
안녕하세요. 저희는 KT의 Gen AI Lab에서 언어 모델 연구·개발을 담당하고 있는 한지은(pre-training), 주형주(post-training)입니다. 이 글에서는 저희가 어떻게 믿:음 2.0 언어모델을 개발했는지, 데이터 구축부터 학습 전략, 모델 구조와 성능 평가까지 전체 과정을 상세히 소개하고자 합니다. KT는 2023년 말 믿:음 1.0을 선보인 이래, 약 1년의 개발 기간을 거쳐 마침내 완전히 새로운 믿:음 2.0을 공개 합니다. 믿:음 2.0은 널리 사용되는 모델 구조를 적용하고, 고품질 데이터를 활용하며, 사용 목적에 맞는 다양한 모델 라인업을 갖추는 데 중점을 두고 개발되었습니다. 이번에 공개하는 믿:음 2.0 Base와 믿:음 2.0 Mini 모델은 각각 범용 서비스용 모델과 온디바이스 환경에 최적화된 경량 모델로 설계되었으며, 영어뿐만 아니라 특히 한국어에서 뛰어난 성능을 보여줍니다. 믿:음 2.0은 HuggingFace에서 자유롭게 다운로드할 수 있으며, 연구나 실험은 물론 상업적 목적으로도 제한 없이 사용 가능합니다.
1. Overview
한국적인 AI 모델, 믿:음 2.0
믿:음 2.0은 KT의 고유 기술로 개발한 '한국적인' 인공지능(AI) 모델입니다. 여기서 '한국적 AI'란, 한국의 정신과 사고방식, 그리고 우리만의 지식과 문화를 충분히 학습하여 한국 사람들을 더 잘 이해하고 자연스럽게 소통할 수 있는 AI를 의미합니다. 현재도 한국어를 지원하는 공개 AI 모델들이 다수 존재하지만, 실제로 사용해보면 한국어의 뉘앙스를 섬세하게 이해하고 표현하는 모델을 찾기는 쉽지 않습니다.
믿:음 1.0보다 더욱 더 한국어의 언어적·문화적 특성을 잘 반영하는 모델을 만들기 위해, 한국 문화를 배경으로 한 다양하고 안전한 고품질 데이터를 KT만의 기준으로 선별하여 학습에 활용했습니다. 또한 한국의 지식과 문화가 잘 드러나는 합성 데이터도 함께 활용하여 모델의 한국어 이해력을 한층 향상시켰습니다. 한국어의 특성을 고려한 자체 토크나이저를 새롭게 설계하여 더 높은 압축률로 효율적인 학습이 가능하도록 했습니다. 언어모델 성능과 학습 효율성을 모두 확보하기 위해 모델 구조, 크기, 경량화, 병렬화, 양자화 등 다양한 기술적 방법을 적용하였습니다. 국내외 오픈 모델 대비 훨씬 적은 양의 학습으로 최적의 모델을 구현했습니다.
믿:음 2.0 모델 라인업과 특징
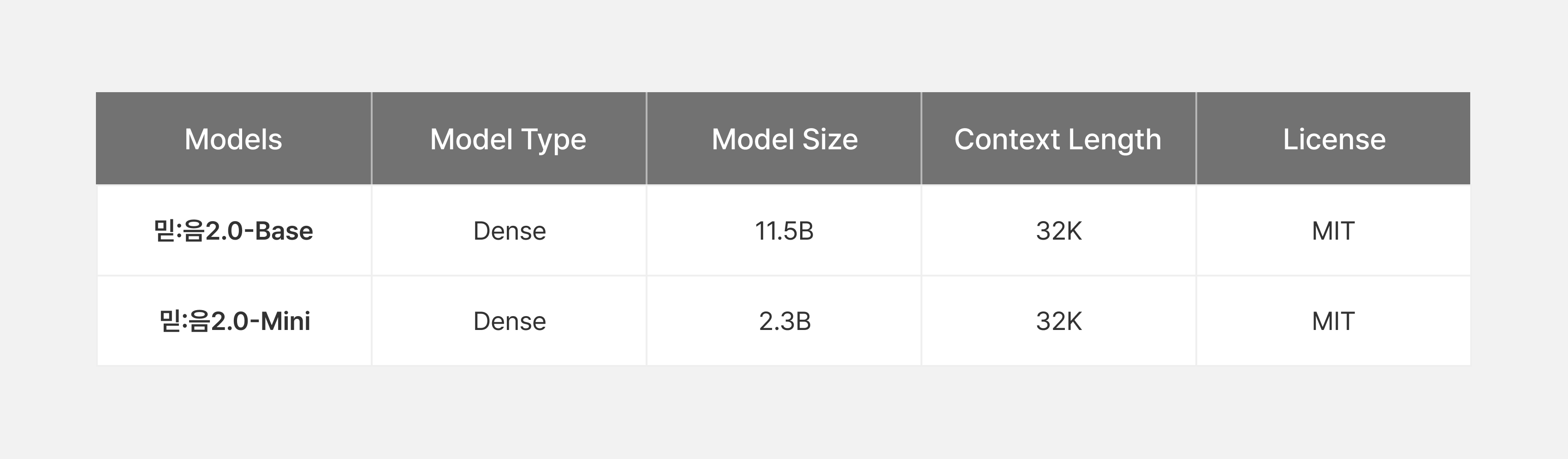
이번에 새롭게 선보이는 믿:음 2.0 모델은 두 가지 버전으로 구성되어 있습니다.믿:음 2.0 Mini는 파라미터 수 2.3B의 소형 Dense 모델로, 2.0 Base 모델을 pruning & distillation하여 스마트폰이나 태블릿 같은 온디바이스 환경에서도 원활하게 사용할 수 있도록 설계되었습니다.믿:음 2.0 Base는 11.5B 파라미터를 가진 모델로, 8B 규모의 모델을 DuS(Depth-up Scaling) [1] 방식으로 확장하였습니다. 다양한 실제 서비스에 적용할 수 있는 실용적인 모델로, 성능과 범용성을 모두 고려했습니다.
2. 믿:음 2.0 학습 데이터
한국어는 영어에 비해 수집 가능한 학습 데이터의 양이 제한적입니다. 또한 쉽게 확보 가능한 데이터들의 품질이 일정하지 않아 잘못 사용할 경우 모델이 오히려 부정확한 표현을 학습할 위험이 있습니다. 이러한 한계를 극복하기 위해, 믿:음 2.0 모델은 KT가 자체 기준으로 엄선한 고품질 텍스트만을 활용하여 학습되었습니다. 저희는 일관된 문맥, 높은 가독성, 완결된 문서 구조를 갖춘 데이터를 고품질의 기준으로 설정하고, 이 기준에 부합하지 않는 데이터는 과감히 제외했습니다.
모델 학습 전반에 걸쳐 책임감 있는 인공지능(Responsible AI)를 중요 시 하였습니다. 모든 데이터는 출처와 라이선스를 철저히 검토한 후 사용되었으며, 개인정보나 민감 정보가 포함되지 않도록 세심하게 관리했습니다. 수집된 데이터는 KT의 다단계 필터링 파이프라인을 거쳐 학습에 적합한 고품질 데이터만을 선별했습니다. 이렇게 정제된 데이터는 믿:음 2.0 모델뿐만 아니라 Microsoft와 협력하여 개발한 GPT-K 모델 학습에도 사용되어 데이터의 신뢰성과 활용 가능성이 검증되었습니다.
이처럼 안전하고 신뢰할 수 있는 데이터만을 사용함으로써, 믿:음 2.0 모델은 윤리성과 안정성을 모두 충족하는 모델로 개발될 수 있었습니다.
데이터 분류 체계

고성능 언어 모델을 훈련시키려면 학습 데이터를 정밀하게 분석하고 체계적으로 관리하는 것이 필수적입니다. 하지만 현재까지 공개된 연구 중에는 한국어 데이터를 심층적으로 분석한 사례가 드물어, 추가 데이터 확보나 모델 성능 지표 해석에 어려움이 많았습니다. 이러한 한계를 극복하고자 저희는 자체적인 데이터 분류 체계를 수립했습니다. 이 체계를 활용해 도메인, 언어, 문체, 스타일 등 다양한 기준으로 데이터를 분류하고 있으며, 수집 및 사용된 데이터에 대한 통계 정보도 지속적으로 관리하고 있습니다.
그림 1에 제시된 바와 같이, 믿:음 2.0 모델의 사전 학습 데이터에는 KT가 자체 구축한 도메인 분류 체계가 적용되었습니다. 해당 분류 체계는 인문사회, STEM(과학, 기술, 공학, 수학), 응용 과학, 식품보건, 생활문화, 기타의 6가지 대분류와 세분화된 20가지 중분류로 구성됩니다. 이 분류를 통해 데이터의 주제별 특성을 명확히 파악하고, 모델 학습에 최적화된 데이터를 체계적으로 관리하고 있습니다. 또한 각 분야 별 성능을 측정하고 부족한 부분이 무엇인지 분석하는데 활용되고 있습니다.
