
2025년 4월 15일, KT가 ‘NH농협 차세대 컨택센터 구축’ 사업에 참여 한다고 전달 받았다. 우리 기술은 기존 AICC 사업에서 좋은 성과를 보였기 때문에 해볼만한 사업이라고 판단됐지만 두 가지의 문제가 있었다. 첫째, 고성능의 화자분리(Speaker Diarization)기술 필요했으며 둘째, BMT 까지 우리에겐 주어진 시간은 단 한 달 이었다. 사업이 이처럼 급박하게 진행될 줄은 예상하지 못했던 탓에, BMT에 투입할 시스템조차 구축되지 않은 상태였다. 따라서 주어진 시간동안 우리가 보유한 기반 기술을 어떻게 유기적으로 연결해 나가느냐가 주어진 숙제였다. 지금부터 KT의 ‘NH농협 차세대 컨텍센터’ 사업 수주 성공에 대한 숨가빴던 이야기를 기록해보고자 한다.
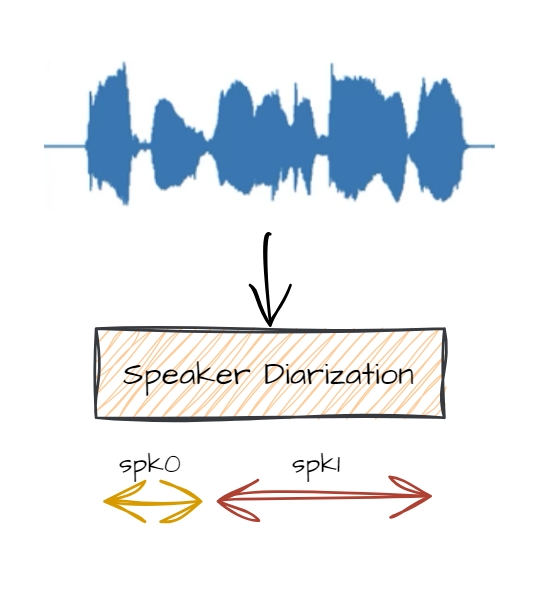

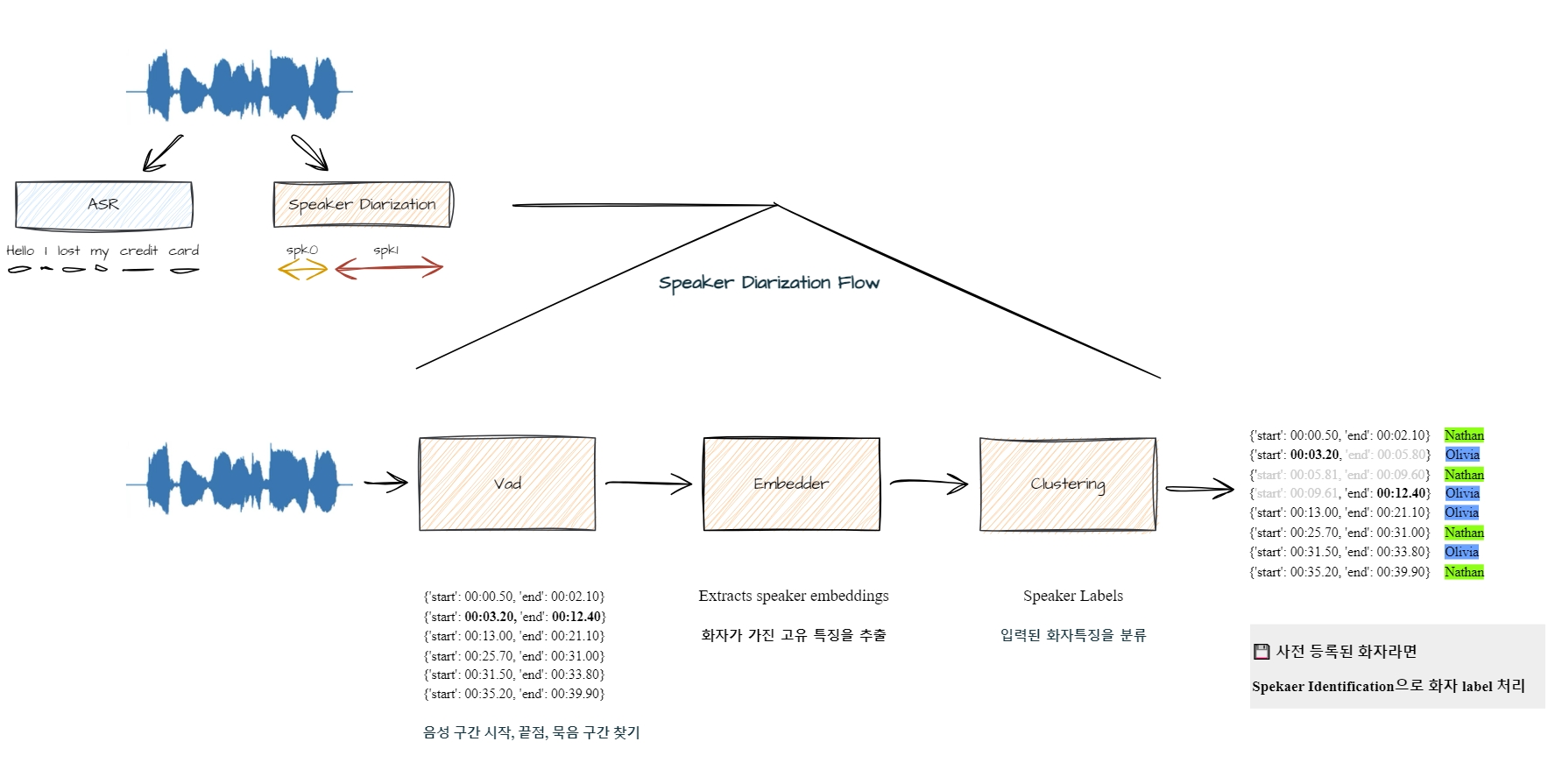
 화자분리 Cascade 방식은 크게 3개의 모듈로 구성돼 있다. 첫째, VAD(Voice Activity Detection)는 음성 구간을 찾는 기술로써 묵음을 제외한 음성의 시작, 끝 점을 찾는 기술이다. 둘째, Embedder는 화자특성이 반영된 벡터를 추출하는 모델로 화자인식분야 에서는 Sequential 정보처리에 적합한 ECAPA-TDNN과, 미세한 음향적 패턴을 추출하는 RESNET(CNN + Residual Learning)이 대표적인데 큰 차이점 으로는 각각 1d-conv, 2d-conv 사용을 꼽을수 있다. 