
안녕하세요, KT B2B Agent팀 홍지후, 송윤성 입니다.
저희 팀에서는 소상공인을 위한 컨설팅 및 운영을 지원하는 AI Agent를 중점적으로 개발하고 있습니다. 소상공인 Agent를 개발과정에서 MCP(Model Context Protocol) Sever 에 대한 설계 원칙을 수립하고 샘플 코드를 개발하였는데, 데이터 접근성 향상을 위한 MCP 서버를 어떻게 활용하면 좋을지에 대해 고민한 과정을 소개합니다.
우선은 MCP(model context Protocol)의 개요와 특징을 설명하고, MCP Workflow, MCP 아키텍처, 활용 경험 순으로 설명해 보도록 하겠습니다.
1. MCP(Model Context Protocol) 개요
1.1 개요
개발자라면 누구나 외부 API나 라이브러리를 연동할 때 겪는 파편화의 어려움을 잘 알고 있을 것입니다. 각기 다른 인증 방식, 데이터 구조, API 명세를 파악하고 코드를 작성하는 일은 때로는 핵심 로직 개발보다 더 많은 시간을 소요하게 합니다. 이제 AI 에이전트 개발에서도 비슷한 문제가 대두되기 시작했습니다.
LLM(대규모 언어 모델)이 단순히 채팅 창에 갇혀 과거에 학습한 데이터만으로 답변하는 것을 넘어, 실시간 데이터베이스를 조회하고, 외부 서비스의 기능을 실행하며, 사용자를 대신해 복잡한 작업을 수행하는 'AI 에이전트'로 진화하고 있습니다. 하지만 이때 LLM이 외부 세계와 소통할 표준화된 '언어'가 없다면 어떨까요? 개발자는 특정 LLM이 Notion의 문서를 읽게 하기 위해, 또 다른 LLM이 Jira에 티켓을 생성하게 하기 위해 각기 다른 전용 코드를 작성해야 하는 '통합의 악몽'에 직면하게 됩니다.
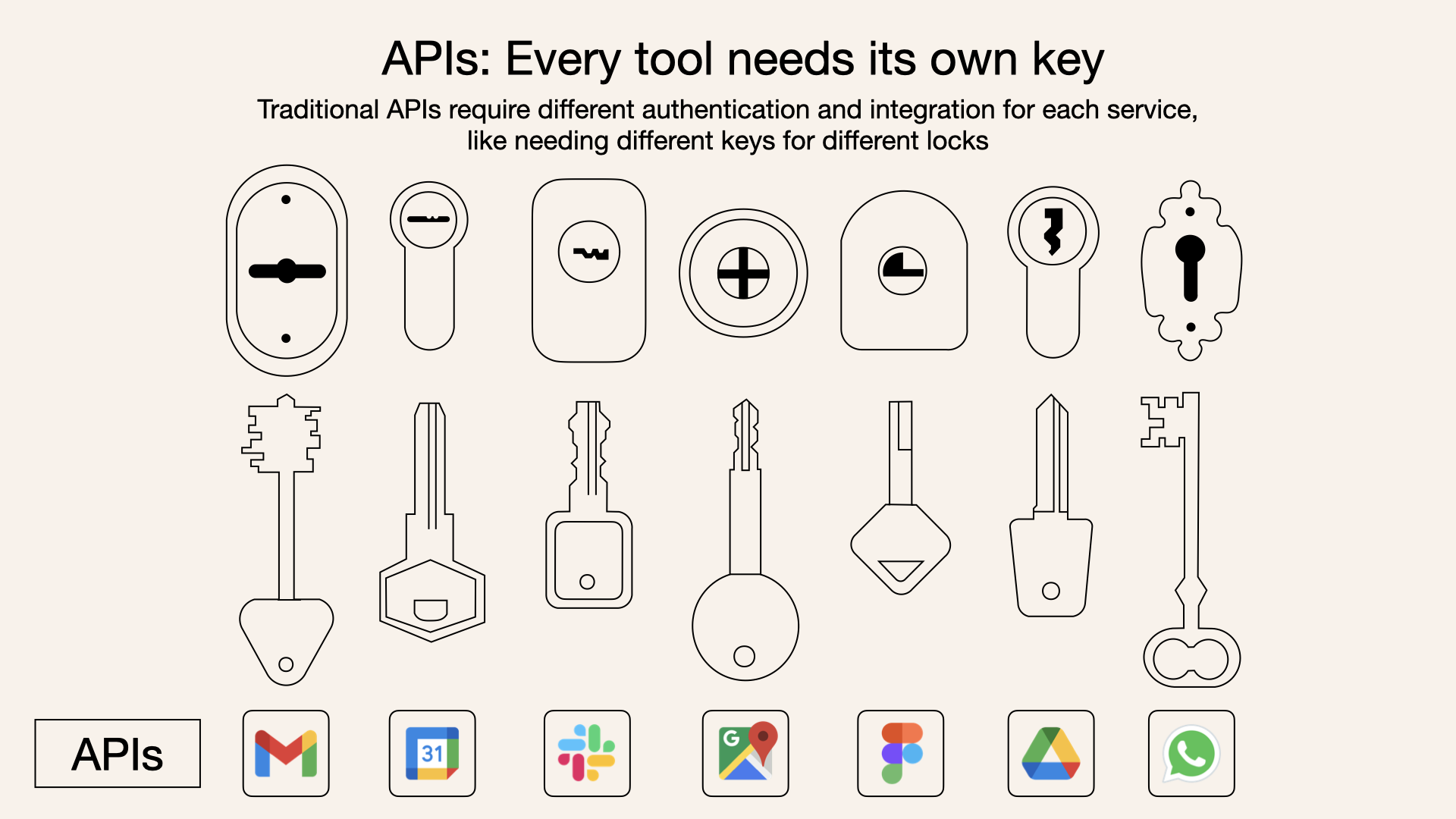
이러한 문제를 해결하기 위해 2024년 11월, Anthropic사는 MCP(Model Context Protocol)라는 개방형 표준 프로토콜을 공개했습니다. MCP를 한마디로 정의하자면 'AI를 위한 USB-C'와 같습니다. USB-C 포트 하나로 충전, 데이터 전송, 영상 출력이 가능하듯, MCP는 AI 모델이 어떤 외부 도구나 데이터 소스와도 표준화된 방식으로 연결될 수 있도록 돕는 범용 인터페이스 역할을 합니다.
