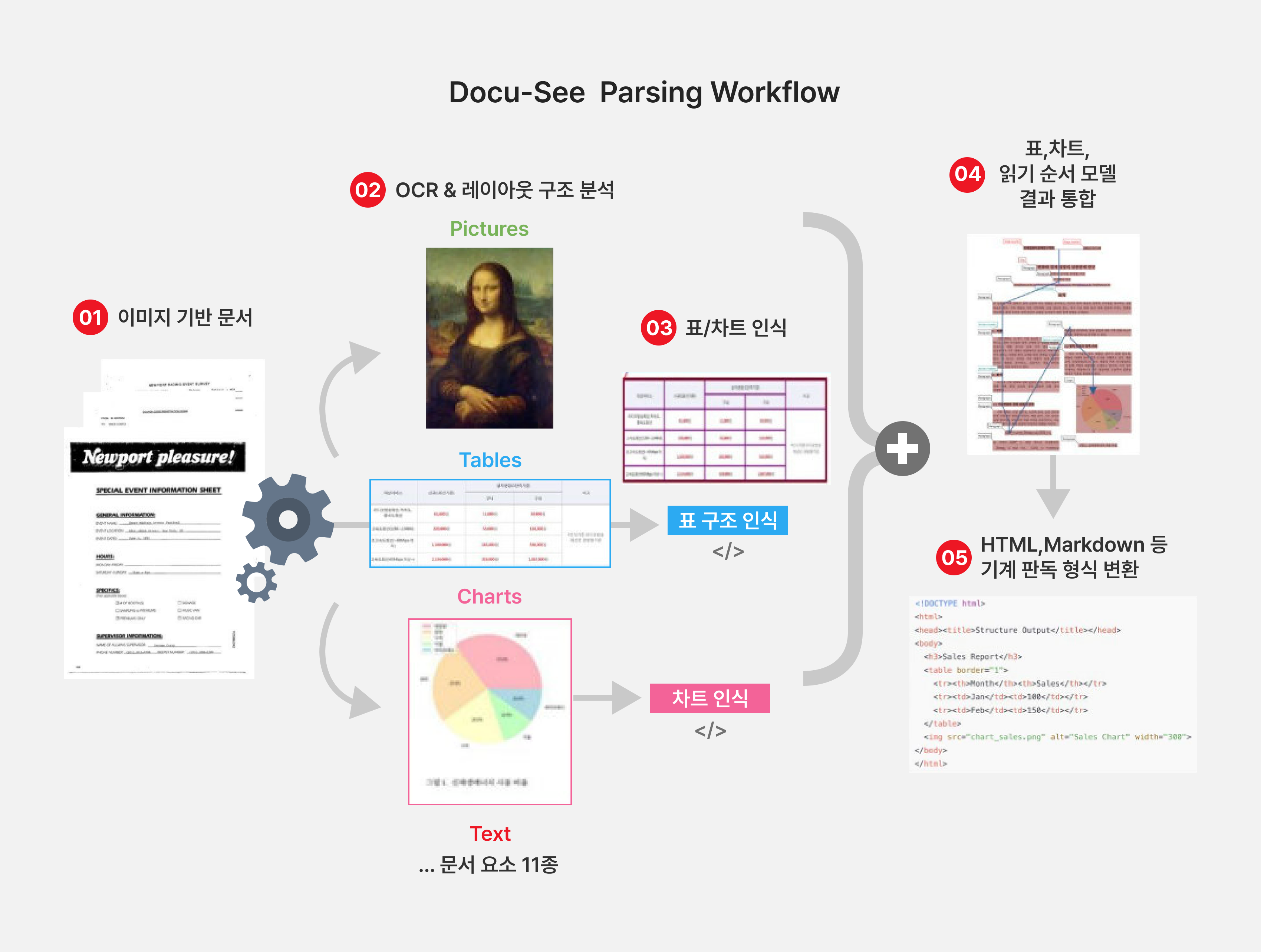
그림2. KT Docu-See Parsing 과정 상세 흐름도
KT Docu-See는 문서의 비정형 데이터를 정형 정보로 변환하기 위해 여러 AI 기반 처리 모듈로 구성되어 있습니다. 이러한 모듈들은 각기 다른 형태의 문서 요소—텍스트, 구조, 표, 시각 자료 등—를 분석하고 이해하는 역할을 수행하며[그림 2], LLM 및 검색 시스템에서의 활용을 전제로 최적화된 전처리 파이프라인을 제공합니다.
2-1. OCR: 문서 이미지 내 텍스트 검출 및 인식
KT OCR은 이미지 문서 내의 문자 위치, 폰트, 글자 크기, 언어 등 다양한 요소를 이해하며 한국 문서의 특징인 스캔 문서, 디자인 문서 등 다양한 스타일의 문서에서 Machine readable 형태로 텍스트 추출이 가능합니다[표 2].
표2. 스캔 문서 및 디자인 문서 OCR 결과 예시
한국형 문서가 어떻기에 문자인식을 잘한다고 할 수 있을까? — KT OCR 모델 전략
한국 문서에는 저해상도 스캔과 오래되어 흐릿한 문자가 많을 뿐만 아니라 영어 외 한자와 한글이 혼용되는 등 다수의 외국어와 함께 필기체도 자주 등장합니다. 이와 같이 다양한 케이스에 디자인 요소까지 더해져 문자 인식의 난이도가 상당히 높은 상태에서 강건하게 문자를 인식할 수 있도록 KT OCR은 단일 모델로 한글, 영어는 물론 한국 문서에서 한글과 혼용되어 자주 등장하는 한자, 수학적·물리적 단위(Σ, ㎡ 등), 특수문자까지 폭넓게 인식할 수 있습니다.
이와 같이 KT OCR 모델만의 강점을 통해 문서 내의 비정형 텍스트 데이터를 더욱 효과적으로 디지털화할 수 있으며, 정확한 문자 인식은 RAG와 LLM 기반 추론의 신뢰도에 직결되므로, 문서 파싱과 데이터 처리의 핵심적인 역할을 수행합니다.
2-2. 레이아웃: 문서 시각적 배치 분석 및 읽기 순서 분석
레이아웃 분석(Layout Analysis)은 문서 내의 다양한 시각적 요소들을 구분하고 구조화하는 기술입니다. 텍스트, 표, 이미지, 제목 등 각 구성 요소를 정확히 식별하여 문서 전체의 시각적 구조를 파악합니다. 이를 통해 테이블 구조 인식, 차트 인식 등 후속 작업의 정확도를 크게 향상시킬 수 있습니다.
KT 레이아웃 분석 모델 전략
KT는 행정문서, 보도자료, 공공정책 보고서 등 다양한 문서 유형을 분석하여 한국 문서에서 자주 등장하는 구성 요소들을 파악했습니다. 이를 바탕으로 일관된 레이아웃 분석을 위해 11개의 클래스를 정의하였으며, 정의된 클래스는 다음과 같습니다.
표3. 문서 레이아웃 구조 분석에 사용되는 11개 클래스 목록
위와 같이 레이아웃 분석 요소를 11개로 설계하였을 때, 시각적으로 나누기 모호한 레이아웃을 일관되게 분석할 수 있었습니다.