셋째, Clustering은 label(정답) 없는 다차원의 embedding vector들에서 유사성을 찾은 후 그룹(Cluster)으로 묶는 기법이다. 우리는 이 세가지의 모듈을 통해서 ‘누가 언제 말을 했는가'에 대한 정보를 획득할 수 있는데 이를 '화자분리’라고 부른다.
화자분리 Cascade 방식은 크게 3개의 모듈로 구성돼 있다. 첫째, VAD(Voice Activity Detection)는 음성 구간을 찾는 기술로써 묵음을 제외한 음성의 시작, 끝 점을 찾는 기술이다. 둘째, Embedder는 화자특성이 반영된 벡터를 추출하는 모델로 화자인식분야 에서는 Sequential 정보처리에 적합한 ECAPA-TDNN과, 미세한 음향적 패턴을 추출하는 RESNET(CNN + Residual Learning)이 대표적인데 큰 차이점 으로는 각각 1d-conv, 2d-conv 사용을 꼽을수 있다. 셋째, Clustering은 label(정답) 없는 다차원의 embedding vector들에서 유사성을 찾은 후 그룹(Cluster)으로 묶는 기법이다. 우리는 이 세가지의 모듈을 통해서 ‘누가 언제 말을 했는가'에 대한 정보를 획득할 수 있는데 이를 '화자분리’라고 부른다.