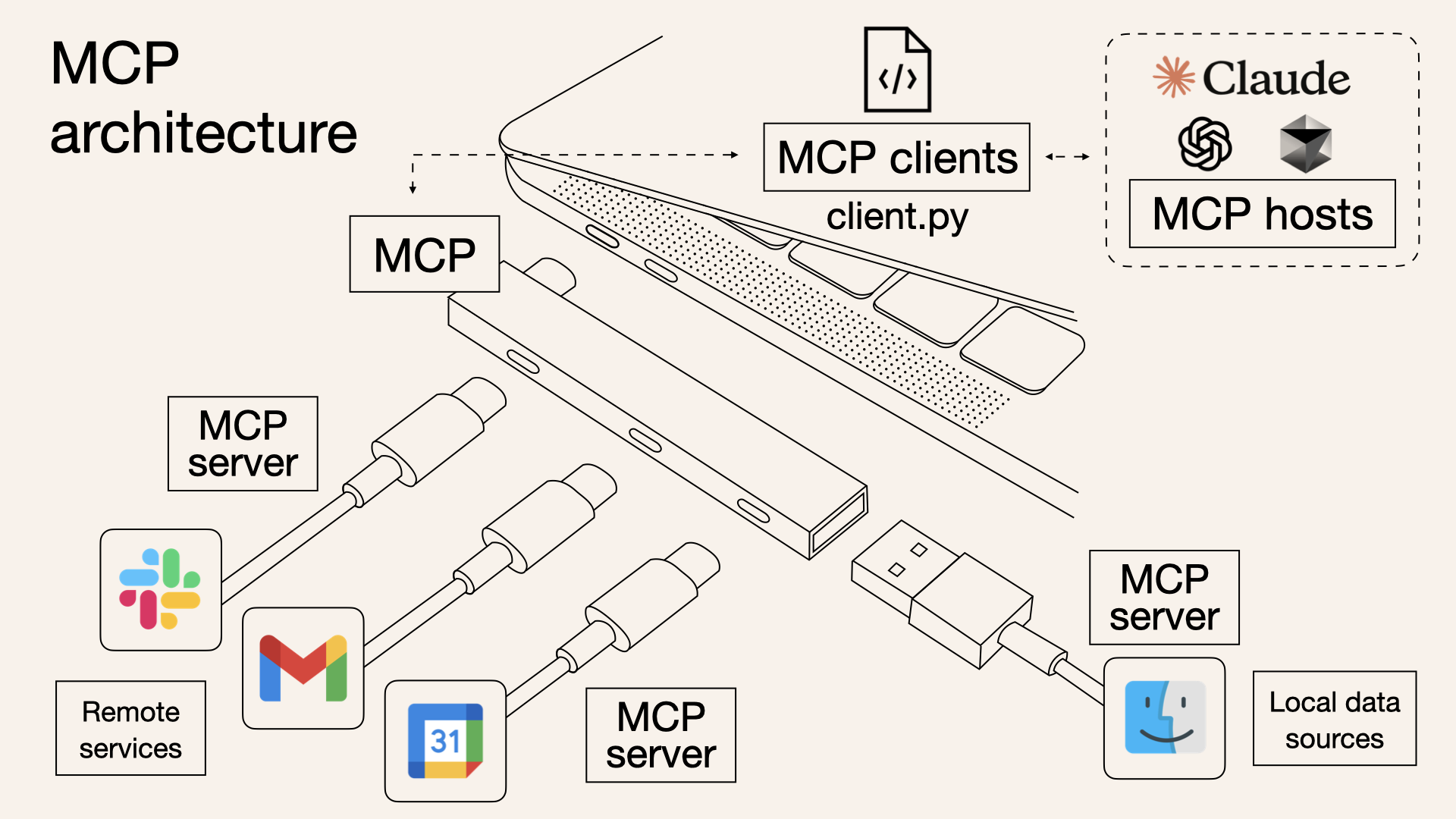
예를 들어, "지난 분기 우리 팀의 성과를 요약해서 보고서를 작성하고 Jira에 공유해 줘"라는 요청을 처리한다고 가정해 봅시다. MCP가 없다면 AI 에이전트는 사내 데이터베이스 API와 Jira API의 사용법을 각각 별도로 학습하고, 개발자는 이를 위한 복잡한 연동 코드를 구현해야 합니다. 반면, 데이터베이스와 Jira가 각자의 기능을 MCP 서버로 제공하고 있다면, AI 에이전트는 표준화된 MCP 형식에 맞춰 두 서버를 호출하고, 그 결과를 종합하여 쉽고 안정적으로 요청을 수행할 수 있습니다.
이처럼 MCP는 LLM과 외부 시스템 간의 소통 방식을 표준화함으로써, 개발자들이 파편화된 연동 문제에서 벗어나 더 창의적이고 강력한 AI 에이전트를 개발하는 데 집중할 수 있는 기반을 제공합니다.