레이아웃 분석과 함께 LLM에 품질 높은 데이터를 제공하기 위해 읽기 순서(Reading Order) 모델도 개발하였습니다. Reading Order는 레이아웃 분석 결과로 얻어진 요소들을 사용자가 자연스럽게 읽는 순서대로 재배열하는 기술입니다.
한국어 문서는 다단 구성, 표와 본문의 혼합 배치, 캡션과 이미지의 다양한 배치 등 복잡한 구조를 가지고 있습니다. 따라서 읽기 순서의 자동화는 문서 이해에 매우 중요하며, 정확한 읽기 순서는 RAG나 LLM 성능 향상을 위한 핵심 전처리 과정입니다.
이러한 일관된 레이아웃 분석과 Reading Order 모델을 통해 정확한 데이터 변환이 가능하며, 최종적으로 LLM에 고품질 데이터를 제공할 수 있습니다.
2-3. 표 구조 인식: 표 구조의 인식 및 셀 간 관계 이해
표 구조 인식은 셀의 경계, 병합 여부 등을 포함하며, 결과적으로 HTML Tag 또는 JSON 등의 형태로 변환합니다[표 4]. 이를 통해 문서 내 구조화된 데이터를 효과적으로 추출할 수 있으며, 복잡한 표 형태의 정보도 검색 가능한 형태로 변환하여 데이터 활용성을 극대화할 수 있습니다. 또한 원본 표의 시각적 구조와 의미를 보존하여 사용자가 직관적으로 이해할 수 있는 형태로 제공합니다.
표4. 원본 표 이미지에 대한 구조 인식 및 데이터 추출 시각화 예시
왜 KT 표 구조 인식 모델인가? — KT 표 구조 인식 모델 전략
KT에서 개발한 표 구조 인식 모델은 다양한 실문서 환경을 고려하여 설계되었습니다. 구분선이 없는 테이블이나 병합 셀이 포함된 복잡한 표 구조에서도 높은 인식 성능을 보여줍니다.
이러한 강점은 OCR 오류가 발생하거나 다양한 표 형태가 혼재된 문서에서도 안정적인 구조 추출을 가능하게 합니다. 따라서 실제 업무 문서의 전자화는 물론, LLM 기반 문서 질의응답 시스템에도 효과적으로 활용할 수 있습니다.
2-4. 차트 인식: 시각적 그래프 요소의 데이터 구조화
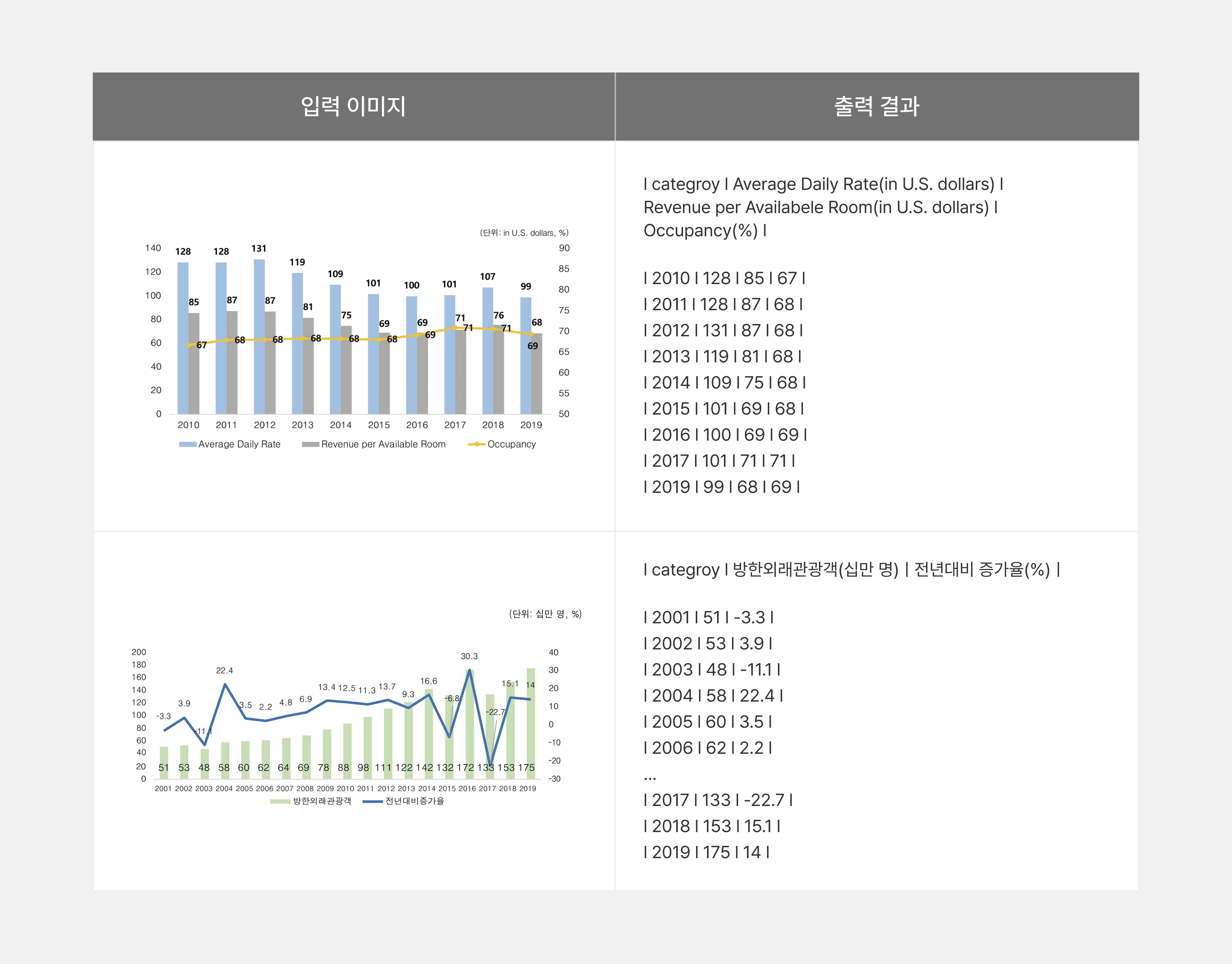
차트 인식은 문서 이미지 내에 포함된 다양한 형태의 차트(막대그래프, 선그래프 등)를 분석하여, 이를 기계가 읽을 수 있는 구조화된 형태로 변환하는 작업입니다. 차트 이미지를 HTML table 또는 Markdown table 형식으로 변환함으로써, 차트 안에 담긴 수치나 정보를 구조적으로 표현할 수 있도록 합니다. 이를 통해 차트 데이터를 다른 시스템과 연동하거나 후처리를 진행하기 용이한 형태로 제공할 수 있으며, 문서 전자화에도 활용할 수 있습니다.
KT 차트 인식 모델 전략
KT 차트 인식 모델은 다수의 범례나 다양한 디자인 요소가 포함된 복잡한 차트에서도 우수한 인식 성능을 보이며, 이미지 내에 포함된 단위 정보까지 함께 추론하는 강점이 있습니다[표 5].