#BMT참여 결정
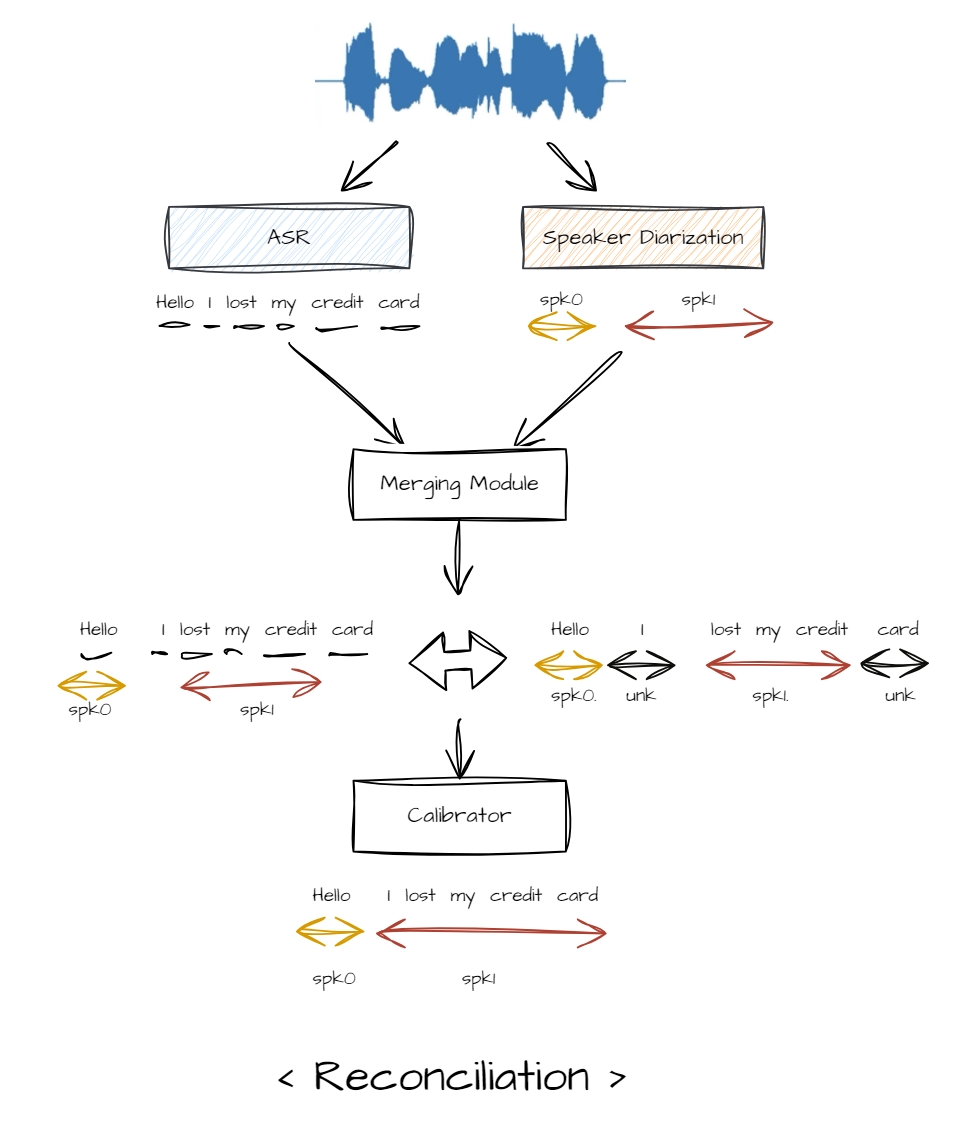
연구개발이 진행중이던 4월 ‘NH농협 차세대 컨택센터 구축’ 사업 참여 소식에 매우 혼란스러웠다. 자체적으로 우수한 기술을 보유 했다고 자부하지만 이를 상품화 하는것은 매우 까다롭고 많은 시간이 필요하기 때문이다. 또한 이번 사업의 최종 출력물은 화자분리 그리고 음성인식 두 가지 결과를 결합 및 재구성 해야하는 매우 까다로운 요구사항이 존재 했기 때문에 Reconciliation이라는 새로운 알고리즘의 개발도 필요했다. 고객사의 요구사항인 Non-streaming 형상에 맞춰 개발을 진행했고, 4월 말에 프로토타입을 완성한 뒤 자체 성능 검증을 진행하며 어느정도 안정화를 단계에 접어 들었다.