1.2 트렌드 배경 및 현황
MCP는 2024년 11월 공개 직후부터 AI 개발자 커뮤니티의 주목을 받았지만, 그 잠재력이 본격적으로 폭발한 것은 2025년에 들어서면서부터입니다. 변화의 기폭제가 된 것은 AI 네이티브 코드 에디터인 Cursor AI가 2025년 2월 MCP를 공식 지원한다고 발표하면서부터입니다. 개발자들은 자신의 코딩 환경에서 직접 외부 도구와 상호작용하는 AI의 강력함을 체감했고, 이는 MCP에 대한 폭발적인 관심으로 이어졌습니다.
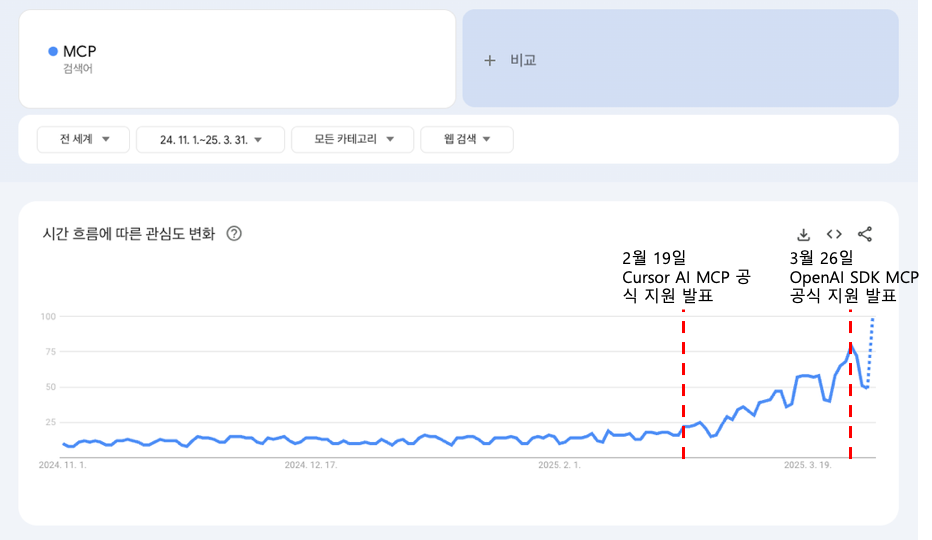
이후 시장의 흐름은 매우 빠르게 전개되었습니다. 2025년 3월, OpenAI가 자사의 SDK에 MCP를 공식적으로 통합하며 이 기술이 일시적인 유행이 아님을 증명했습니다. 곧이어 4월에는 Google이 Vertex AI와 Gemini 생태계 전반에 걸쳐 MCP 지원을 발표하며 거대 기술 기업들의 참여를 공식화했습니다.
이러한 움직임은 AI 생태계 전반으로 확산되었습니다.
-
클라우드 플랫폼: Microsoft Azure, Amazon Web Services(AWS) 등 주요 클라우드 제공업체들이 자사의 AI 서비스에 MCP를 경쟁적으로 도입하며, 기업 고객들이 자사의 데이터와 서비스를 AI 에이전트와 쉽게 연동할 수 있는 길을 열었습니다.
-
개발 프레임워크: AI 에이전트 개발의 양대 산맥인 LangChain과 LlamaIndex는 MCP 서버와 클라이언트를 쉽게 구축할 수 있는 어댑터와 라이브러리를 제공하기 시작했습니다. 이를 통해 개발자들은 기존 개발 환경에서 큰 노력 없이 MCP 생태계에 합류할 수 있게 되었습니다.
-
SaaS 기업: Notion, Figma, Atlassian, Zapier 등 수많은 서비스형 소프트웨어(SaaS) 기업들이 자사 API를 MCP 서버로 제공하기 시작했습니다. 이제 사용자들은 별도의 연동 개발 없이도 자신이 사용하는 AI 비서에게 "Figma 디자인을 기반으로 Notion에 기획서를 작성해 줘"와 같은 복합적인 작업을 시킬 수 있게 되었습니다.
물론, MCP가 모든 문제를 해결하는 '만병통치약'은 아닙니다. 개발자 커뮤니티에서는 "새로운 형태의 API일 뿐 과대 포장되었다"는 비판적인 시각이나, 인증 및 보안 문제에 대한 신중론도 제기되고 있습니다. 하지만 이처럼 빠르게 산업 표준으로 자리 잡아가는 모습은, 과거 웹 개발에서 REST API가 그랬던 것처럼, MCP가 미래 AI 에이전트 개발의 필수적인 기반 기술이 될 것임을 명확히 보여주고 있습니다. 이제 MCP는 단순한 프로토콜을 넘어, 거대한 AI 협업 생태계를 구축하는 핵심 동력으로 작용하고 있습니다.
2. MCP 주요 특징, 아키텍처
MCP는 기능적으로 분리된 세 가지 주요 구성요소가 명확한 역할을 가지고 상호작용하는 우아한 클라이언트-서버 아키텍처를 따릅니다. 이는 마치 잘 설계된 마이크로서비스 아키텍처(MSA)처럼 각 컴포넌트의 독립성과 확장성을 보장합니다.