표5. 차트 이미지에 대한 구조 인식 및 데이터 추출 결과 예시
위와 같은 각 구성 모델의 차별화된 강점을 통합한 결과, KT Docu-See 솔루션은 기존 대비 문서 처리 정확도를 크게 향상시켰습니다. 특히 한국어 특화 OCR, 11개 클래스 기반 레이아웃 분석, 지능형 읽기 순서 모델, 복잡한 표 구조 인식 및 차트 인식 기술의 시너지 효과로 다음과 같은 성과를 달성했습니다:
- 처리 범위 확대
: 기존에 처리가 어려웠던 복잡한 한국 문서(행정문서, 기술문서, 다단 구성 문서 등)까지 안정적으로 분석
- 품질 일관성 확보
: 문서 유형에 관계없이 일관된 고품질의 구조화된 데이터 추출
- LLM 성능 최적화
: 정확한 전처리를 통해 RAG 및 LLM 기반 시스템의 응답 신뢰도 대폭 향상
- 업무 효율성 증대
: 수작업으로 처리하던 복잡한 문서들의 자동화 처리로 업무 생산성 극대화
3. KT 통합문서변환 벤치마크
3-1. 추진배경
국내 기업 고객 대상 Tech Sales 과정에서 실제 문서 환경을 반영한 통합적 문서변환 AI의 성능 검증이 요구되고 있습니다. 단편적인 모델 성능 수치만으로는 복잡한 실문서에 대한 설득력 있는 대응이 어렵기 때문입니다.
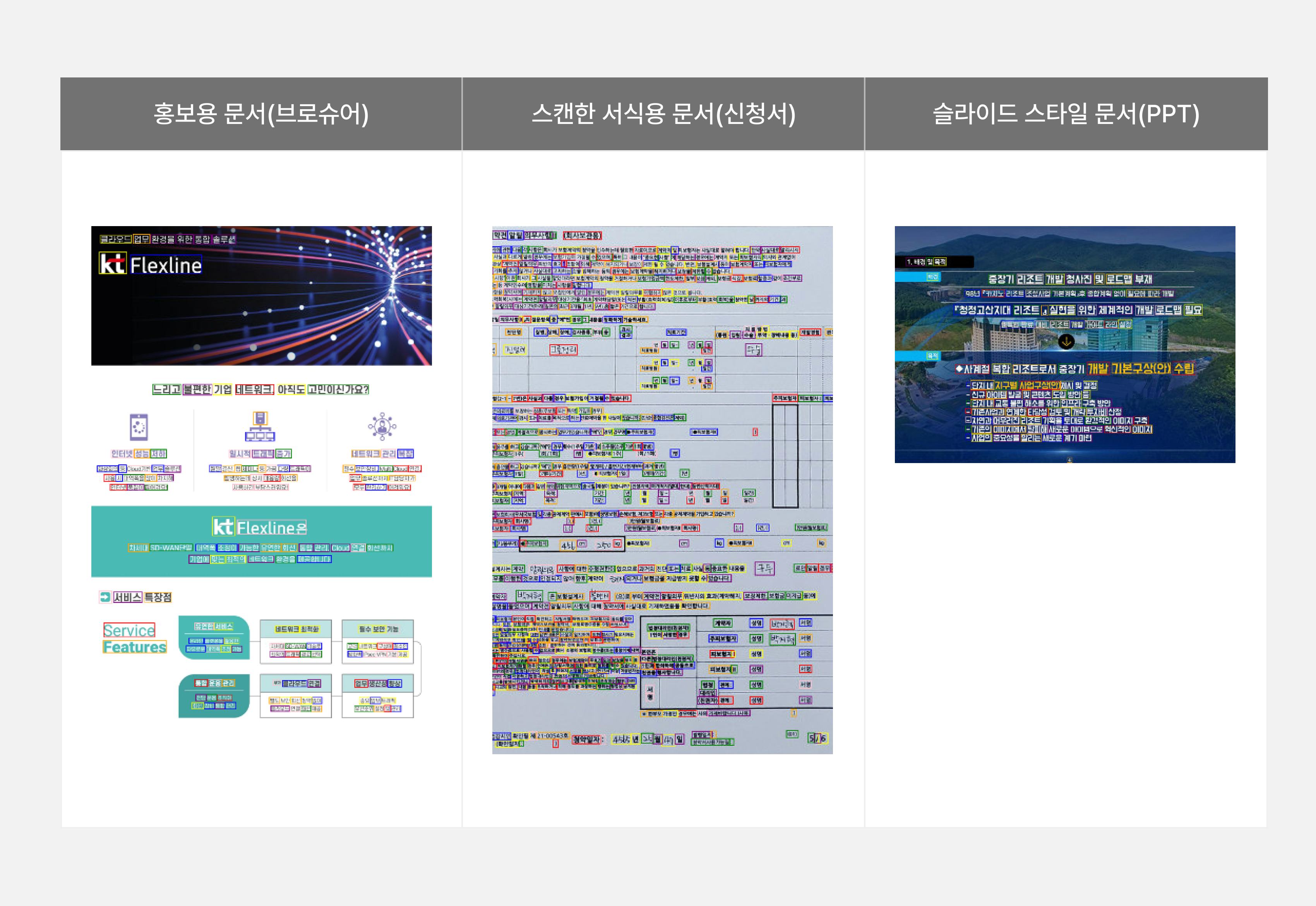
또한, 현재 활용되는 대부분의 벤치마크는 해외 논문이나 공공 데이터셋 기반으로 구성되어 있으며, 영어 중심의 문서나 제한된 형식의 레이아웃만을 다루고 있습니다[표 6]. 일부 한자나 수식이 포함된 문서가 존재하긴 하지만, 한국어 기반의 다양한 문서 스타일, 한자/특수기호, 복잡한 표 구조 및 차트 등 실제 국내 문서 환경을 일반화할 수 있는 종합적인 테스트셋은 부재한 상황입니다.
표6. 영어 중심의 공개 벤치마크 문서와 실제 고객 문서 예시
따라서, 한국형 문서의 특성을 반영한 실제 환경 기반의 통합 문서변환 벤치마크 192장의 데이터셋을 구축하고 검증 결과를 신뢰할 수 있는 성능 평가 Metric을 제안하였습니다.
3-2. 벤치마크 구성 및 특징
벤치마크 구성 개요
KT 통합문서변환 벤치마크는 B2B/G 고객 대상 PoC 경험을 기반으로 실제 업무 환경에서 접하는 다양한 문서 유형과 복합적인 정보 구조를 포함하도록 설계한 실문서 기반 종합 벤치마크입니다. 기존의 공공/영어 중심 벤치마크와는 차별화된 국내 환경 최적화 구성에 중점을 두었습니다[표 7].