#갑작스러운 테스트 시나리오 변경
5월 6일 고객사로부터 시나리오 변경을 요구 받았다. 기존 화자분리, 음성인식 테스트는 각각 Non-streaming, Streaming 방식으로 진행될 예정이었으나 모두 Streaming 형상으로의 변경 요청이었다. 내부적으로 완성도를 높이기 위한 작업을 진행하던 시점에서 다시 원점으로 돌아가게 됐고, 기한내에 개발하지 못한다면 사업을 사실상 포기해야 하는 상황이었고, Streaming 화자분리를 시장에 공개한 국내 기업이 없었기에 전략 수립마저 어려움이 존재했다.
#선행 연구에 필요성
우리는 최신 연구동향에 맞춰 고성능 모델을 구축하고 이를 사업에 적용할 수 있도록 다양한 연구개발을 진행중 있다. 실시간 분리 역시 이러한 연구의 일환으로 진행 중이었는데 핵심은 Streaming으로 결과를 출력함과 동시에 성능이 유지되는 것이었는데, 그 배경으로 최근 연구되는 고성능 VAD는 입력을 한번에 모델에 입력하고 출력하는 구조를 갖기 때문에 실시간 처리가 어렵다. 이 기술은 본래 ‘25년 4Q를 목표로 개발을 진행하고 있었으나 'NH농협 차세대 컨택센터 구축’ 사업에 참여하게 되면서 일정을 앞당겨 선보이게 되었다. 새롭게 제시된 시나리오에 맞춰 관계자들의 열띤 토론 끝에 구조를 재정비 할수 있었다. 경험 많은 서버 시스템 담당자와 협력하여 화자분리 및 음성인식 엔진을 적용하고, 발생하는 오류를 차근차근 해결해 나갔다. 팀장님을 포함한 많은 인원들의 노력끝에 5월12일 AX솔루션개발팀에게 최종버전을 전달했다. 이번 사업을 통해 선행연구의 가치를 다시 한번 느낄수 있는 경험이었다.#기술의 재평가 'NH농협 차세대 컨택센터 구축’ 사업은 그간 쌓아온 기술을 시험하는 기회이기도 했다. 최종 경쟁사는 L그룹 2개 계열사였고 이들은 이 사업을 수주하기 위해 꽤 긴시간 노력을 해왔단 사실도 알게됐다. 배수진을 치고 경쟁에 뛰어든 타 기업과의 경쟁이 쉽지 않겠지만 그래도 기술로써 경쟁력이 있다고 판단했고, 결과적으로 KT가 우선협상을 진행하게 됐다.