2.1 주요 구성요소
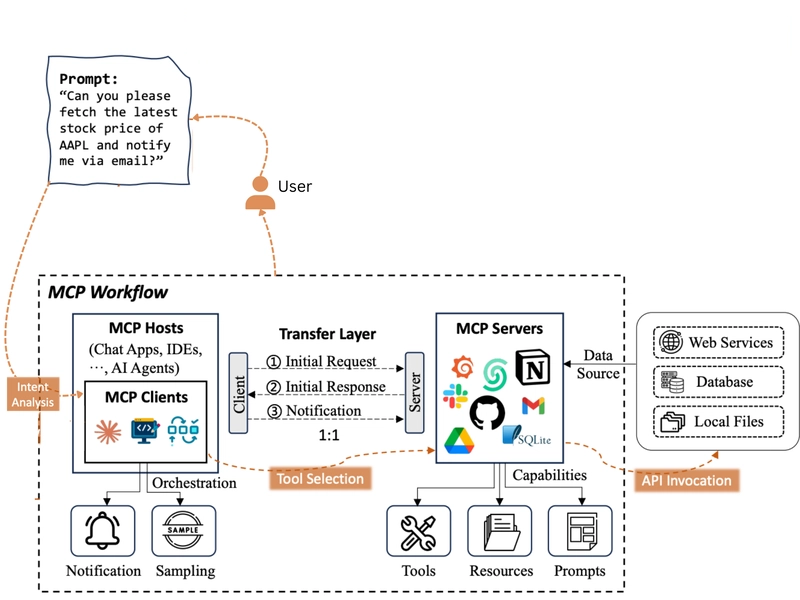
2.1.1 MCP Host: 지휘하는 오케스트라 지휘자
-
역할: 사용자와 직접 상호작용하는 애플리케이션의 주체입니다. Claude 데스크톱 앱, Cursor AI IDE 등이 대표적인 MCP 호스트에 해당합니다.
-
책임:
-
사용자 의도 파악: 사용자의 요청(프롬프트)을 해석하고 어떤 작업이 필요한지 결정합니다.
-
오케스트레이션: 어떤 MCP 서버의 기능(Tool 또는 Resource)이 필요한지 판단하고, 내부의 MCP 클라이언트에게 해당 서버와의 통신을 지시합니다.
-
보안 및 정책 관리: 사용자의 개인정보 보호 설정, 접근 권한, 보안 정책 등을 총괄하며 모든 상호작용이 안전한 범위 내에서 이루어지도록 제어하는 최종 책임자입니다.
-
2.1.2 MCP Server: 독립적인 기능 전문가
-
역할: 특정 도메인의 기능(Tool)이나 데이터(Resource)를 표준화된 MCP 프로토콜에 맞춰 외부에 제공하는 독립적인 서버 애플리케이션입니다.
-
책임:
-
기능 캡슐화: 외부 데이터 소스(예: 사내 DB, Jira API, GitHub API)와의 복잡한 연동 로직을 내부에 감추고, 이를 표준화된 MCP 인터페이스로 외부에 노출합니다.
-
요청 처리 및 응답: MCP 클라이언트로부터의 요청을 받아 실제 작업을 수행(예: DB 쿼리 실행, API 호출)하고, 그 결과를 다시 클라이언트에게 반환합니다.
-
가장 큰 특징은 독립적으로 빌드하고 배포할 수 있다는 점입니다. LangChain 프레임워크에 익숙한 분이라면
ToolNode와 유사한 역할을 한다고 볼 수 있습니다. 하지만 핵심적인 차이점은, ToolNode가 보통 AI 애플리케이션 코드 내에 강하게 결합된 모듈인 반면, MCP 서버는 완전히 분리된 프로세스로 실행되는 네트워크 서비스라는 점입니다. 이러한 분리는 시스템의 유연성과 재사용성을 극대화하는 핵심적인 아키텍처 설계입니다.
2.1.3 MCP Client: 보이지 않는 충실한 메신저
-
역할: MCP 호스트 내부에 존재하며, 실제 MCP 서버와 통신하는 기술적인 부분을 전담하는 내부 통신 모듈입니다.
-
책임:
-
프로토콜 통신: 호스트의 지시에 따라 MCP 프로토콜 규칙에 맞춰 서버에 연결하고, 요청을 직렬화하여 전송하며, 서버로부터 받은 응답을 역직렬화하여 호스트에게 전달합니다.
-
연결 관리: 서버와의 연결 상태를 유지하고, 비동기 통신(예: SSE)이나 JSON-RPC와 같은 저수준의 통신 세부 사항을 처리합니다.
-
사용자나 호스트의 관점에서는 MCP 클라이언트의 존재를 인식할 필요가 없습니다. 클라이언트는 호스트와 서버 사이에서 명령을 충실히 수행하는 '보이지 않는 손'과 같은 역할을 합니다.
2.2 LangChain 기반 아키텍처와의 비교
2.2.1 LangChain Agent에서의 Tools
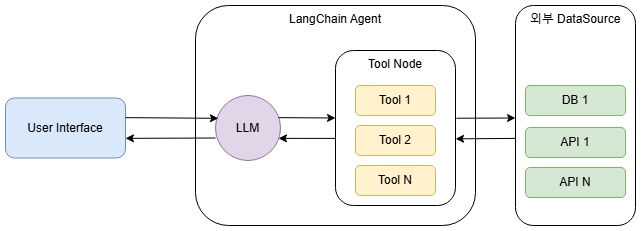
위 그림은 일반적인 LangChain 에이전트의 모습입니다. 핵심은 Tool Node(또는 Tool의 묶음)가 LangChain Agent라는 하나의 애플리케이션 경계 안에 포함되어 있다는 점입니다. 즉, 외부 데이터 소스와 상호작용하는 로직이 AI 에이전트의 메인 코드와 강하게 결합된 모놀리식(Monolithic) 아키텍처에 가깝습니다.
2.2.2 MCP 활용 구성도
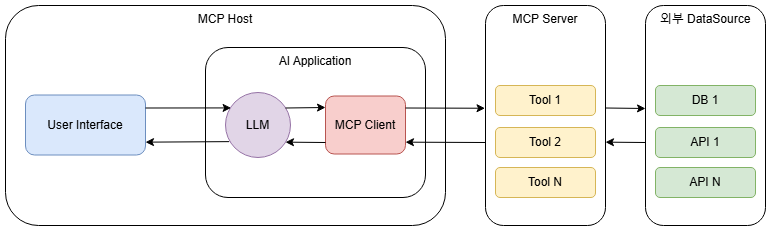
반면 MCP를 활용한 아키텍처는 명확히 다릅니다. 기존의 Tool Node에 해당하는 기능이 MCP Server라는 완전히 독립된 외부 서비스로 분리되었습니다. 그리고 AI 애플리케이션(MCP Host)은 내부에 MCP Client를 두어 이 서버와 통신합니다. 이는 전형적인 분산 시스템 또는 마이크로서비스(Microservices) 아키텍처의 특징을 보여줍니다.