표7. 실문서 기반 벤치마크 구성 항목 개요
벤치마크 구성 현황
표8. 벤치마크 구성 현황
구성 수량 : 192장 문서 이미지
도메인 별 구성
표9. 도메인 별 구성
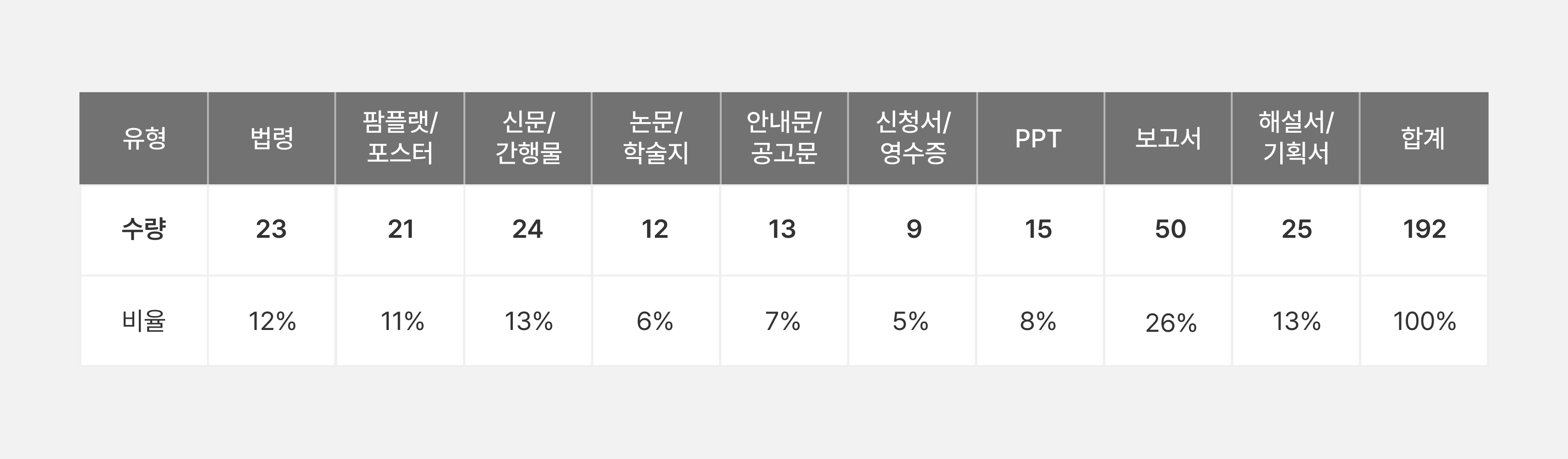
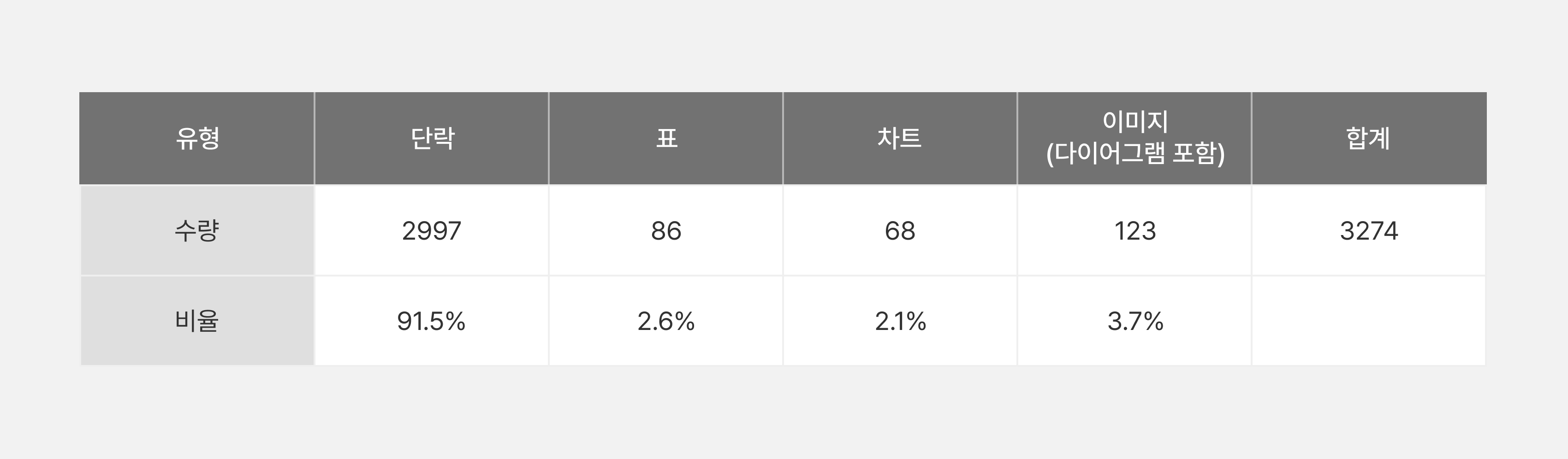
문서 요소 별 구성
표10. 문서 요소 별 구성
주요 특징 및 차별점
- 국내 실문서 중심 구성
: 단순한 공개 데이터가 아닌, 국내 B2B 고객의 실업무 문서 반영
- 정보 구조 다양성
: OCR 인식 외에도, 고난이도 표 구조(Lv1~3), 시각 자료(차트, 인포그래픽)까지 포괄
- 복잡한 레이아웃 대응
: 실제로 디지털 전환에서 문제가 되는 복잡 레이아웃 다수 포함
- PoC 기반 신뢰성 확보
: 실고객 대상 PoC 프로젝트 결과를 기반으로 구성 → 현장 요구 반영
- 산업별 적용성 검증
: 금융, 공공, 제조, 유통 등 다분야 문서 대응 가능하도록 설계
이와 같은 벤치마크는 Docu-See의 국내 환경 대응력 및 실무 적용성을 입증하는 핵심 기반으로, B2B 확산 전략에도 효과적으로 활용될 수 있습니다.
3-3. 벤치마크 Metric
한국형 문서 환경을 종합적으로 평가하기 위해, Docu-See 벤치마크는 문서 구성 요소 전반에 적용 가능한 통합 성능 지표를 설계하였습니다. 핵심 구성 요소인 텍스트, 테이블, 차트를 대상으로 각각의 구조와 내용을 정확히 복원하는 능력을 평가하며, 특히 문서의 자연스러운 읽기 순서와 시각적 레이아웃의 일관성까지 반영하기 위해 편집거리 기반의 평가 방식을 채택하였습니다.
레이아웃 분석 분야에서는 일반적으로 객체 탐지 기반 성능 평가 방법인 mAP(Mean Average Precision) 지표를 사용합니다. 그러나 기업마다 정의된 레이아웃 클래스의 영역이 상이하고, 클래스 정의 기준이 달라지기 때문에 mAP 지표로 성능을 비교하거나 일반화하기에는 어려운 문제가 있습니다. 이에 따라 레이아웃 분석 결과의 실제 활용과 정보의 흐름 및 의미 보존 측면에서 실질적인 성능 평가가 가능한 읽기 순서 평가 방법을 채택하였습니다. 기존 읽기 순서 연구 지표로는 NID(Normalized Indel Distance)가 있지만, 해당 지표는 OCR과 읽기 순서를 동시에 평가하는 지표로 성능 하락이 OCR 때문인지 잘못된 읽기 순서 때문인지를 구분할 수 없는 한계점이 있습니다.