#앞으로 연구방향
화자분리(Speaker Diarization)는 음성인식(Speech Recognition)과의 결합으로 추론 정보를 확장 시킬수 있다. 화자분리는 ‘누가 언제 말을 했는가?’를, 음석인식은 ‘어떤 말을 했는가?’를 각각 추론하는 task로써 둘의 결합을 통해 ‘누가 언제 어떤 말을 했는가?’를 추론할수 있게되는데, 이 기술을 적용하면 회의록 자동화가 가능해질수 있다. 회의록 시스템으로 예를 들자면, 현재는 문맥정보 만으로 대화의 흐름을 이해하고 요약하고 있는 반면 화자분리 기술이 적용된 입력이라면 LLM이 마치 대본을 처리하는 하는 방식으로 변하기 때문에 내용 및 화자별 요약등에 매우 높은 정확도를 보일수 있게된다. 하지만 두가지 모델을 결합 하다보니 오류가 발생할 수 있다. 이를 해결하기 위해서 최근 구글과 엔비디아가 선두적으로 LLM을 활용한 교정 모델을 연구하고있다.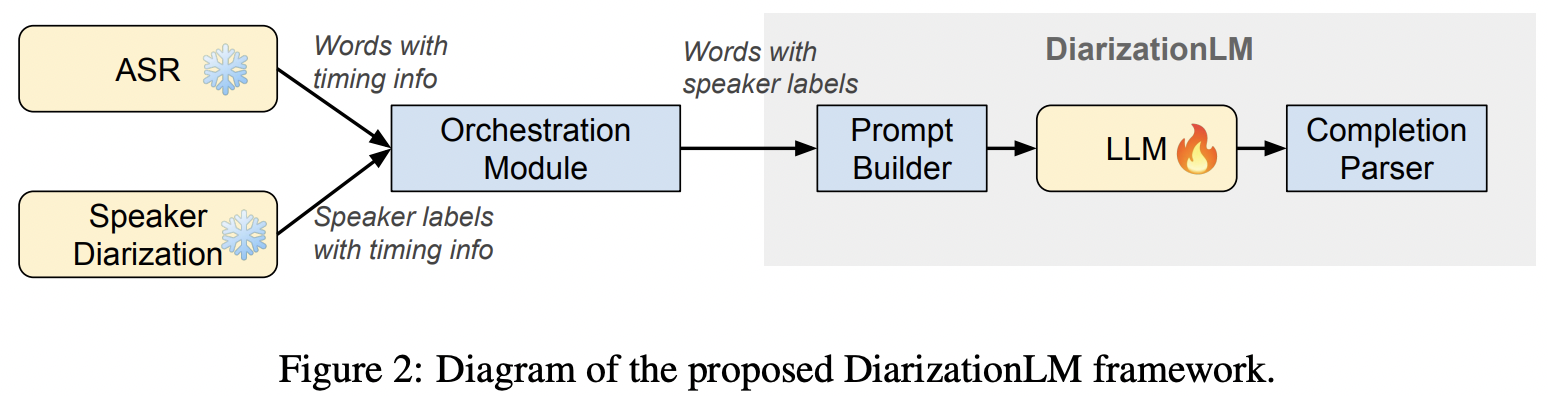 PostProcessing with LLM(2024~현재), Google 해당 기술은 화자분리와 음성인식 모델에서 결합&교정 중 간혹 시간정보 불일치로 발생하는 '단어 밀림'을 해결하기 위해 연구인데, 우리 또한 동일한 문제를 해결하기 위해 고민 해왔기 때문에 이 연구들에서 제시한 방법을 차용해 문제를 해결해 보고자 하며 더 나아가 speech 팀에서 연구 하고 있는 SpeechLM에 통합할 계획이다.
PostProcessing with LLM(2024~현재), Google 해당 기술은 화자분리와 음성인식 모델에서 결합&교정 중 간혹 시간정보 불일치로 발생하는 '단어 밀림'을 해결하기 위해 연구인데, 우리 또한 동일한 문제를 해결하기 위해 고민 해왔기 때문에 이 연구들에서 제시한 방법을 차용해 문제를 해결해 보고자 하며 더 나아가 speech 팀에서 연구 하고 있는 SpeechLM에 통합할 계획이다.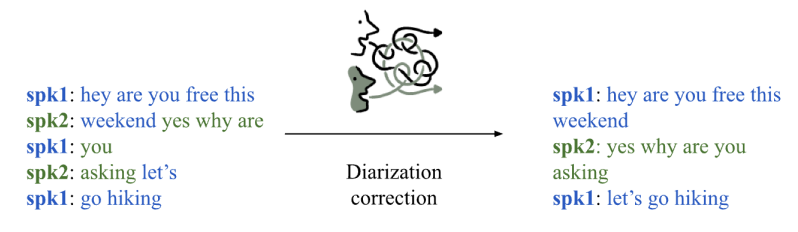 Diarization Correction with LLM(2024~현재), Nvidia
Diarization Correction with LLM(2024~현재), Nvidia
#화자분리란 무엇인가?