2.2.3 Tool Node vs MCP 무엇이 근본적으로 다른가?
이 두 아키텍처의 차이는 단순히 컴포넌트의 위치 변경을 넘어, 시스템의 유연성, 확장성, 재사용성에 지대한 영향을 미칩니다.
가장 큰 차이는 '결합도'입니다. 기존 방식에서는 Jira API를 호출하는 Tool을 수정하면, AI 에이전트 애플리케이션 전체를 다시 테스트하고 배포해야 할 위험이 있습니다. Tool의 코드가 메인 애플리케이션의 일부이기 때문입니다.
MCP 아키텍처에서는 Jira MCP 서버가 완전히 분리된 서비스이므로, 해당 서버의 내부 로직을 수정하거나 개선해도 MCP Host 애플리케이션에는 아무런 영향을 주지 않습니다. 이는 마치 레고 블록처럼 각 기능(서버)을 독립적으로 개발하고 교체할 수 있게 하여 시스템 전체의 유연성과 안정성을 극적으로 향상시킵니다.
내부 라이브러리 vs 공개 API: 재사용성의 차이
기존 방식의 Tool은 특정 프로젝트를 위한 '내부 라이브러리'와 같습니다. 다른 팀에서 이 Tool을 사용하려면 코드를 가져가거나 복잡한 의존성 문제를 해결해야 합니다.
반면, MCP 서버는 표준화된 명세를 가진 '공개 API'와 같습니다. 일단 한번 잘 만들어두면, 어떤 팀에서 어떤 언어로 MCP Host를 만들든 상관없이 해당 서버의 기능을 즉시 가져다 쓸 수 있습니다. 이는 전사적으로 중복 개발을 방지하고 개발 생산성을 크게 높이는 효과를 가져옵니다.
결론적으로, MCP 아키텍처를 도입하는 것은 단순히 Tool Node를 MCP Server로 바꾸는 것을 넘어, AI 에이전트 시스템을 더욱 성숙하고 확장 가능한 최신 소프트웨어 아키텍처 패러다임으로 전환하는 중요한 과정이라고 할 수 있습니다.
3. MCP Workflow
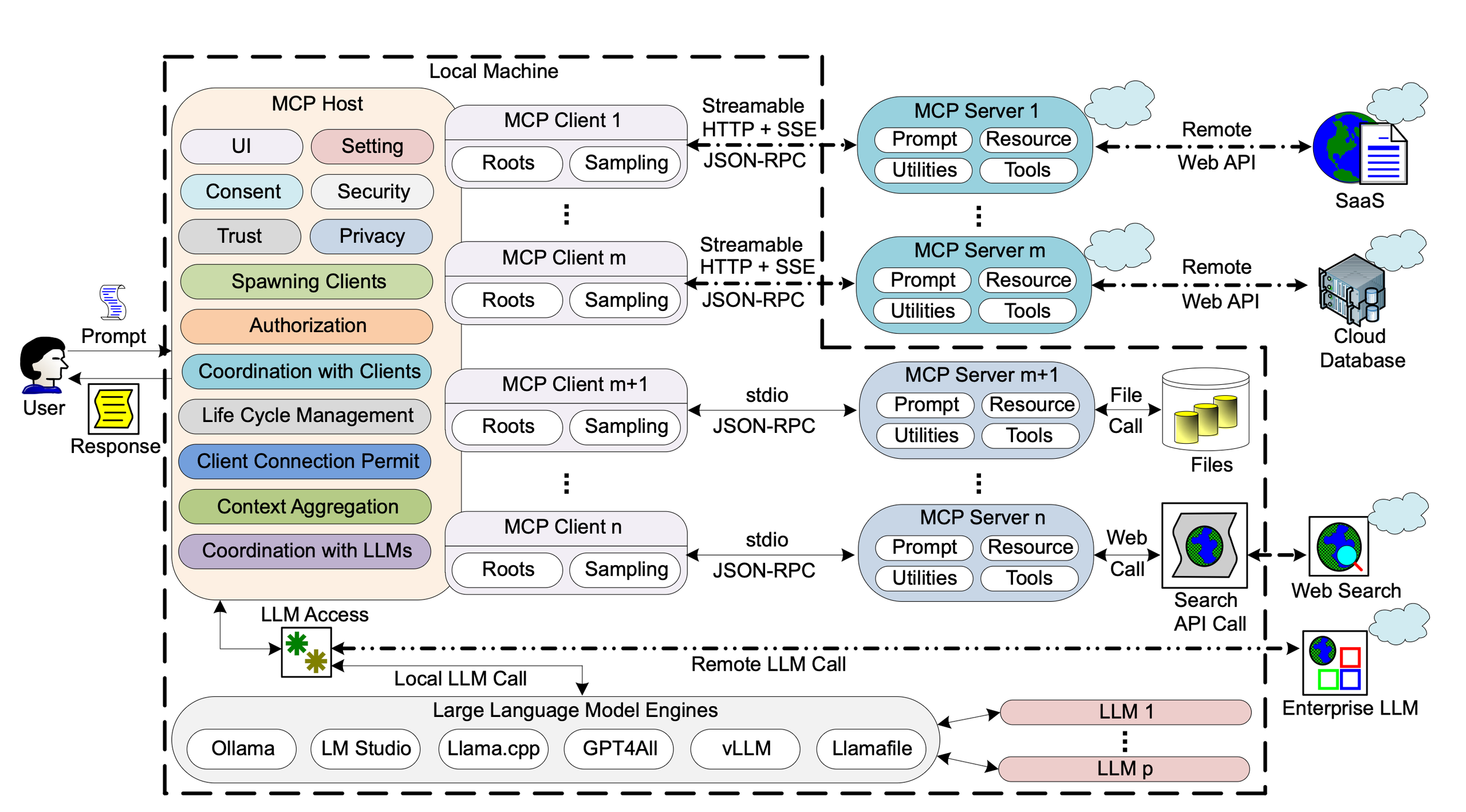
3.1 준비 및 초기화
-
MCP Host
-
인터페이스 제어, 개인 정보 보호 설정, 보안 정책 등 중요한 시스템 설정을 관리합니다.