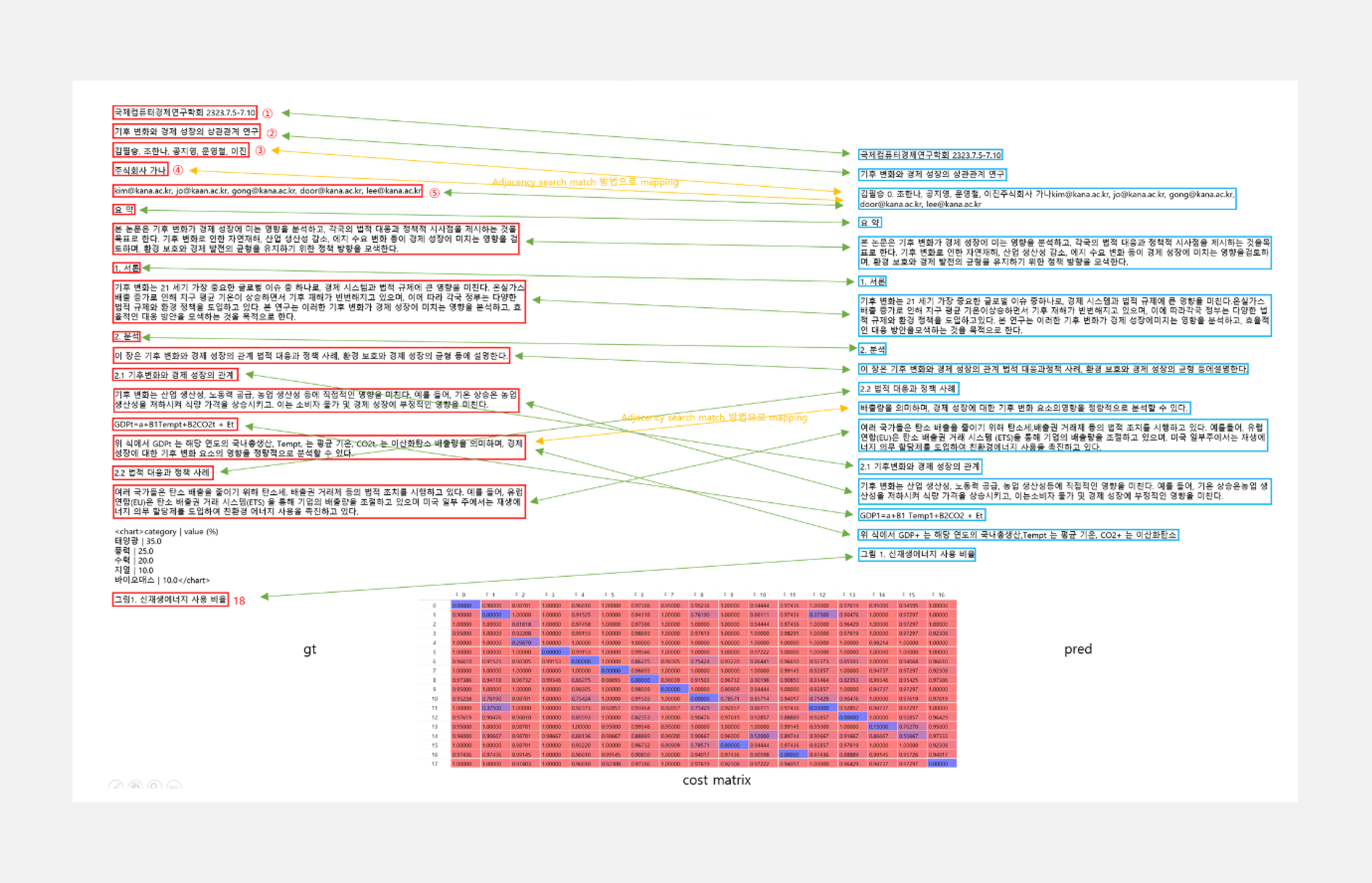
기존 읽기 순서 지표를 보완한 KT 읽기 순서 평가 방법은 분석한 레이아웃을 읽기 순서로 정렬한 후 markdown 형식으로 문서를 파싱합니다. 그리고 전처리 로직을 통해 GT와 분석한 레이아웃 요소들을 단락별로 매핑하여 문서 순서 간의 Levenshtein distance를 계산합니다.
계산 과정 Step-by-Step
- Step1
: Markdown 형식으로 문서 파싱
- Step2
: GT ↔︎ Pred 단락들 간의 Levenshtein distance로 cost matrix를 만들고,
1. Hungarian matching algorithm, 2. Adjacency search match 방법을 이용하여 매핑
- Step3
: GT ↔︎ Pred 의 문서 순서 간의 Levenshtein distance 계산
※ GT : [1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,15,16,17,18]
※ Pred: [1,2,3,4,5,6,7,8,9,10,11,16,15,17,12,13,14,15,18] (GT에 매핑된 기준으로 나열)
※ Order_score = 1 - (Levenshtein.distance(Pred, GT)/upper_len) = 1 - 6/19 = 0.631
문자 검출 성능과 인식 성능 평가를 하나의 통합 지표로 측정하기 위해 문자 단위 거리 측정(OCRedit_dist) 지표를 활용합니다. 기존 OCR 지표인 Precision/Recall은 실제 문서 내 문장이 자연스럽게 인식 되더라도 작은 텍스트 박스 위치 차이로 평가는 실패로 간주됩니다. 이러한 문자 위치 정합성만 가지고 부분 인식을 고려하지 않는 기존 지표는 LLM과 RAG와 같은 후속처리 단계에서 신뢰할 수 있는 데이터인지 품질을 측정하지 못합니다. 따라서 RAG/LLM 시스템의 신뢰도에 직결되는 데이터 품질 평가 척도로 단락 단위에서 부분 정합성을 인정하는 OCRedit_dist 지표를 활용합니다.