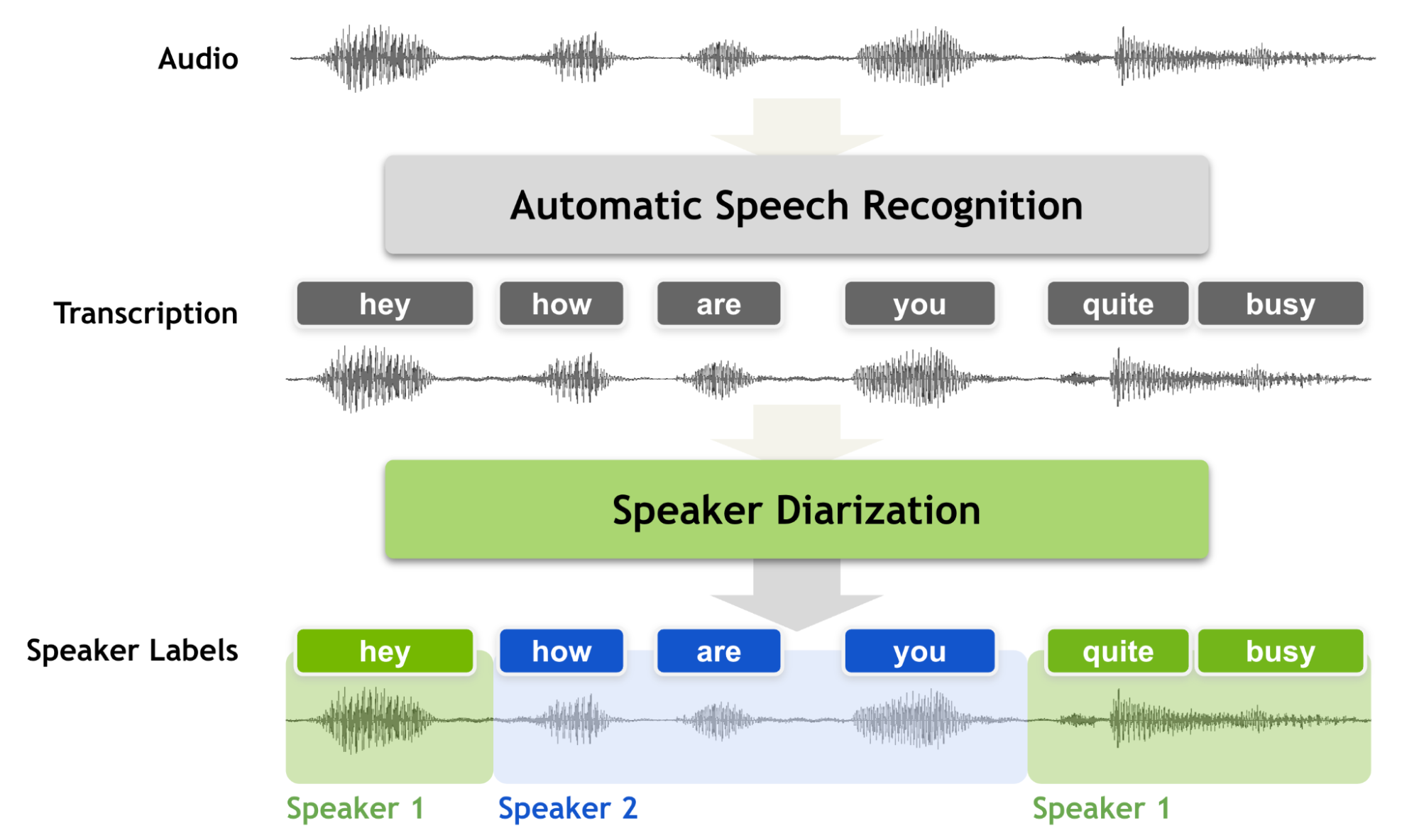
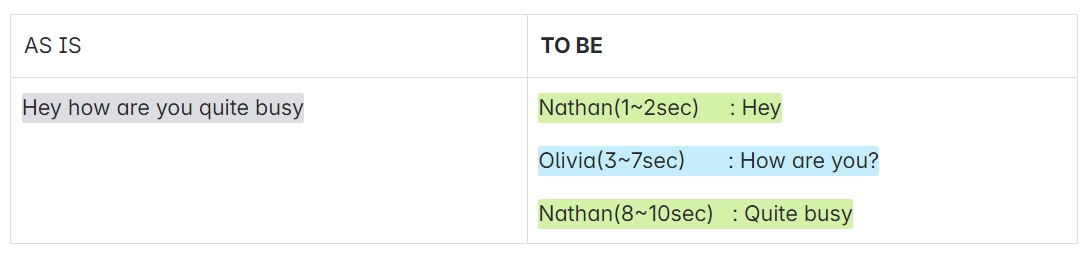
화자분리는 음성구간에 대해서 화자가 가지는 특징을 추출하고 클러스터링을 통해 화자를 분리해 내는 기술로 “누가 언제 말을 했는가”를 판단한다. 대표적으로 트랜스포머 기반 EEND(End-to-End neural diarization)방식과 CNN(Convolutional Neural Networks) 기반 Cascade 방식이 많이 연구되고있다. KT는 두가지 기술을 모두 보유중이며 이번 NH농협 BMT에는 Cascade 방식이 적용됐다.⓵ 화자분리 : 누가 언제 말을 했는가?⓶ 음석인식 : 어떤 말을 했는가?( ⓵ + ⓶ ) : 누가 언제 어떤 말을 했는가? 마이크로 다수의 대화가 유입된다면 우리는 ⓶ 음석인식 시스템을 통해서 음성을 텍스트로 변환하는 기술을 활용해 왔다. 그러나 다수가 각각 어떤 의도를 가지고 대화를 하는지 판단하기 어렵기 때문에 전체적인 내용을 요약하기 매우 어려웠다. 이때 ⓵ 화자분리 시스템이 추가 된다면 우리는 ‘언제 누가 어떤 말을 하는가?’에 대한 추론이 가능해지고 마치 대본처럼 텍스트를 작성할수 있게 된다. 이 결과를 통해 우리는 어떤 화자가 어떤 의도를 가지고 말을 하는지 판단할 수 있게 된다. 화자분리 Cascade 방식은 크게 3개의 모듈로 구성돼 있다. 