-
어떤 MCP 클라이언트를 생성하고, 각 Client가 어떤 MCP 서버와 통신할지, 어떤 권한을 가질지를 결정하고 관리합니다.
-
-
클라이언트-서버 연결 및 기능 협상
-
MCP 클라이언트는 MCP 서버와 전용 연결을 맺습니다. 이때 통신 방식은 주로 비동기적 이벤트 처리에 적합한
Streamable HTTP + SSE또는 가볍고 동기적인 메시징에 사용되는stdio기반 JSON-RPC 2.0방식이 사용됩니다. -
초기화 시, 클라이언트는 자신의 기능(예: 파일 접근 'roots', LLM 쿼리 'sampling')을, 서버는 자신이 제공할 기능(프롬프트, 리소스, 도구 등)을 서로에게 알려주고 통신 계약을 맺습니다.
-
3.2 LLM 상호작용을 위한 Context 구축 (Prompt, Resource 활용)
-
LLM이 효과적으로 수행하려면 명확한 지침인 Prompt와 충분한 배경 정보인 Resource가 필요합니다.
-
Prompt는 LLM에게 "어떻게 말하고 행동해야 하는지" 알려주는 구조화된 지침서 또는 템플릿입니다. 이는 사용자의 특정 행동(예: "/요약해줘" 명령어 입력)에 의해 클라이언트 애플리케이션을 통해 명시적으로 요청됩니다.
-
Resource는 LLM의 상호작용을 풍부하게 하는 데 필요한 구조화되거나 구조화되지 않은 데이터(예: 코드 파일, 로그, 문서, API 응답)입니다. 이는 MCP Client에 의해 관리되며, Resource Template을 사용하여 동적으로 외부 소스(DB, API 등)에서 데이터를 가져올 수도 있습니다.
-
-
Prompt Workflow 설명
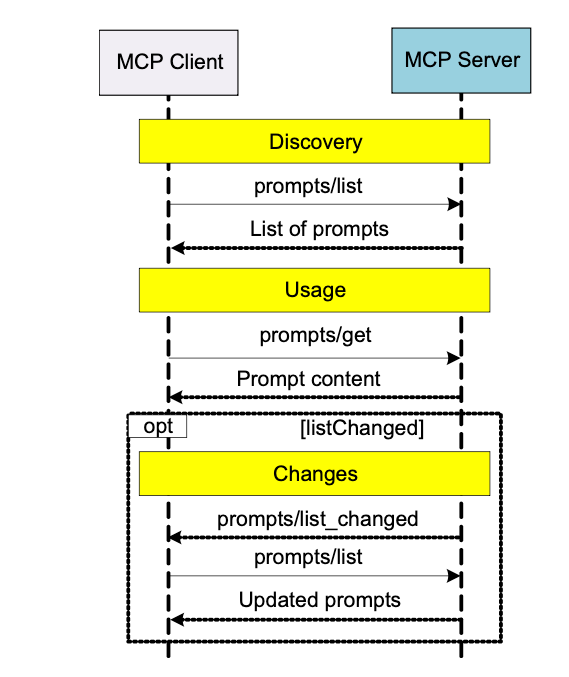
-
1) Client의 Prompt 요청: 사용자가 특정 작업을 지시하면, MCP 클라이언트는 해당 작업에 적합한 프롬프트 템플릿을 MCP 서버에 요청합니다 (예:
prompts/list로 목록을 받고,prompts/get으로 특정 프롬프트 내용을 요청). -
2) Server의 Prompt 제공: MCP 서버는 요청받은 프롬프트 템플릿(예: "다음 내용을 요약하세요: [내용]")을 클라이언트에게 전달합니다.
-
3) Host의 역할 (LLM 전달 전): 클라이언트가 서버로부터 프롬프트를 받으면, 이 프롬프트는 바로 LLM으로 가는 것이 아니라, MCP 호스트에게 전달될 수 있습니다. 호스트는 이 프롬프트가 유효한지, 사용자의 의도에 맞는지 등을 검토하고, 다른 정보(아래 설명될 리소스 등)와 함께 LLM에게 전달할 최종 컨텍스트를 구성합니다.
-
4) (선택) Prompt 변경 알림: 만약 MCP Server의 프롬프트 목록이 변경되면, 서버는 클라이언트에게 이를 알리고 (
prompts/list_changed), MCP Client는 필요시 새 목록을 다시 가져올 수 있습니다.