계산 과정 Step-by-Step
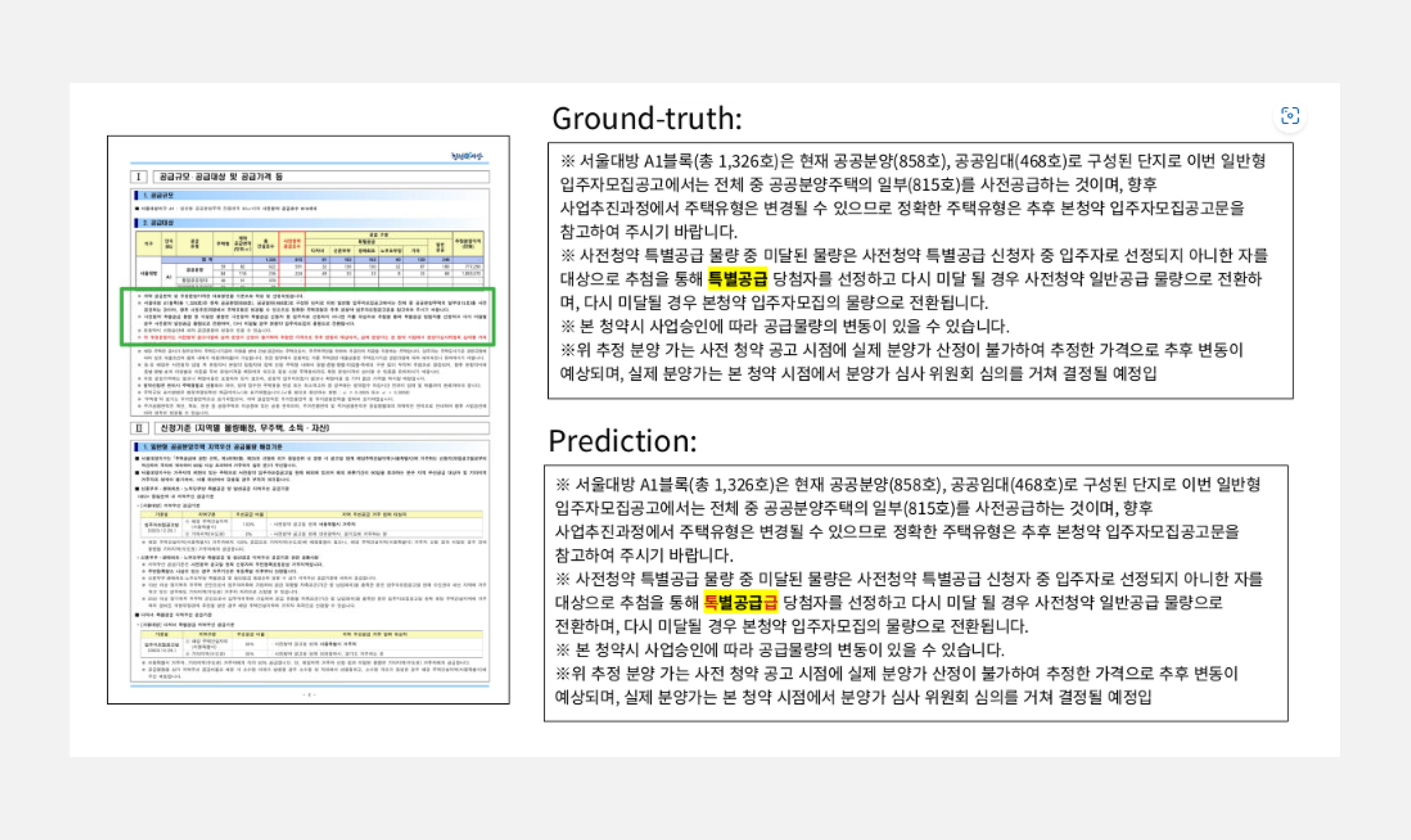
GT, Prediction 길이 출력:
- len(gt) → 368자
- len(pred) → 369자
- edit_dist: 3
”톡별공급급” → “톡“ 1글자 삭제
→ “특“ 1글자 삽입
→ “급“ 1글자 삭제
- nomalized_edit_dist = 3/369 = 0.0081
- OCRedit_dist = 1- 0.0081= 0.9919
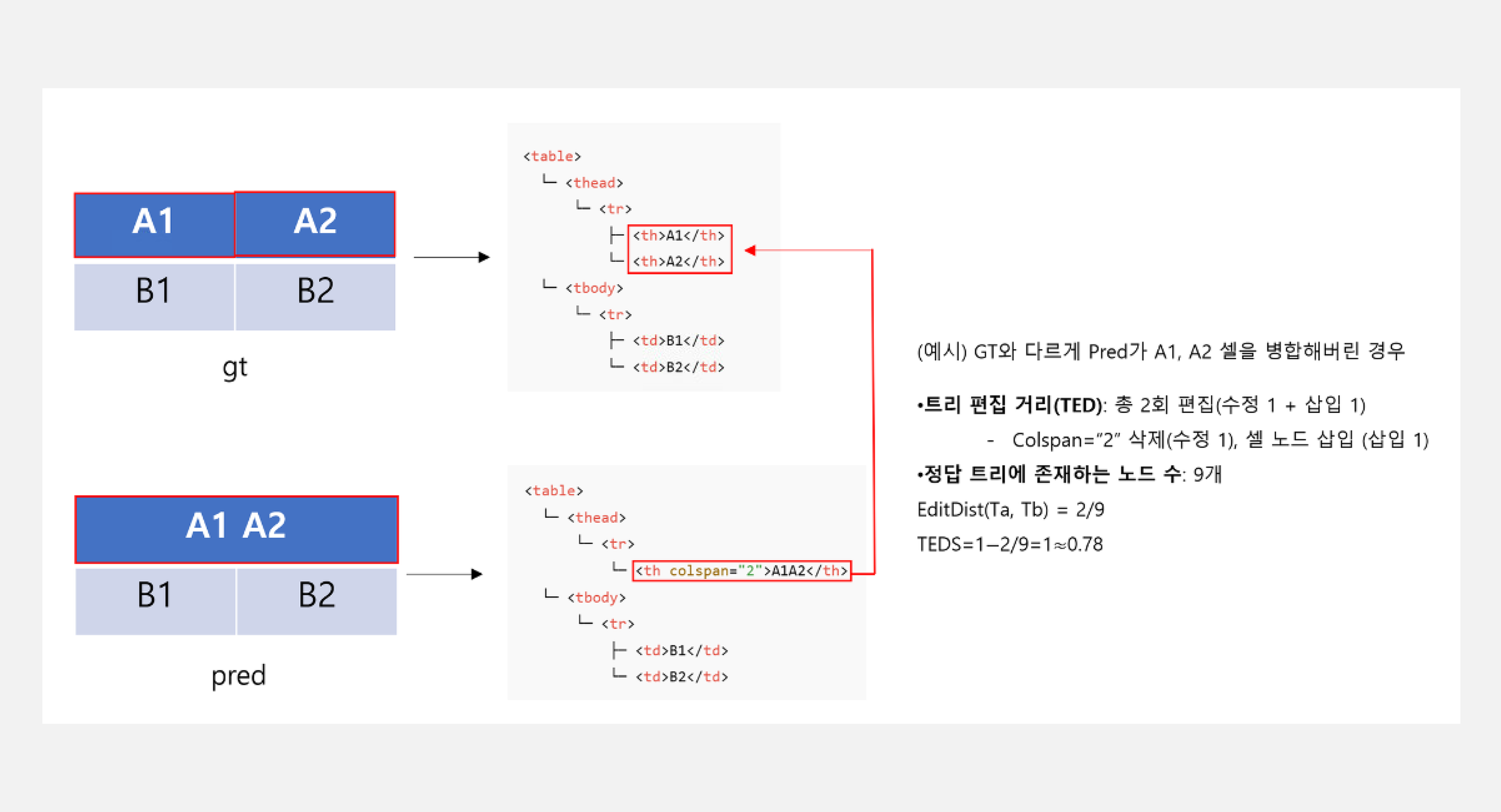
테이블 인식 성능 평가는 주로 TEDS-S (Tree-Edit Distance-based Similarity – Structure Only) 지표를 활용합니다. TEDS-S는 예측된 테이블 구조와 정답 테이블 구조 간의 유사도를 트리 편집 거리(Tree Edit Distance) 기반으로 측정합니다. 이를 위해 HTML 기반 테이블의 셀(cell), 행(row), 열(column) 구조를 트리 형태로 변환한 후, 두 트리 간의 최소 편집 거리 - 삽입, 삭제, 대체와 같은 연산의 최소 횟수를 계산합니다. 이후 이 편집 거리 값을 최대 트리 크기로 정규화하여 최종 점수를 산출합니다.
점수 해석:
- 1에 가까울수록: 예측 구조가 정답과 유사
- 0에 가까울수록: 구조적으로 완전히 상이
TEDS-S는 셀 분할, 셀 병합, 셀의 상대적 위치 등을 종합적으로 고려하면서도 텍스트 내용은 제외하고 순수한 구조적 유사성만을 정밀하게 평가할 수 있다는 장점이 있습니다. 이러한 특성으로 인해 TEDS-S는 테이블 구조 인식 분야에서 가장 널리 사용되는 대표적인 평가 지표로, 다양한 연구 및 실제 시스템 구축 환경에서 표준으로 활용되고 있습니다.