데이터 필터링
데이터 필터링은 방대한 데이터 중 학습에 사용할 데이터를 선별하는 핵심 작업입니다. 언어모델 성능에 가장 큰 영향을 미치는 요소가 학습 데이터이기 때문에, 데이터의 양보다는 품질을 최우선으로 엄격하게 선별해야 합니다. 하지만 대규모 문서 데이터를 정제하는 작업은 많은 시간과 비용이 소요됩니다. 이를 해결하기 위해 KT는 빠르고 정확한 필터링이 가능한 6단계 이상의 자체 데이터 정제 파이프라인을 구축하여 실제 학습에 적합한 고품질 데이터만을 효율적으로 선별할 수 있는 체계를 마련했습니다. 이를 통해 "KT 고품질 대규모 코퍼스" 데이터셋을 구축했습니다.
KT의 고품질 데이터란, 문맥을 해치는 특수기호나 문장이 없고 자연스럽게 해석 가능한 완결된 문서 구조를 갖추고 있으며, 유해한 정보가 없고, 무엇보다 상업적 이용이 가능한 라이선스를 보유한 데이터를 의미합니다. 다단계 정제 체계를 통해 구축된 KT 고품질 데이터는 문맥적 자연스러움과 논리 구조의 완결성을 갖추었습니다. 또한 교육적으로 활용 가능한 고유의 가치를 지닌 콘텐츠로 구성되어 있어, 사전학습 모델의 성능과 활용성을 동시에 향상시키는 데 핵심적인 역할을 하고 있습니다.
데이터 합성
저작권 문제가 없는 공개 한국어 데이터는 전체 수량 부족과 도메인 편중이라는 구조적 한계를 가지고 있습니다. 대규모 영어 문서 코퍼스와 비교할 때, 한국어 공개 데이터는 약 0.13%에 불과한 적은 규모로 알려져 있으며, 그마저도 인문·사회 계열에 치중되어 있는 실정입니다. 반면, 물리, 수학, 컴퓨터 과학, 의료 등 고난이도 전문 도메인에서는 극심한 데이터 결핍 현상이 나타납니다. 이러한 편향은 KT 내부의 도메인 분류기를 통해 실증적으로 분석되었으며, 실제로 믿:음 모델의 초기 벤치마크 평가에서도 해당 도메인에 대한 상대적 낮은 성능이 명확히 드러났습니다. 이에 KT는 언어·도메인 편향을 동시에 완화하기 위해 저작권에 위배되지 않는 데이터셋을 활용하여 다각도의 합성 데이터를 구축하였습니다.
첫째, 한국어 코퍼스의 수량 확장을 위한 Topic-based Rewriting 전략을 도입했습니다. 둘째, 단순 수량 확장을 넘어 구조적 다양성 문제를 해결하는 방향으로 데이터 포맷과 문장 구조를 다양화했습니다. 셋째, 수학 및 프로그래밍 등 사고력 중심 과제에서는 Long Chain-of-Thought(longCoT) 방식의 합성 문서를 구축하여, 문제 해결 과정을 논리적으로 계획하고 단계별로 설명 및 검증하는 구조를 학습하도록 했습니다. KT는 이처럼 도메인, 포맷, 문장 구조의 다변화를 통해 단순한 수량 확장을 넘어서 편향 완화, 학습 효용 극대화를 동시에 달성하고자 했으며, 이는 실제 모델 성능의 균형성과 범용성을 개선하는 데 중요한 기여를 했습니다.
3. 믿:음 2.0 사전학습(Pretraining)
믿:음 2.0의 가장 큰 특징은 제한된 한국어 데이터와 연산 자원 환경에서도 높은 수준의 언어 성능을 구현할 수 있도록 설계된 전략적 학습 단계에 있습니다. 기존의 한국어 특화 LLM들과 비교했을 때, 믿:음 2.0은 제한된 컴퓨팅 환경에서 타 모델 대비 적은 양의 연산으로 우수한 한국어 이해 및 생성 성능을 달성했습니다. 이는 비교적 적은 연산 자원으로 충분히 실용적인 모델을 구축할 수 있음을 보여주는 사례입니다.
믿:음 2.0 모델은 믿:음 2.0 Base, 믿:음 2.0 Mini 두 가지 버전으로 제공됩니다. 두 모델은 유사한 사전학습 전략을 공유하며, 파이프라인은 크게 세 단계 - Stage 1, Stage 2, Long-context 학습으로 구성됩니다. 각 단계는 모델의 언어 이해와 생성 능력을 점진적으로 확장하는 데 초점을 맞추고 있습니다.
한국어 특화 토크나이저
토크나이저는 언어모델의 성능뿐만 아니라 학습 시 연산 효율에도 직접적인 영향을 미치는 핵심 요소입니다. 특히 한국어는 다른 언어들과 달리 여러 형태소와 단어가 결합되어 의미가 결정되는 특성을 가지고 있습니다. 이 때문에 많은 한국어 토크나이저는 사전 형태소 분석을 통해 pre-tokenization을 수행하는 방식으로 설계됩니다. 하지만 이런 방식은 전체 데이터에 대해 형태소 분석을 적용할 경우 토크나이저의 압축률을 오히려 떨어뜨리는 문제가 발생할 수 있습니다. 이를 해결하기 위해 형태소 전체가 아닌 조사에 대해서만 선별적으로 pre-tokenization을 적용하는 전략을 선택했습니다.
또한 믿:음 2.0 모델은 한국어와 영어 모두에 효과적인 Bi-lingual BBPE(Byte-level BPE) [2] 방식을 기반으로 토크나이저를 설계했습니다. 이러한 방식은 한국어 고유의 문장 구조를 유지하면서도 토크나이저의 압축 효율을 높여 모델의 학습 및 추론 효율 향상에 기여할 수 있습니다. 아래 표는 한국어 데이터에서 각 토크나이저의 압축률 결과입니다. 믿:음 2.0 토크나이저는 기존의 외국 모델은 물론 한국어 특화 모델과 비교해도 모든 한국어 도메인에서 가장 우수한 압축률을 보여줍니다.
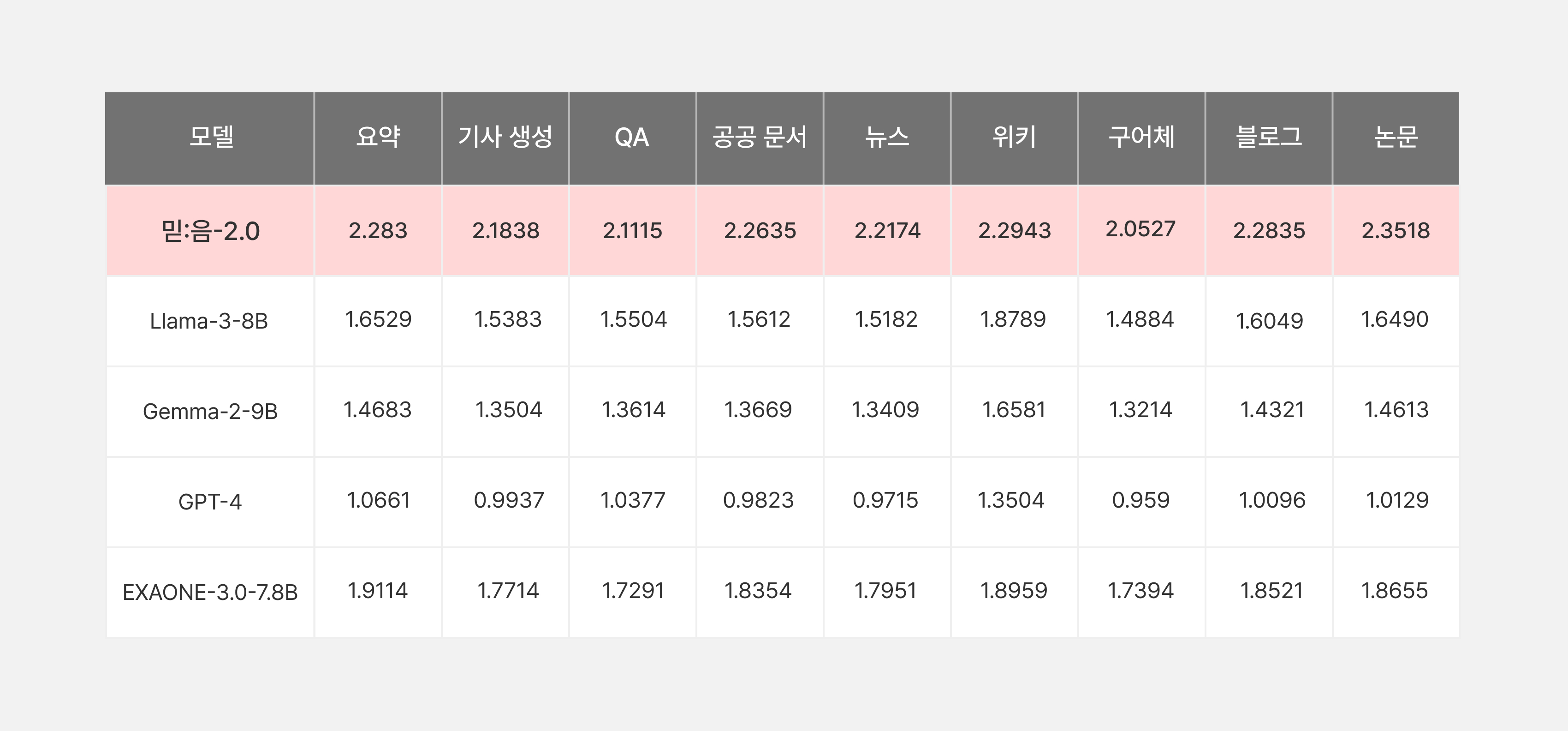
표2. 한국어 데이터 압축률 비교(character per tokens)
토크나이저의 압축률은 동일한 문장을 얼마나 적은 수의 토큰으로 표현할 수 있는지를 나타내는 지표로, 모델의 학습 효율과 성능에 직접적인 영향을 미치는 요소입니다. 압축률이 높을수록 더 많은 정보를 동일한 컨텍스트 길이 안에 담을 수 있어 더 적은 토큰으로 더 많은 정보를 표현할 수 있으며, 이는 학습 효율 향상과 추론 속도 개선에 도움이 됩니다. 한국어 특화 토크나이저는 믿:음 2.0 모델의 문맥 유지 능력, 추론 정확도, 학습 효율성 전반을 개선하는 핵심 요소로 작용합니다. 덕분에 믿:음 2.0 모델은 복잡한 문법 구조나 긴 문맥을 포함한 한국어 텍스트에서도 보다 안정적이고 정확한 학습과 추론이 가능합니다.