-
-
-
Resource Workflow 설명
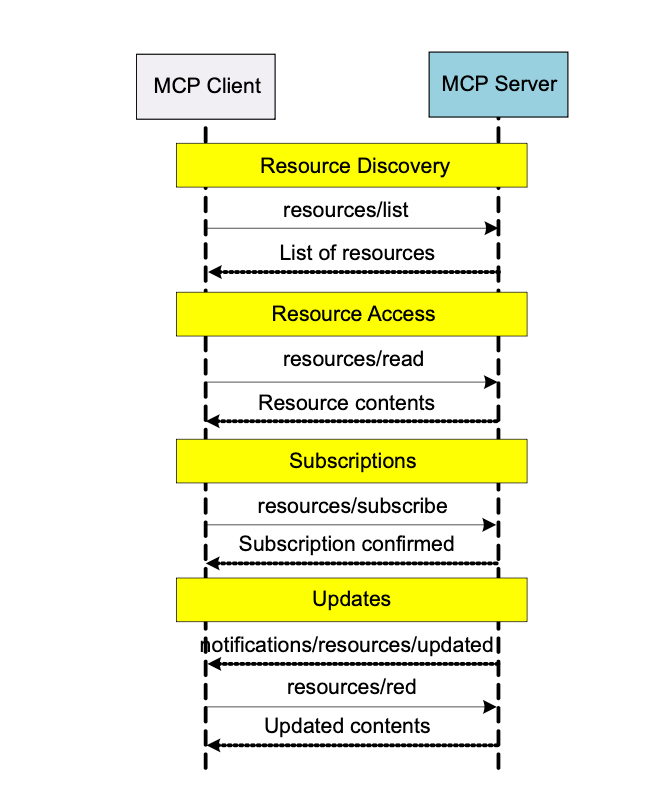
-
1) Client의 Resource 요청: MCP Client는 필요한 리소스 목록이나 특정 리소스의 내용을 MCP 서버에 요청합니다 (예:
resources/list,resources/read). -
2) Server의 Resource 제공: MCP Server는 요청된 Resource(예: 특정 DB 조회 결과, 파일 내용)를 MCP Client에게 전달합니다.
-
3) Host의 역할 (LLM 전달 전): 프롬프트와 마찬가지로, 클라이언트가 서버로부터 리소스를 받으면, 이 정보는 MCP 호스트로 전달되어 LLM에게 제공될 컨텍스트의 일부로 집계됩니다. 호스트는 이 리소스가 LLM의 현재 작업과 관련이 있는지, 사용자 동의는 얻었는지 등을 확인한 후 LLM에게 전달합니다.
-
4) (선택) Resource 변경 구독 및 알림: 클라이언트는 특정 리소스의 변경 사항에 대한 알림을 구독할 수 있고(
resources/subscribe), 변경 시 서버는 클라이언트에게 알려주며(notifications/resources/updated), 클라이언트는 업데이트된 내용을 다시 가져올 수 있습니다.
-
3.3 LLM의 능동적 작업 수행 (Tools 활용)
LLM은 단순히 정보를 수동적으로 받는 것을 넘어, 외부 시스템과 상호 작용하여 실제 작업을 실행하거나 새로운 정보를 능동적으로 가져올 수 있습니다. 이때 '도구'가 사용됩니다.
-
Tools Workflow 설명
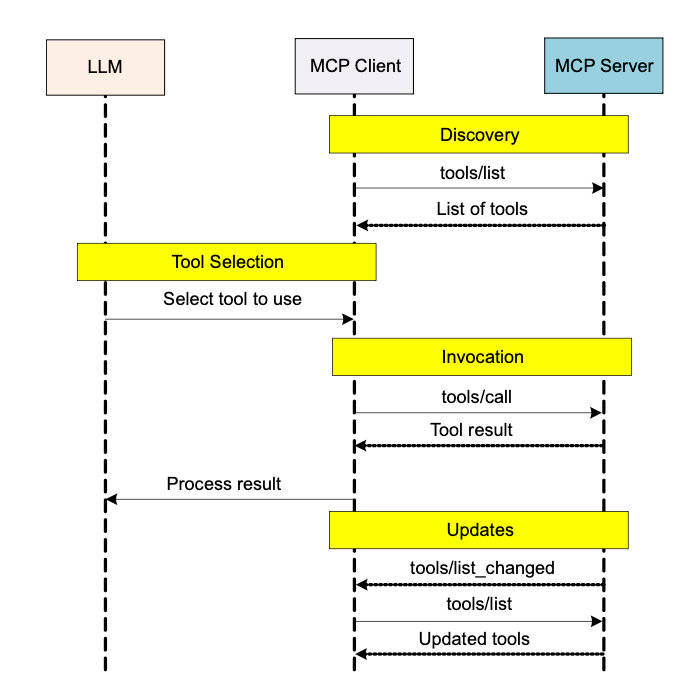
-
1) MCP Client의 도구 목록 획득 (LLM을 위해): MCP 클라이언트는 MCP 서버로부터 사용 가능한 도구 목록을 가져와서 (
tools/list), 이 정보를 LLM이 알 수 있도록 (보통 호스트를 통해) 전달합니다. -
2) LLM의 Tool 선택: LLM은 현재 과제, 사용자 요청, 그리고 이전에 Resource 등을 통해 제공받은 컨텍스트를 종합적으로 판단하여 어떤 도구를 사용할지 스스로 결정합니다. 이 결정은 MCP 클라이언트에게 전달됩니다.
-
3) MCP Client를 통한 도구 호출: MCP 클라이언트는 LLM의 요청에 따라 MCP 서버에 선택된 도구의 실행을 요청합니다 (
tools/call). 이때, 도구에 필요한 매개변수는 LLM이 직접 생성하거나, 이전에 리소스를 통해 얻은 데이터를 기반으로 할 수 있습니다. -
4) MCP Server의 도구 실행 및 결과 반환: MCP 서버는 요청받은 도구를 실행하고, 그 결과를 MCP 클라이언트에게 돌려줍니다.
-
5) 결과를 LLM 전달 및 처리: MCP 클라이언트는 서버로부터 받은 도구 실행 결과를 다시 LLM에게 전달합니다.