계산 과정 Step-by-Step
- Step1 : 테이블을 트리 구조로 변환
- HTML 기반 테이블의 셀(cell), 행(row), 열(column) 구조를 트리 형태로 변환
- 예: <table><tr><td>...</td>...</tr>...</table> 이런 HTML 구조를 파싱해서 트리로 만듦
- Step2 : 두 트리 사이의 편집 거리(edit distance) 계산
- 삽입, 삭제, 대체 연산의 최소 횟수
- Step3 : 정규화
- TEDS-s = 1 - (Tree Edit Distance / Max Tree Size)
- 1에 가까울수록 정답과 유사한 구조
- 0이면 완전히 다른 구조
차트 인식 성능을 평가하기 위해 많은 연구에서 활용하고 있는 RMS-F1(Relative Mapping Similarity) 지표를 채택하였습니다. RMS-F1은 단순히 숫자의 집합을 비교하는 방식이 아니라, 테이블을 (row header, column header) → value의 매핑으로 간주하여 평가하는 구조적 지표입니다. 예측 테이블과 정답 테이블의 각 항목은 (r, c, v) 형태로 표현되며, row header와 column header를 문자열로 결합해 고유한 키를 생성합니다. 이후, 두 테이블의 항목들 간 키 유사도와, 동일하거나 유사한 키에 대응하는 값(value) 간의 차이를 각각 비교합니다. 키 간의 유사도는 Normalized Levenshtein Distance NL_tau로 계산되며 값간의 차이는 상대 오차 D_theta로 계산합니다.
키간 유사도 행렬을 기반으로 최소 비용 매칭(binary matrix X∈RN×MX \in \mathbb{R}^{N \times M}X∈RN×M)을 수행한 후, precision과 recall은 다음과 같이 정의됩니다:
RMS Precision:
RMS Recall:
최종 RMS-F1 점수는 위의 precision과 recall의 조화 평균으로 계산됩니다. 이를 통해 구조적 유사성과 수치적 정확도를 동시에 평가할 수 있으며, 단순한 값 일치 여부를 넘어서 테이블이 표현하려는 실제 의미를 고려하여 비교가 가능합니다.
계산 과정 Step-by-Step
- Step 1
: 테이블 안의 각 셀을 튜플 형태로 변환 후, 추론 결과와 정답을 비교
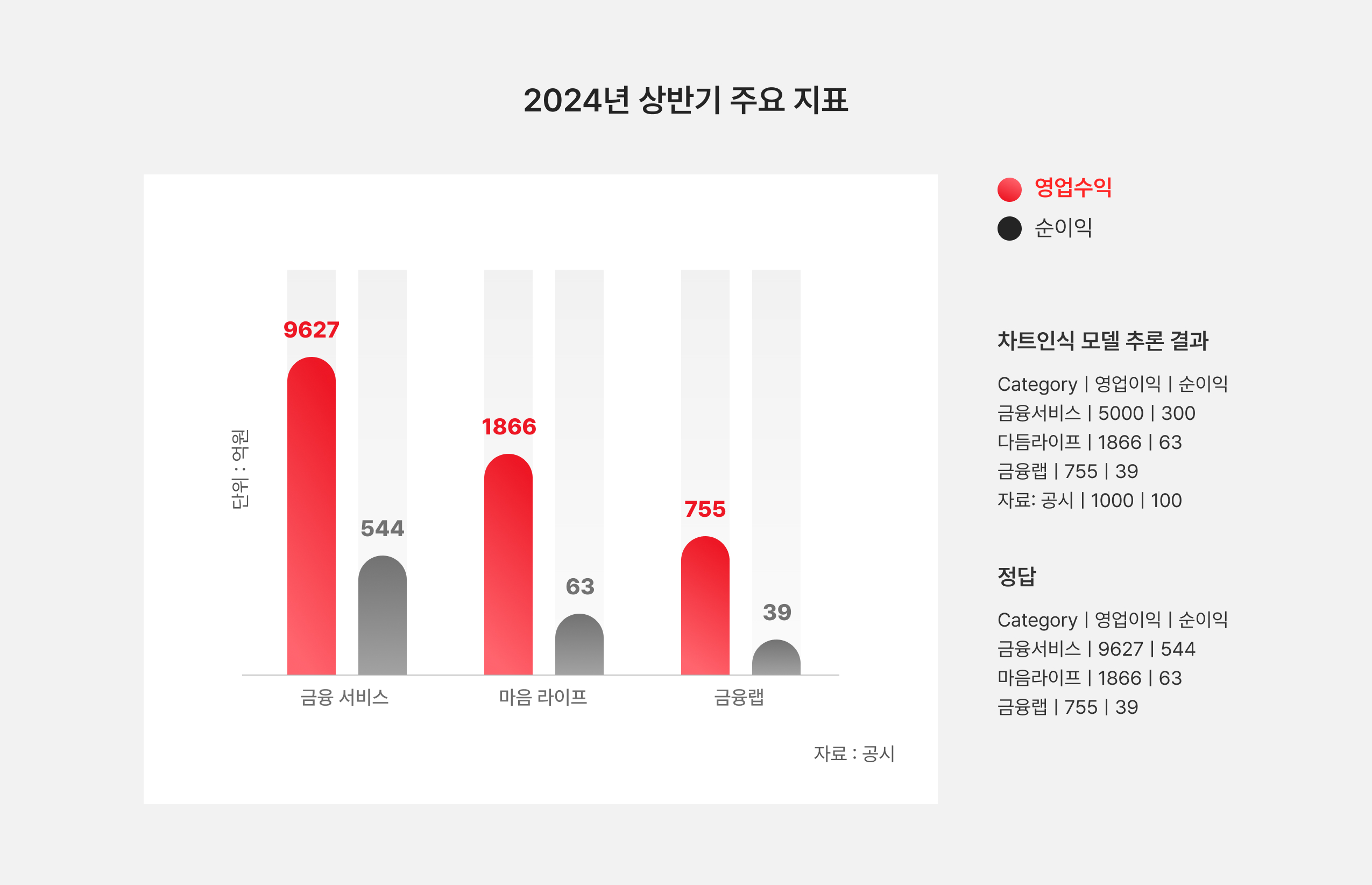
※ 추론 결과 튜플: (금융서비스, 영업수익, 5000), (금융서비스, 순이익, 300),
(다듬라이프, 영업수익, 1866), (다듬라이프, 순이익, 63),(금융랩, 영업수익, 755),
(금융랩, 순이익, 63), (자료: 공시, 영업수익, 1000), (자료: 공시, 순이익, 100)
※ 정답 튜플: (금융서비스, 영업수익, 9627), (금융서비스, 순이익, 544),
(마음라이프, 영업수익, 1866), (마음라이프, 순이익, 63),
(금융랩, 영업수익, 755), (금융랩, 순이익, 63)
- Step 2
: ‘항목명 || 범례’ 를 기준으로 일대일 최소비용 매칭 후, ('항목명 || 범례' 유사도) * (셀 값 유사도) 총합 계산
※ (금융서비스영업수익, 5000) ↔ (금융서비스영업수익, 9627) = 1 * 0.52 = 0.52