믿:음 2.0 Base
믿:음 2.0 Base 모델은 제한된 연산 자원과 상대적으로 적은 한국어 데이터로도 높은 수준의 언어 능력을 확보하기 위해 설계된 범용 모델입니다.
특히, 믿:음 2.0 Base는 동일한 자원 내에서 학습 효율을 극대화하기 위하여 개발되었습니다. 성능과 학습 효율성을 고려하여 초기에 8B 규모로 학습한 다음 DuS(Depth-up Scaling) [1] 기법을 적용해 성능을 한층 개선하였습니다. DuS 기법은 기존 모델의 특정 레이어를 복사하여 수직적으로 쌓는 구조 확장 방식으로, 새로운 모델을 처음부터 다시 학습하는 대신 기존 학습 자원을 효과적으로 재활용할 수 있다는 장점이 있습니다. 이는 대규모 모델을 처음부터 학습하는 방식에 비해 계산 자원 측면에서 훨씬 효율적이며, 제한된 조건에서도 높은 성능을 달성하도록 설계되었습니다.
DuS 기법에서 가장 중요한 요소는 확장할 Layer를 선택하는 것 입니다. 이에 믿:음 Base 8B 모델을 구성하는 총 32개 Layer 를 후보로 실험을 진행하였습니다. 각 Layer의 Forward 과정에서 Layer 입력 전후 Embedding 값의 Cosine 유사도가 높은 구간을 선택하였습니다 [3]. 높은 Cosine 유사도는 해당 레이어가 중요한 문맥 정보를 효과적으로 보존하고 있음을 뜻합니다. 결과적으로 12번째부터 27번까지의 Layer를 대상으로 확장하여 총 48개 Layer를 가지는 모델을 설계하였습니다. DuS 확장 이후 추가 학습을 수행하지 않은 초기 모델을 대상으로 실험한 결과, DuS 확장 이전과 유사한 수준의 성능을 확인하였습니다.
또 하나의 중요한 요소는 믿:음 Base 8B 모델 학습의 어느 단계에서 확장할지 결정하는 것입니다. 믿:음 Base 8B 모델도 2 Stage 학습을 수행하였습니다. 이 중 Stage 1 학습 종료 후 모델과 Stage 2 학습 종료 후 모델 양쪽을 가지고 각각 확장하여 학습한 결과 Stage 1 학습 종료 단계 이후의 모델이 더 안정적으로 성능이 향상되는 결과를 관찰하였습니다.
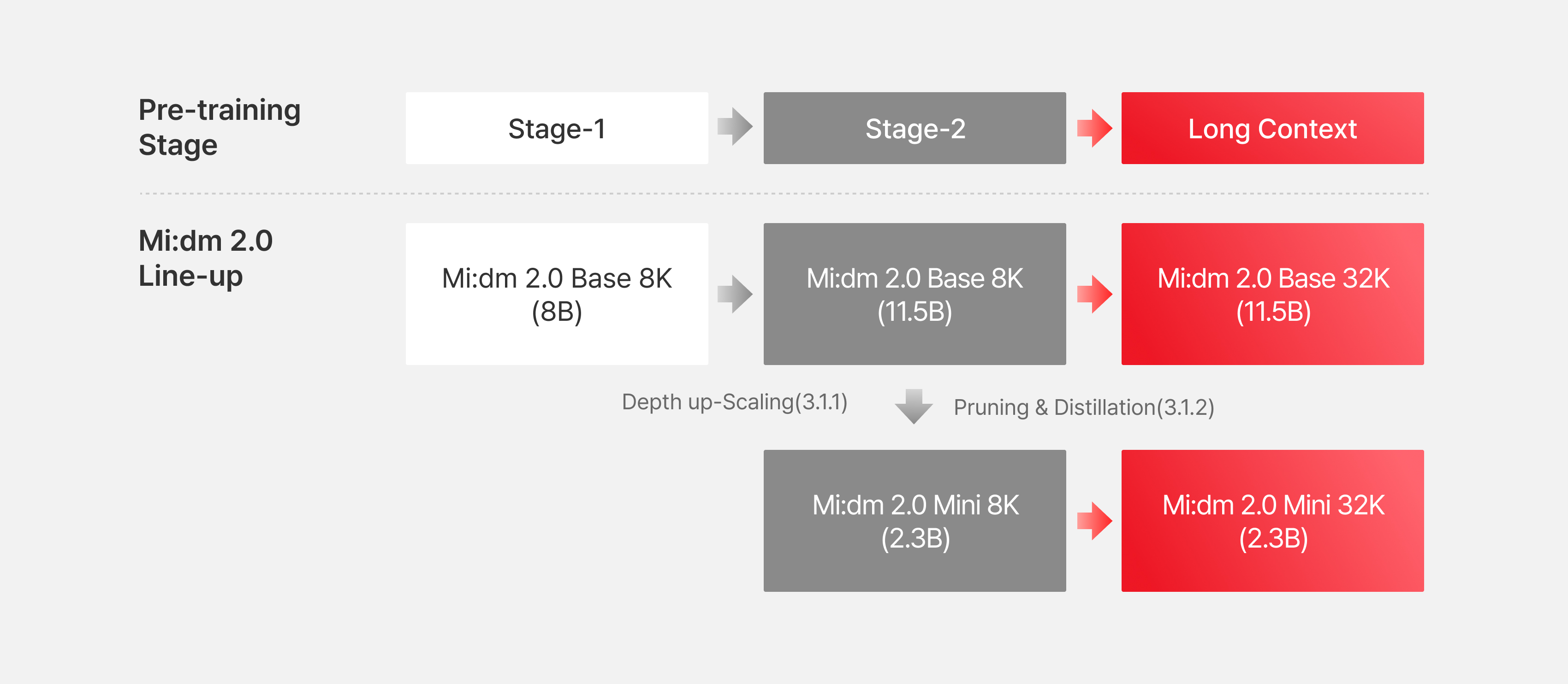
DuS 적용 후, 믿:음 2.0 Base 모델은 2단계에 걸친 사전학습과 Long context 학습을 수행했습니다. Stage-1에서는 확장 이후 모델의 안정화와 일반 지식의 주입을 목표로 하였습니다. 이후 Stage-2 연장 학습을 수행했습니다. Stage-2의 데이터는 Stage-1 후의 특정 고난이도 영역에서 모델 성능을 더욱 끌어올리기 위해 구성되었습니다. 일반 지식 기반의 확장 학습, 수학, 코딩, STEM 영역 중심의 전문 학습, Long-context 처리를 위한 학습을 목표로 데이터의 비율을 달리해 구성한 후 모델을 학습했습니다. 데이터의 비율 뿐 아니라 내부 기준에 따라 더욱 높은 품질을 가진 것으로 판단되는 데이터만 선별하여 이용하였습니다.
긴 질문이나 문서처럼 입력이 길어질수록 앞뒤 맥락을 이해하고 일관된 응답을 생성하는 능력이 중요하기 때문에, 사전학습의 마지막 단계에서는 긴 문맥 처리 능력(Long-context)을 높이기 위한 추가 학습을 진행했습니다. 모델이 최대 32K 토큰 문맥 길이까지 안정적으로 처리할 수 있도록 확장하였습니다.