첫째, VAD(Voice Activity Detection)는 음성 구간을 찾는 기술로써 묵음을 제외한 음성의 시작, 끝 점을 찾는 기술이다. 둘째, Embedder는 화자특성이 반영된 벡터를 추출하는 모델로 화자인식분야 에서는 Sequential 정보처리에 적합한 ECAPA-TDNN과, 미세한 음향적 패턴을 추출하는 RESNET(CNN + Residual Learning)이 대표적인데 큰 차이점 으로는 각각 1d-conv, 2d-conv 사용을 꼽을수 있다. 셋째, Clustering은 label(정답) 없는 다차원의 embedding vector들에서 유사성을 찾은 후 그룹(Cluster)으로 묶는 기법이다. 우리는 이 세가지의 모듈을 통해서 ‘누가 언제 말을 했는가'에 대한 정보를 획득할 수 있는데 이를 '화자분리’라고 부른다.
#BMT참여 결정
연구개발이 진행중이던 4월 ‘NH농협 차세대 컨택센터 구축’ 사업 참여 소식에 매우 혼란스러웠다. 자체적으로 우수한 기술을 보유 했다고 자부하지만 이를 상품화 하는것은 매우 까다롭고 많은 시간이 필요하기 때문이다. 또한 이번 사업의 최종 출력물은 화자분리 그리고 음성인식 두 가지 결과를 결합 및 재구성 해야하는 매우 까다로운 요구사항이 존재 했기 때문에 Reconciliation이라는 새로운 알고리즘의 개발도 필요했다. 고객사의 요구사항인 Non-streaming 형상에 맞춰 개발을 진행했고, 4월 말에 프로토타입을 완성한 뒤 자체 성능 검증을 진행하며 어느정도 안정화를 단계에 접어 들었다.