※ 총합 = (0.52+0.55+0.6+0.6+1+1) = 4.27
※ RMSprecision = 총합 / 예측 튜플 개수 = 4.27 / 8 = 0.53
※ RMSrecall = 총합 / 정답 튜플 개수 = 4.27 / 6 = 0.71
※ RMS-F1 = 0.61
3-4. 평가 방법론
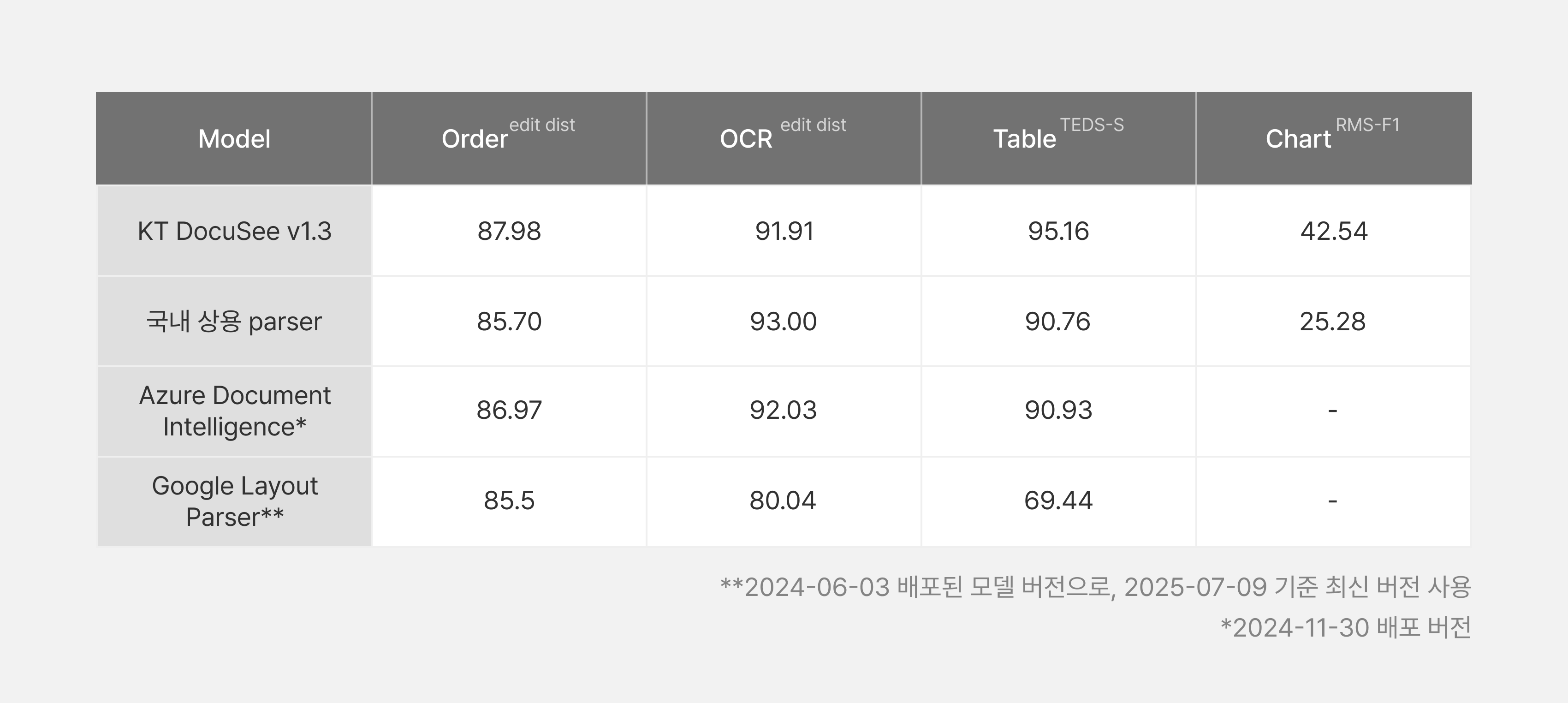
평가의 타당성을 검증하기 위해, 당사 시스템(DocuSee)의 출력 형식과 유사한 결과를 생성하는 타사 서비스에 대해서 동일한 기준으로 성능을 측정하고 비교하였습니다[표 11].
4. Lesson-Learned & 향후 고도화 계획
KT Docu-See를 다양한 금융 및 공공 산업 현장에 실제 도입하며, 다음과 같은 중요한 학습과 성장을 경험할 수 있었습니다:
- 다양한 문서 유형에 대응한 커스텀 모델 필요성
- 실제 사업에서는 2단 텍스트, Table in Table, 체크박스, 그래프(차트) 등 복합적인 구조를 가진 문서가 대부분이었습니다.
- 이를 처리하기 위해 단일 범용 모델보다, 문서 유형별 커스텀 파이프라인 구성이 효율적이라는 교훈을 얻었습니다.
- OCR 정확도 개선을 위한 사전 전처리 중요성
- 비정형 문서의 경우 이미지 품질, 스캔 방향, 텍스트 누락 등 문제가 빈번히 발생했습니다.
- 이에 따라, 기하학적 왜곡 보정, 문자 별 특징 파악 등 전처리 모듈을 강화해 OCR 인식률을 향상시킬 수 있었습니다.
- LLM 기반 문서 이해력은 레이아웃 순서와 문맥 유지가 핵심
- GPT 등 대규모 언어모델(LLM) 기반 문서 처리 시, 문서의 시각적 순서를 정확하게 재구성한 후 텍스트를 추출해야 문맥이 올바르게 전달됨을 확인했습니다.
- 이로 인해 레이아웃 기반 시퀀스 구성 모델을 개발 및 적용하게 되었습니다.
- 복잡한 표 및 차트 인식을 위한 객체 탐지 + 문맥 해석 융합
- 단순 OCR로는 병합 셀, 구분선이 없는 표, 인포그래픽 기반 차트 해석이 불가능했습니다.
- 표 구조 인식 + 차트 인식의 VLM 기반 문맥 분석을 결합하여 이를 구조화하는 방식을 도입했고, 실제 문서 자동화 정확도가 크게 향상되었습니다.
- AI 적용을 통해 수작업 대비 처리 시간 단축
- 시범 서비스 결과, 문서 자동 분류 및 색인 처리 시간이 평균 20초 → 10초 이하로 감소하며 생산성 향상을 입증하였습니다.
맺음말
KT Docu-See의 발전한 모습으로 다시 뵙기를 희망합니다!
함께한 사람들
Gen AI Lab 조직의 천왕성(wangsung.chun), 박상민(ethan.park), 나재민(jaemin.na), 사공락(rock.sakong), 김현수(hyunsu.kim), 도우찬(woochan.do), 유혜원(hyewon.yoo), 윤기범(Kibum.0927), 천명철(myungchul.cheon)이 함께했습니다. 시스템 개발 및 구축에 있어서 도우찬, 천명철님이 많은 도움을 주셨습니다.
감사의 말
코어 엔진에서부터 각 엔진들이 유기적으로 동작 할 수 있도록 파이프라인 개발 구축 및 서비스 배포까지, GenApp기술팀 한 분 한 분, 고생 정말 많았습니다. 덕분에 저희 팀에서 제품의 프로토타입에서 프로덕트까지 한계를 끌어올리는 경험 할 수 있었습니다. 팀원 모두에게 감사의 말을 전합니다.