믿:음 2.0 Mini
믿:음 2.0 Mini는 저사양 GPU, 모바일, IoT, 온디바이스 등 연산 능력이 제한적인 환경에서도 충분한 성능을 발휘하도록 지식 증류(Knowledge distillation)와 가지치기(Pruning)를 결합하여 경량화 및 최적화에 집중한 모델입니다. 소규모 언어 모델 학습 방식은 초기부터 학습하는 'from scratch' 방식과 지식 증류를 활용하는 방식으로 나뉘는데, 지식 증류 방식이 효율성 측면과 더불어 높은 성능을 보이기 때문에 이 방법을 믿:음 2.0 Mini에 적용했습니다.
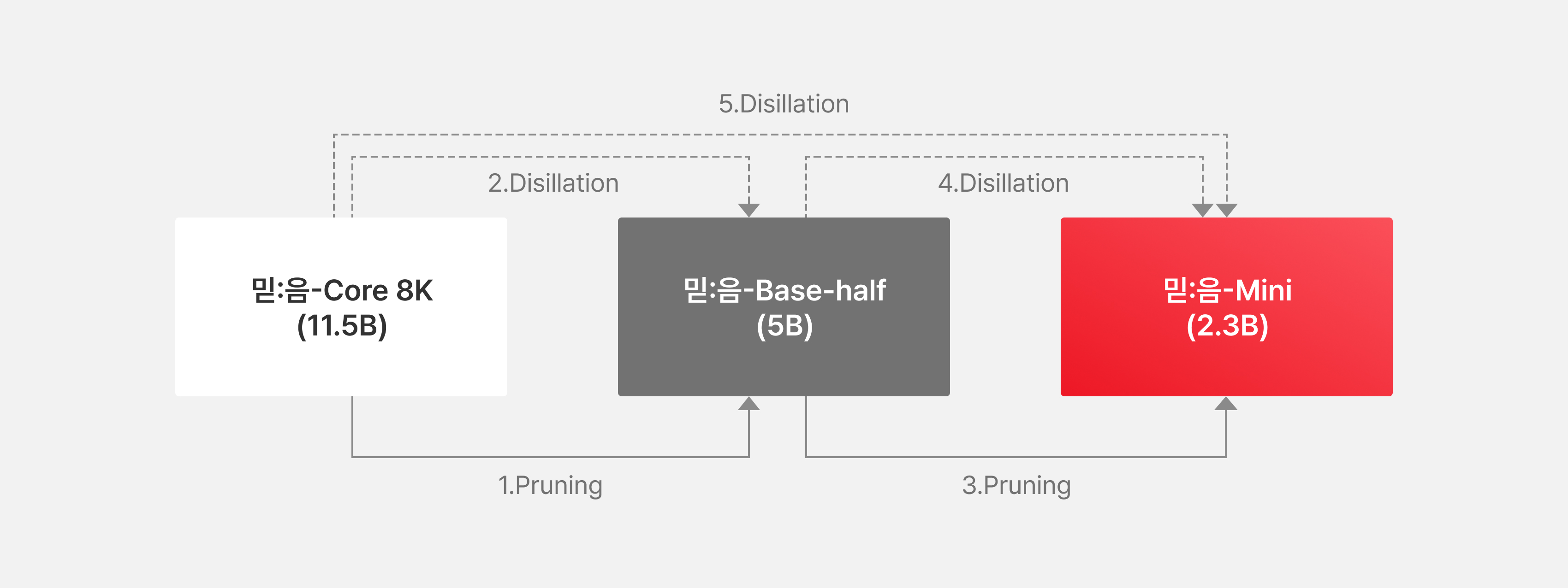
그림4. knowledge Distillation 과정
먼저, 믿:음 2.0 Base 모델에 Width pruning를 적용하여 약 5B 규모의 중간 모델인 Base-half 모델을 구축했으며, 이 Base-half 모델을 Student 모델로, 믿:음 2.0 Base 모델을 Teacher 모델로 하여 약 0.36T 토큰 규모의 1차 증류를 수행하였습니다. 이를 통해 모델 크기를 줄이면서도 중요한 언어 능력을 유지했습니다. 이어서 Base-half 모델을 다시 pruning하고 입출력 임베딩을 병합하여 2.3B 규모의 최종 믿:음 2.0 Mini 모델을 구성했으며, 소규모 모델에서 깊이가 깊은 구조가 성능에 유리하다는 점을 고려하여 믿:음 2.0 Base 모델의 구조적 이점을 계승했습니다. 특히, 믿:음 2.0 Base 모델의 큰 용량(capacity)으로 인한 믿:음 2.0 Mini 모델과의 용량 격차(capacity gap) 및 성능 저하 문제를 해결하기 위해, 다단계 지식 증류 전략을 채택하였습니다. 이는 믿:음 2.0 Mini 모델을 Student로 설정하고 Base-half 모델(작은 Teacher)을 활용한 0.5T 토큰 규모의 1차 증류를 먼저 수행하여 학습 비용을 절감하고 용량 격차의 영향을 완화한 뒤, 이어서 믿:음 2.0 Base 모델(큰 Teacher)을 활용한 0.6T 토큰 규모의 2차 증류를 수행하여 모델 성능을 더욱 향상시키는 방식으로 진행되었습니다. 이러한 다단계 증류 과정을 통해 믿:음 2.0 Mini 모델은 온디바이스 환경에서도 고성능을 유지하도록 효과적으로 경량화되었습니다.
4. 믿:음 2.0 사후학습(Post-training)
기본 원칙
사전학습만으로도 언어 모델은 기본적인 언어 이해와 생성 능력을 갖추게 됩니다. 하지만 실제 서비스 환경에서는 더 섬세한 지시 이행, 논리적 추론, 최신 정보 반영, 도구 연동, 안전성, 그리고 긴 문맥 처리 등 여러 실질적 요구가 존재합니다. 실사용 환경에서의 효용성과 신뢰성을 극대화하기 위해, 믿:음 2.0의 사후학습은 다음과 같은 핵심 역량을 강화하도록 체계적으로 설계되었습니다.
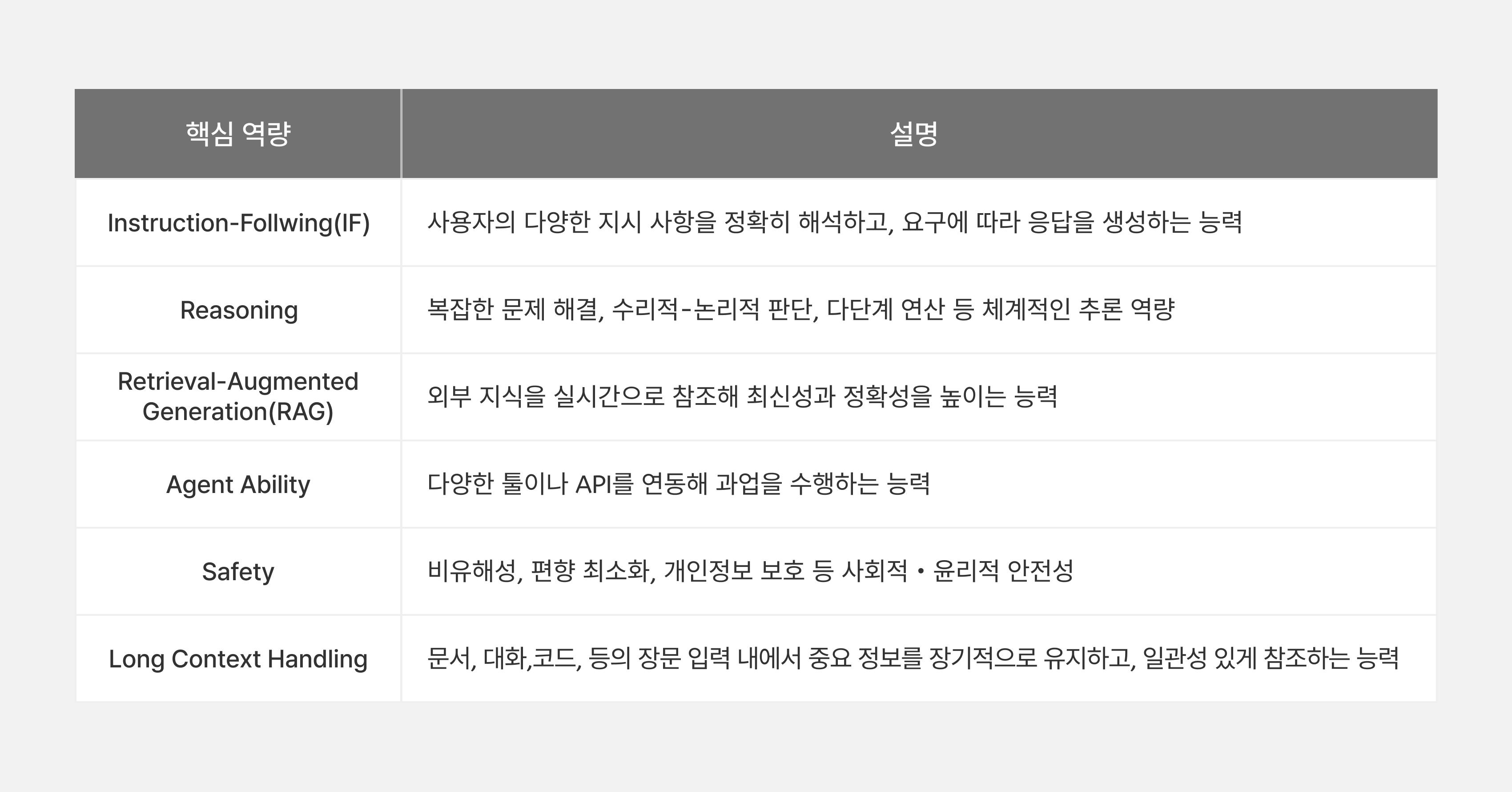
표3. 모델이 갖추어야 할 핵심 역량
각 역량 별 데이터셋 구축 과정에서는 실제 서비스 상황에서의 활용성, 도메인 및 언어적 다양성, 작업의 난이도, 잠재적 편향 및 안전성 이슈 등을 다각도로 고려하여 데이터 파이프라인을 정립했습니다. 이 과정에서 데이터 증강, 필터링, 어노테이션, 품질 평가 등 다양한 자동화 및 수작업 절차를 병행했으며, 고품질 및 저편향 데이터셋을 확보하기 위해 각 핵심 역량별로 분류 체계를 상세하게 정의하여 활용했습니다. 예를 들어, 위 여섯 가지 능력의 토대가 되는 일반 대화 영역에 대해 언어 모델에게 요구되는 다양한 기능을 계층 구조로 체계화했습니다. 그 후, 20개 도메인과 13개 기능을 조합하여 총 260개로 데이터셋을 직교 결합하며 세분화했습니다. 이와 같은 체계화 및 그에 따른 데이터셋 확보의 목표는 특정 영역의 데이터가 과대표집되어 모델의 성능 편향이 발생하는 것을 방지하는 것입니다.