#갑작스러운 테스트 시나리오 변경
5월 6일 고객사로부터 시나리오 변경을 요구 받았다. 기존 화자분리, 음성인식 테스트는 각각 Non-streaming, Streaming 방식으로 진행될 예정이었으나 모두 Streaming 형상으로의 변경 요청이었다. 내부적으로 완성도를 높이기 위한 작업을 진행하던 시점에서 다시 원점으로 돌아가게 됐고, 기한내에 개발하지 못한다면 사업을 사실상 포기해야 하는 상황이었고, Streaming 화자분리를 시장에 공개한 국내 기업이 없었기에 전략 수립마저 어려움이 존재했다.
#선행 연구에 필요성
우리는 최신 연구동향에 맞춰 고성능 모델을 구축하고 이를 사업에 적용할 수 있도록 다양한 연구개발을 진행중 있다. 실시간 분리 역시 이러한 연구의 일환으로 진행 중이었는데 핵심은 Streaming으로 결과를 출력함과 동시에 성능이 유지되는 것이었는데, 그 배경으로 최근 연구되는 고성능 VAD는 입력을 한번에 모델에 입력하고 출력하는 구조를 갖기 때문에 실시간 처리가 어렵다. 이 기술은 본래 ‘25년 4Q를 목표로 개발을 진행하고 있었으나 'NH농협 차세대 컨택센터 구축’ 사업에 참여하게 되면서 일정을 앞당겨 선보이게 되었다. 새롭게 제시된 시나리오에 맞춰 관계자들의 열띤 토론 끝에 구조를 재정비 할수 있었다. 경험 많은 서버 시스템 담당자와 협력하여 화자분리 및 음성인식 엔진을 적용하고, 발생하는 오류를 차근차근 해결해 나갔다. 팀장님을 포함한 많은 인원들의 노력끝에 5월12일 AX솔루션개발팀에게 최종버전을 전달했다. 이번 사업을 통해 선행연구의 가치를 다시 한번 느낄수 있는 경험이었다.#기술의 재평가 'NH농협 차세대 컨택센터 구축’ 사업은 그간 쌓아온 기술을 시험하는 기회이기도 했다. 최종 경쟁사는 L그룹 2개 계열사였고 이들은 이 사업을 수주하기 위해 꽤 긴시간 노력을 해왔단 사실도 알게됐다. 배수진을 치고 경쟁에 뛰어든 타 기업과의 경쟁이 쉽지 않겠지만 그래도 기술로써 경쟁력이 있다고 판단했고, 결과적으로 KT가 우선협상을 진행하게 됐다.
#앞으로 연구방향
화자분리(Speaker Diarization)는 음성인식(Speech Recognition)과의 결합으로 추론 정보를 확장 시킬수 있다. 화자분리는 ‘누가 언제 말을 했는가?’를, 음석인식은 ‘어떤 말을 했는가?’를 각각 추론하는 task로써 둘의 결합을 통해 ‘누가 언제 어떤 말을 했는가?’를 추론할수 있게되는데, 이 기술을 적용하면 회의록 자동화가 가능해질수 있다. 회의록 시스템으로 예를 들자면, 현재는 문맥정보 만으로 대화의 흐름을 이해하고 요약하고 있는 반면 화자분리 기술이 적용된 입력이라면 LLM이 마치 대본을 처리하는 하는 방식으로 변하기 때문에 내용 및 화자별 요약등에 매우 높은 정확도를 보일수 있게된다. 하지만 두가지 모델을 결합 하다보니 오류가 발생할 수 있다. 이를 해결하기 위해서 최근 구글과 엔비디아가 선두적으로 LLM을 활용한 교정 모델을 연구하고있다.
PostProcessing with LLM(2024~현재), Google 해당 기술은 화자분리와 음성인식 모델에서 결합&교정 중 간혹 시간정보 불일치로 발생하는 '단어 밀림'을 해결하기 위해 연구인데, 우리 또한 동일한 문제를 해결하기 위해 고민 해왔기 때문에 이 연구들에서 제시한 방법을 차용해 문제를 해결해 보고자 하며 더 나아가 speech 팀에서 연구 하고 있는 SpeechLM에 통합할 계획이다.Diarization Correction with LLM(2024~현재), Nvidia