역량별 데이터셋 구축 파이프라인 및 그에 따른 효과는 다음과 같습니다.
- Instruction-Follwing: 사용자 요구를 47개 유형으로 분류한 지시 체계를 기반으로, 다양한 스타일·제약 조건이 반영된 고품질 IF 데이터셋을 자동 생성하는 파이프라인을 설계하였습니다. 이 파이프라인은 다중 제약 질의 생성부터 모델 응답 평가 및 정제까지 다단계로 구성되며, 실제 사용자 시나리오를 반영합니다. 이를 학습에 활용한 결과, IF 관련 내부 벤치마크인 KoIFEval에 대해 기준선 대비 12%p의 성능 향상을 달성했습니다.
- Reasoning: OpenThoughts 방식을 응용해 사고 전개 및 검증 과정을 포함하는 고품질 추론 데이터셋을 구축하였습니다. 최종 정제된 정답만 학습에 사용함으로써, 모델의 수리 및 논리 추론 능력을 체계적으로 강화했습니다. HRM8K, MATH, MMMLU 등에서 최대 19%p 성능 향상을 확인하였습니다.
- Retrieval-Augmented Generation: RAG 능력 확보를 위해 사실·추론 기반 질문 유형을 정의하고, 문서 기반 질의·답변·근거 생성의 정교한 파이프라인을 수립하였습니다. 이 과정은 실세계 복합 질의에 대응 가능한 데이터 신뢰성과 일반화 성능을 모두 확보하는 데 중점을 두었습니다. 이를 통해 문서 기반 질의응답 성능을 실질적으로 향상시켰습니다.
- Agent Ability: MCP 표준 기반의 함수 호출형 대화 데이터를 구축하여, 실생활 주제에 대한 다단계 툴 활용 시나리오를 모델에 학습시켰습니다. 도구 정의부터 예외 처리까지 철저히 반영하여 실제 환경에서 복수 도구 선택·호출 및 사용자 의도 이해가 가능한 에이전트 능력을 구현했습니다. 이로써 믿:음은 실제 서비스 수준의 도구 사용 역량을 갖추게 되었습니다.
- Safety: 비유해성·정직성·AI 역할 일관성의 세 축을 중심으로, 세분화된 가이드라인과 안전 응답 전략을 수립하였습니다. 경계선(borderline) 질의까지 고려한 정교한 응답 체계를 적용하고, 지속적 사후학습을 통해 실질적 안전성 지표에서 24%p의 향상을 이뤘습니다. 이는 사회적·법적 요구에 부합하는 책임 있는 AI 구현의 기반이 되었습니다.
- Long Context Handling: 대규모 합성 데이터를 기반으로, 다양한 문맥 위치에서 질의를 처리할 수 있는 장문 문맥 학습 파이프라인을 설계하였습니다. 이 데이터로 학습된 모델은 NIAH, RULER 등에서 최대 26%p 성능 향상을 보여, 단문 중심 모델 대비 우수한 장문 이해 능력을 입증했습니다.
사전학습에서와 마찬가지로, 이 모든 과정에서 책임감 있는 AI 개발 원칙을 준수하기 위해 라이선스 문제 소지가 있는 데이터셋은 학습 과정에서 완전히 배제했습니다.
사후학습 전략
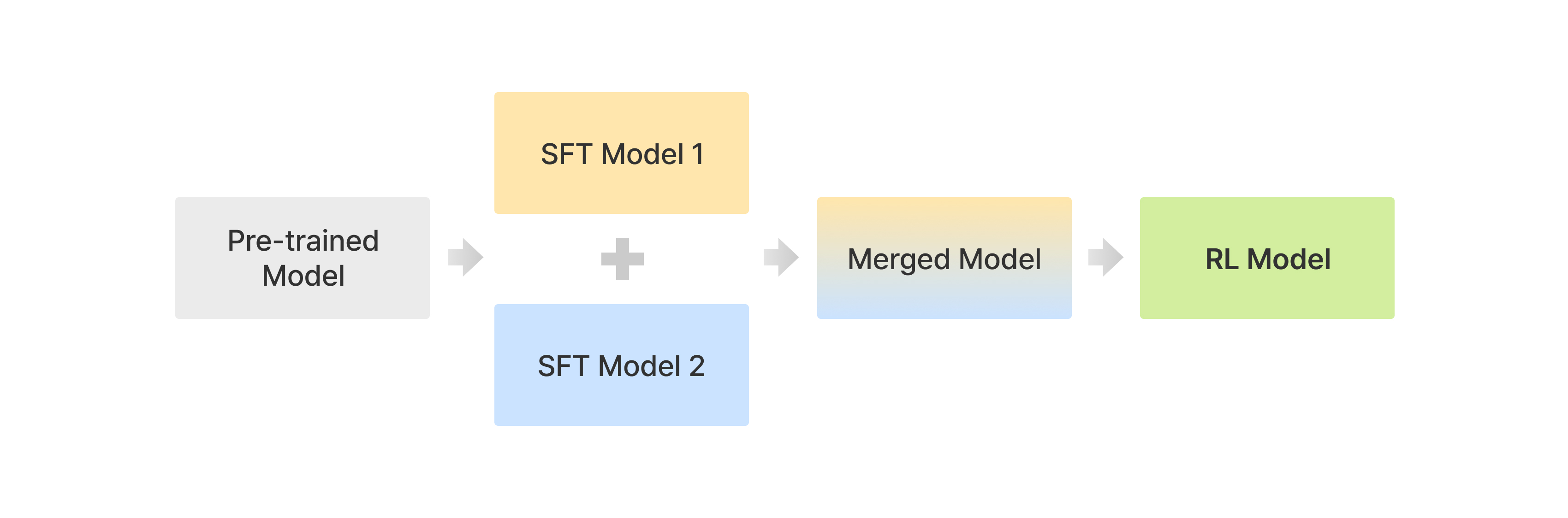
표 3에서 제시한 여러 핵심 역량을 내재화하고자, 믿:음 2.0의 사후학습은 단계별 정렬(alignment) 및 특화를 통해 실제 환경에서 요구되는 다양한 능력을 체계적으로 확보하도록 구성되었습니다. 이는 단순히 기술적 정합성에 그치지 않고, 인간 중심의 응답을 생성하기 위한 정교한 설계 철학에 기반합니다. 아래는 주요 모델 명칭과 각 단계의 역할 및 그에 내포된 목표, 고민을 정리한 것이며, 믿:음 2.0에서 채택한 사후학습 방식은 그림 5에 요약되어 있습니다.
구체적으로, 사전학습된 언어모델을 출발점으로 하여, 다양한 SFT 모델을 독립적으로 구축한 뒤, 이들을 가중치 병합(weight merge) 방식으로 통합하고, 마지막으로 선호 최적화(preference optimization) 단계를 적용하는 일련의 절차를 따릅니다. 각 단계는 고유한 목적을 지니며, 상호 보완적인 역할을 수행합니다.
- SFT Model: Supervised Fine-Tuning(SFT) 단계는 믿:음 2.0의 기초 체력을 형성하는 과정으로, 다양한 도메인과 목적에 따라 설계된 고품질 데이터셋을 활용하여 훈련됩니다. 이 단계의 목표는 전문성과 일반성의 균형을 정교하게 조율함으로써, 실제 사용자 질문에 유연하고 정확하게 대응할 수 있는 기반 역량을 확보하는 것입니다. 여기서의 주요 고민은 다양한 사용자 요구를 만족시키기 위한 범용성 확보와, 특정 사용 시나리오에 특화된 정확성의 유지 간의 긴장 관계를 어떻게 조화롭게 해결할 것인가에 있습니다. 이 단계는 "좋은 응답이란 무엇인가"에 대한 정의를 다각도로 실험하며, 인간의 기대치와 정렬된 응답의 바탕을 다지는 역할을 수행합니다.
- Merged Model: Merged Model은 SFT 단계에서 각각 독립적으로 학습된 모델들의 강점을 가중치 병합 방식으로 통합함으로써, 하나의 모델에 다양한 능력을 융합한 형태입니다. 이 단계의 핵심은 각기 다른 맥락에서 훈련된 모델들이 가지고 있는 상이한 시각과 강점을 충돌이 아닌 상호 보완으로 연결하는 데 있습니다. 모델 간의 융합은 단순한 평균화가 아니라, 성능 저하 없이 특화된 능력을 보존하며 합치는 정합성 유지의 문제를 포함하며, 이러한 고민을 해결하기 위해 계량적 기준과 실험적 검증을 기반으로 융합 전략이 설계되었습니다. 결과적으로, 이 단계는 단일 모델이 다양한 상황에 대해 일관성 있고 품질 높은 응답을 생성할 수 있도록 하는 핵심 연결 고리입니다.
- RL Model: 마지막으로 RL(Reinforcement Learning, 강화 학습)을 통해, 학습한 응답 생성 능력에 인간 또는 AI의 선호(preference)를 반영하여 정렬을 수행했습니다. 여기서의 목표는 단순히 정답을 맞히는 모델이 아니라, 사용자에게 바람직하고 신뢰감을 주는 방식으로 응답하는 모델로 진화하는 것입니다. RL 단계는 모델의 응답이 인간의 가치, 대화의 문맥, 사회적 맥락에 더욱 부합하도록 조율하며, 온라인/오프라인 방식의 학습을 병행함으로써 다양한 피드백 소스를 반영합니다. 이 단계는 "좋은 응답은 정답 이상의 무언가"라는 인식에서 출발하여, 정량적 지표를 넘어선 정성적 품질 향상을 도모합니다.
단계별로 세분화된 학습 전략은 특화와 범용의 균형, 강점의 효율적 융합, 학습 효율성의 극대화, 그리고 핵심 역량에 대한 선호 반영이라는 네 가지 축에서 시너지를 내도록 설계되었습니다. 믿:음 2.0의 사후학습은 결국 기술이 아니라 신뢰할 수 있는 대화 파트너로서의 AI를 구현하고자 하는 문제 의식에서 출발하며, 각 단계는 그 목표를 현실화하는 구체적 전략으로 작동합니다.
이러한 학습 과정을 통해 믿:음 2.0 모델은 균형 잡힌 실용성을 갖추게 되었습니다. 이 과정에서 일반 대화를 수행하기 위한 데이터까지 포함하여, 구축된 전체 사후학습 데이터의 비율은 다음과 같습니다.
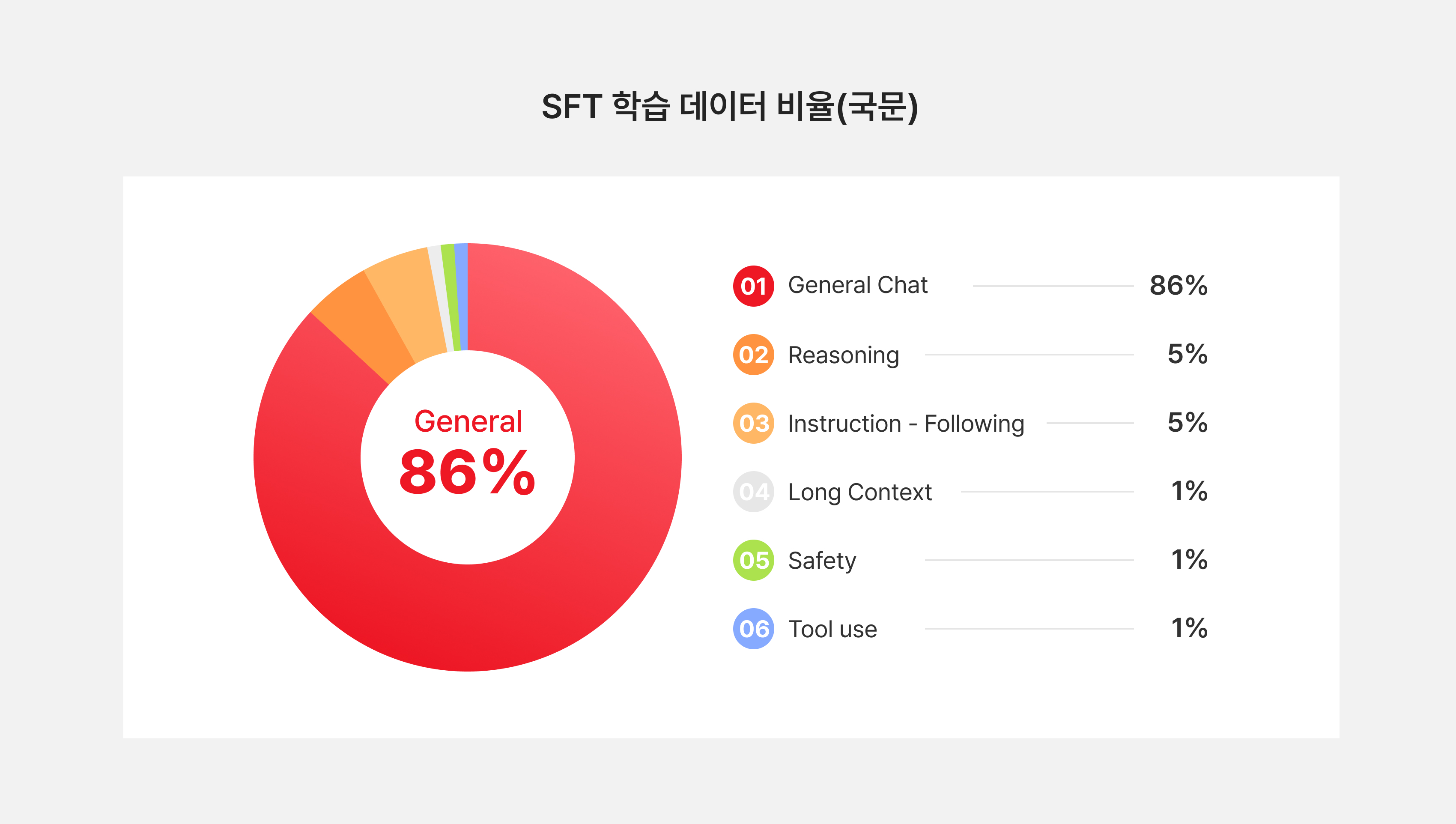
그림6. 한국어 데이터 비율
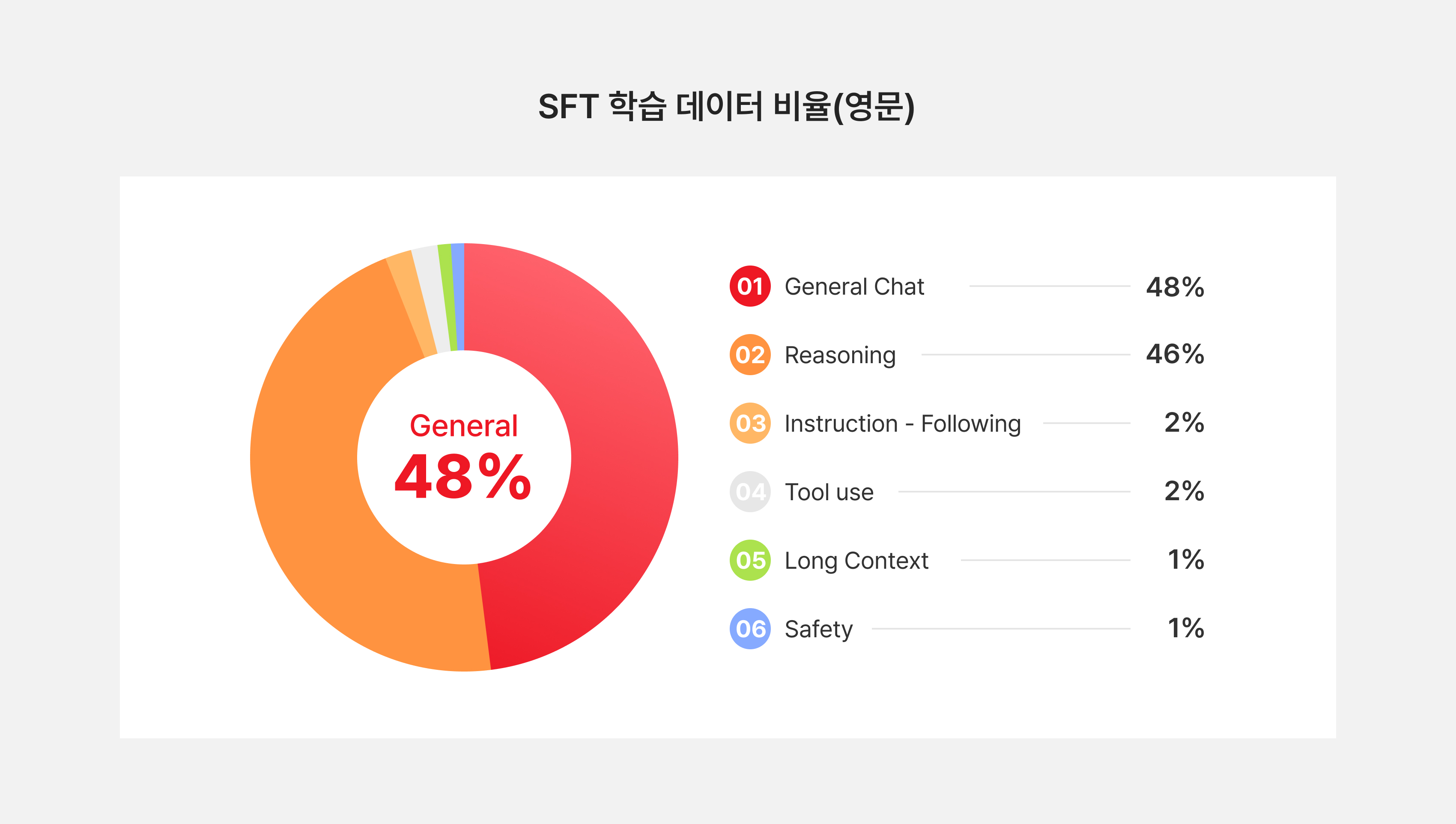
그림7. 영문 데이터 비율
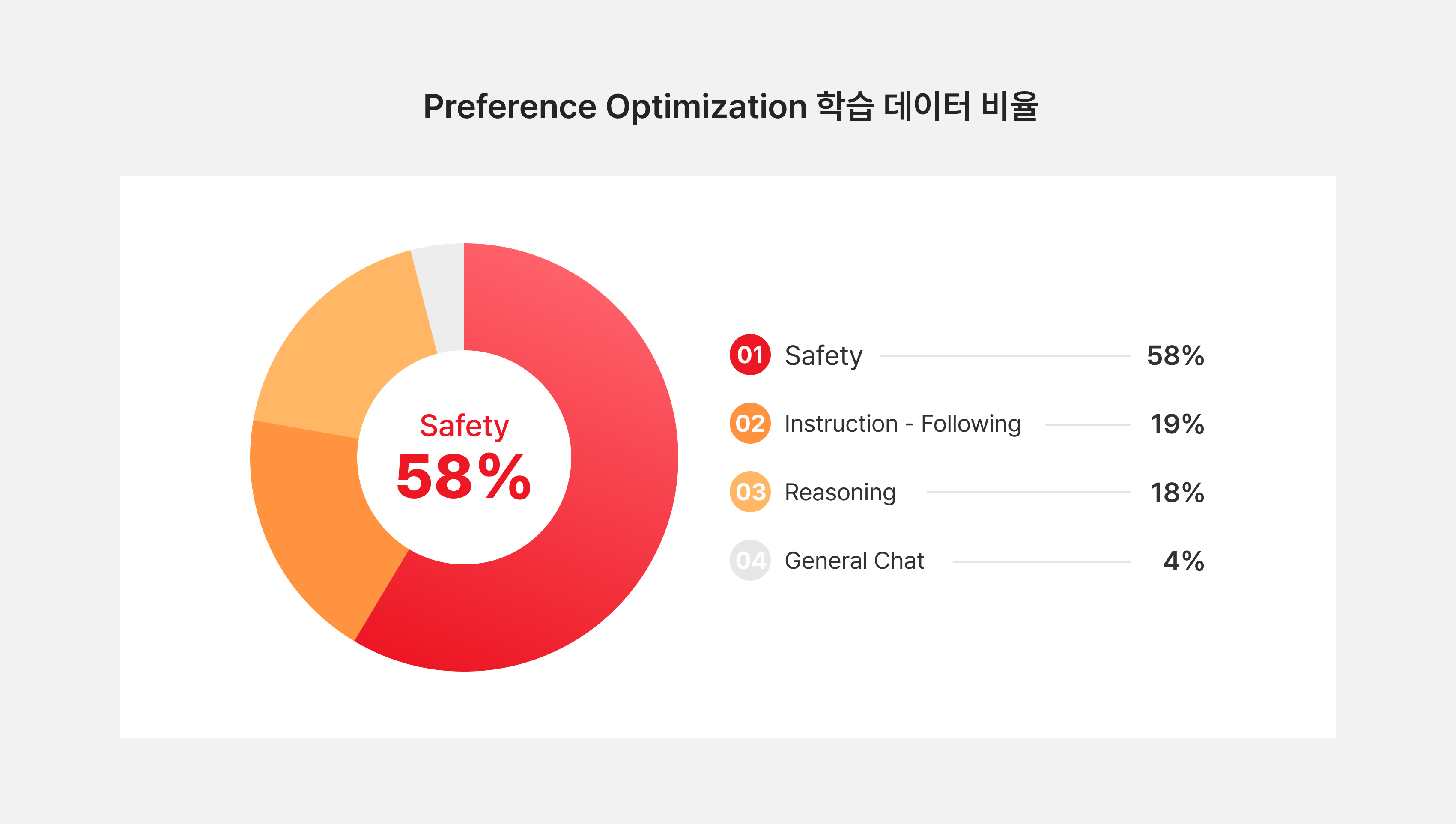
그림8. RL 데이터 비율
실제 학습 시에는 각 영역별로 별도 비중을 할당하여 활용하며, 최적의 비율 탐색을 위해 다양한 사전 실험을 진행했습니다. 예를 들어, 영문 일반 대화 데이터의 학습 비중이 일정 수준 이하로 낮아질 경우, 전반적인 영어 평가 지표에서 성능 저하가 일관되게 관찰되었습니다. 이러한 실험적 근거를 바탕으로 영문 일반 대화 데이터의 비중을 조절하여 재학습을 수행했습니다. 이처럼 반복적인 실험과 성능 분석을 통해 데이터의 언어별, 능력별 배치 구성을 지속적으로 개선해왔으며, 이러한 조정은 실제 사후학습 모델의 일관성, 성능, 안정성 향상에 중요한 역할을 했습니다.
Chat Template
대화형 서비스를 고려하여 멀티턴 상호작용과 역할 분담을 반영하기 위해 Meta의 Llama 4 모델과 동일한 챗 템플릿(chat template) 구조를 채택합니다. 즉, 각 발화는 system, user, assistant, tool과 같이 명확한 역할(role)의 메시지로 구분되며, 단순한 코퍼스 형태가 아닌 멀티턴 대화 기록의 형태로 저장되고, 이 구조를 유지한 채로 학습 및 추론에 활용됩니다.이와 같은 구조적 접근은 모델이 실제 대화형 시나리오를 학습하도록 유도하고, 사용자의 의도 파악, 시스템 지침 준수, 도구 호출 등 복합적 맥락을 효과적으로 처리하는 데 기여합니다. 또한 멀티턴 대화 내에서 일관성을 유지하고, 역할에 따라 문맥을 참조하거나 정보를 적절히 추적하는 능력을 강화합니다.
5. 믿:음 2.0 성능
한국어 성능
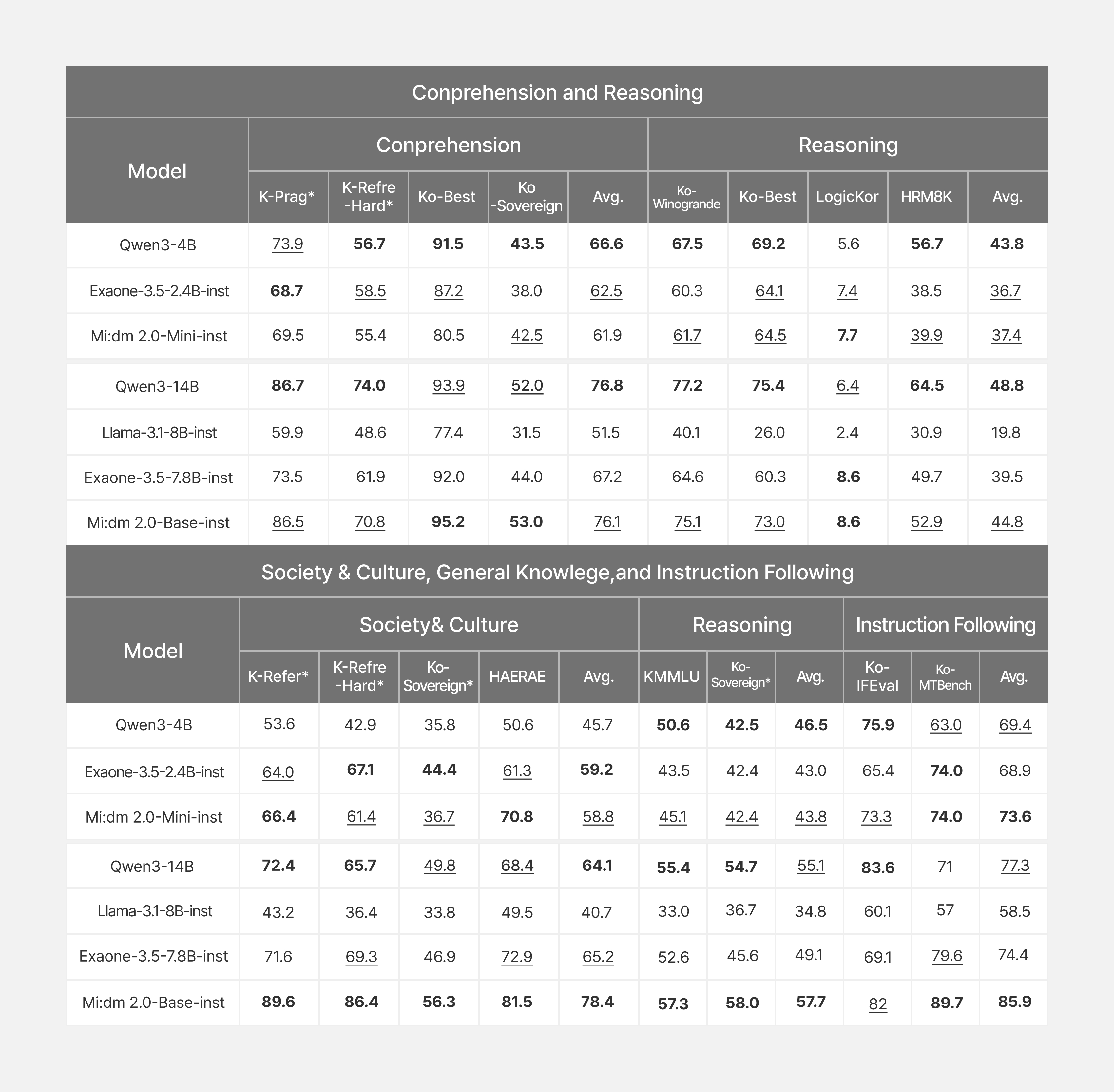
믿:음 2.0은 한국어를 잘하는 것을 넘어 한국 사회의 다양한 분야에 대한 깊은 이해를 갖춘 모델을 목표로 개발되었습니다. 그 결과 한국의 '인문·사회' 영역 이해에서 두드러진 강점을 보입니다. 믿:음 2.0 Base는 역사, 법, 정치, 경제, 금융과 같은 전문 지식을 요구하는 고난이도 평가에서 20% 더 큰 규모의 SOTA 공개 모델인 Qwen-3-14B의 성능을 능가합니다. 이러한 우수성은 한국어 LLM 이해 성능을 평가하는 대표적인 오픈소스 벤치마크인 KMMLU뿐만 아니라, KT와 고려대 민족문화연구원이 공동 설계한 한국형 벤치마크 Ko-Sovereign, 그리고 KT가 자체적으로 구축한 한국어 이해 벤치마크 3종 등에서 우수성을 입증하였습니다.
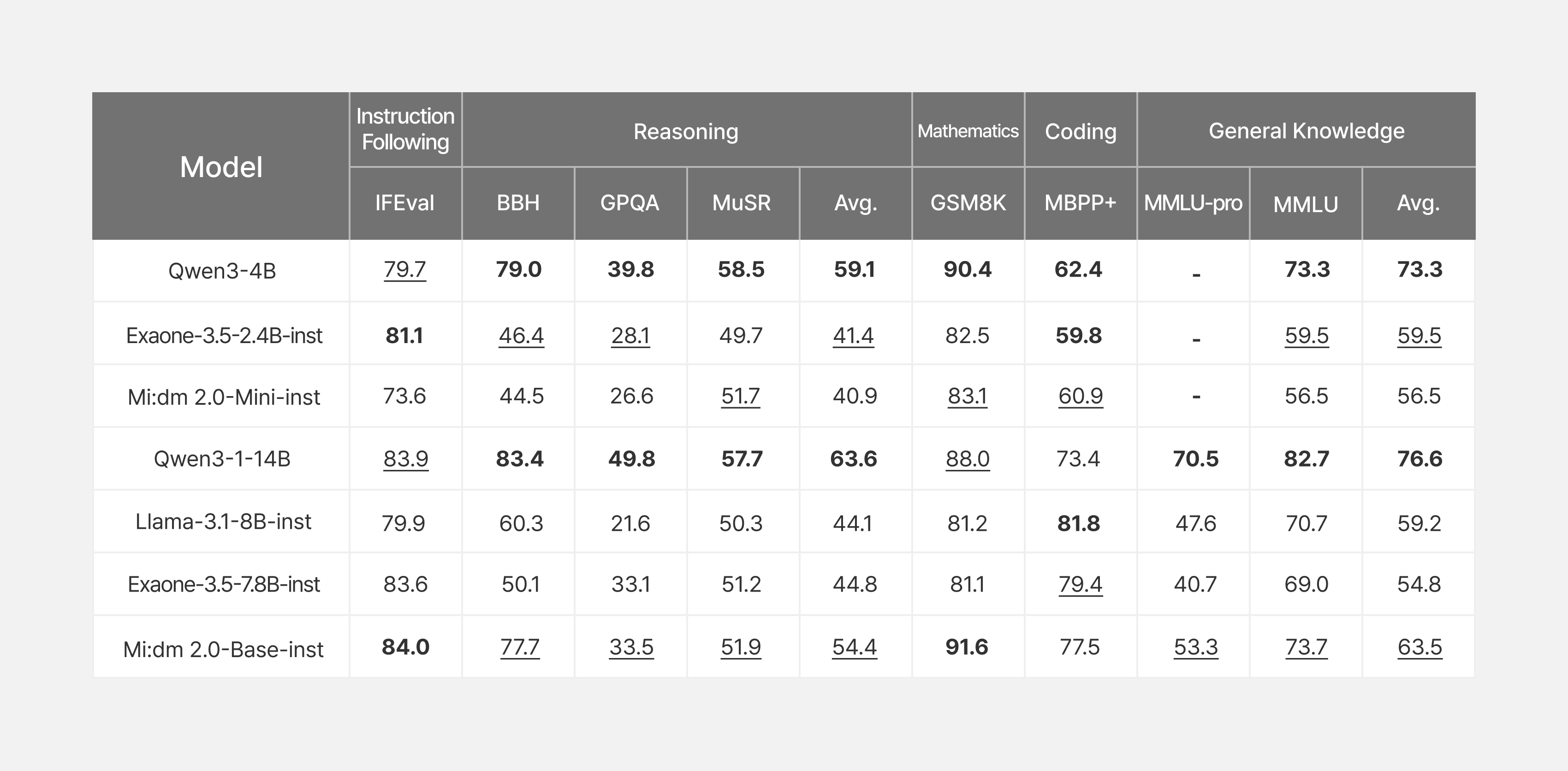
영어 성능
마무리
지금까지 믿:음 2.0 언어모델이 어떻게 개발되었는지, 데이터부터 학습 전략, 모델 구조와 성능까지 전체 과정을 소개해드렸습니다. 믿:음 2.0 모델 공개를 통해 한국의 산업·공공·교육 등 다양한 분야에서 AI 기술이 더 쉽게 활용되기를 바랍니다. 또한 믿:음 2.0 모델이 국내 AI 개발자분들의 아이디어를 현실로 만드는데 도움이 되기를 바랍니다. 앞으로도 다양한 연구 결과와 더 발전된 모델들을 차례로 공개할 예정이니, KT의 고유 언어모델 믿:음에 많은 관심과 기대 부탁드립니다.
Reference
[1] SOLAR 10.7B: Scaling Large Language Models with Simple yet Effective Depth Up-Scaling
[2] Neural Machine Translation with Byte-Level Subwords
[3] Yi: Open Foundation Models by 01.AI