-
6) (선택) 도구 변경 알림: 서버의 도구 목록이 변경되면, 서버는 클라이언트에게 이를 알리고(
tools/list_changed), 클라이언트는 필요시 새 목록을 LLM을 위해 다시 가져올 수 있습니다.
-
3.4 LLM 호출 및 최종 응답
-
하이브리드 LLM 호출: MCP 시스템은 필요에 따라 로컬 LLM 또는 원격 LLM을 지능적으로 선택하여 사용합니다.
-
호스트의 최종 제어: MCP 호스트는 LLM 호출 직전에, 클라이언트가 가져온 프롬프트와 리소스, 그리고 필요시 도구 사용을 통해 얻은 정보까지 모두 종합하여 최종 컨텍스트를 구성하고, 이것이 사용자 동의 및 정책에 부합하는지 확인한 후 LLM을 호출합니다.
-
LLM은 이 최종 컨텍스트를 바탕으로 추론하여 응답을 생성하고, 이 응답은 다시 호스트를 거쳐 사용자에게 전달됩니다.
이처럼 MCP workflow는 MCP Host의 지휘 아래 클라이언트와 서버가 각자의 역할을 수행하며, 프롬프트와 리소스로 LLM을 위한 풍부한 Context를 구축하고, LLM이 직접 도구를 활용하여 능동적으로 작업을 처리하는 과정을 포함합니다. 이를 통해 LLM은 단순한 챗봇을 넘어 실제 세계와 상호작용하는 지능형 에이전트로 기능할 수 있게 됩니다.
4. 데이터 접근성 향상을 위한 MCP Server 아키텍처 설계 경험
4.1 설계 원칙
4.1.1 '행위'와 '상태'의 근본적 분리
MCP가 거대 언어 모델(LLM)이 세상과 상호작용하는 방식을 '행위(Action)'와 '상태(State)'라는 두 가지 개념으로 근본적으로 구분한다는 것입니다.
-
Resources (
@mcp.resource): 시스템의 '상태(State)'를 나타내는 '명사(Noun)'-
역할: 시스템의 현재 상태를 변경하지 않는 안전한 읽기 전용(read-only) 데이터 조회를 담당합니다. 예를 들어 파일 내을 읽거나, 데이터베이스의 정보를 가져오는 작업이 이에 해당합니다. 이러한 작업은 몇 번을 호출해도 시스템에 아무런 변화를 주지 않는 '부수 효과가 없는(Side-effect-free)' 특징을 가집니다.
-
개념: REST API의
GET메서드와 철학적으로 동일합니다. -
목적: LLM에게 판단에 필요한 '상황 정보(Context)'를 제공하는 것입니다.
-
-
Tools (
@mcp.tool): 시스템을 변경하는 '행위(Action)'를 정의하는 '동사(Verb)'-
역할: 시스템의 상태를 변경하거나 이메일 발송처럼 외부에 영향을 주는 '행위(Action)'를 수행합니다. 파일을 쓰거나, 데이터베이스 레코드를 수정하거나, 외부 API를 통해 메시지를 전송하는 등의 작업이 포함됩니다. 이러한 작업들은 잠재적인 '부수 효과(Side Effect)'를 가집니다.
-
개념: REST API의
POST,PUT,DELETE메서드에 해당합니다. -
목적: LLM이 특정 '행동(Action)'을 직접 수행하도록 하는 것입니다.
-
-
Prompt:
-
역할 : LLM과의 상호작용 흐름 및 LLM이 수행해야 할 작업의 구조화된 지침 또는 템플릿을 캡슐화하여 LLM에게 "어떻게 행동해야 하는지"를 안내합니다.
-
주로 사용자의 명시적 요청이나 정해진 시나리오에 따라 MCP 클라이언트를 통해 서버에서 해당 Prompt 템플릿을 가져오고, MCP 호스트는 이 템플릿과 실제 데이터(예: Resource로부터 얻은 정보)를 결합하여 LLM이 이해하고 작업을 수행할 수 있는 완성된 지침으로 만들어 LLM 호출 시 활용합니다.
-
이러한 컴포넌트 분리 설계를 통해, 데이터 소스의 변경은 Resource 컴포넌트 내에서, 분석 로직이나 외부 시스템과의 연동 방식 변경은 Tools 컴포넌트 내에서, 그리고 대화 흐름이나 LLM 작업 지시 방식의 수정은 Prompt 컴포넌트 내에서 독립적으로 이루어질 수 있습니다.
4.1.2 제어 주체의 분리: 중대한 보안 및 안정성 함의
Tools와 Resources를 분리해야 하는 가장 결정적인 이유는 '누가 제어하는가'의 주체를 명확히 하여 보안과 안정성을 원천적으로 확보하기 위함입니다
-
Resources는 애플리케이션이 제어합니다 (Application-controlled)
-
제어의 주체는 클라이언트 애플리케이션(예: 데스크톱 앱)입니다.
-
클라이언트 앱이 "이 파일(Resource)의 내용을 컨텍스트에 포함해 줘"라고 서버에 능동적으로 요청합니다.
-
이 과정에서 LLM은 직접 관여하지 않고, 제공된 정보를 그저 수동적으로 받기만 합니다.
-
-
Tools는 언어 모델이 제어합니다 (Model-controlled)
-
제어의 주체는 LLM입니다.
-
LLM이 사용자와의 대화 흐름 속에서 특정 작업이 필요하다고 스스로 판단하여 "이 Tool을 이런 인자(arguments)로 실행해야겠다"고 결정하고 클라이언트에게 실행을 요청합니다.
-
이를 통해 데이터 접근 계층(Resources)과 비즈니스 로직 계층(Tools)을 완전히 분리하여, 시스템의 유연성을 극대화하고 유지보수 비용을 극적으로 낮출 수 있습니다.
4.2 구현 사례
4.2.1 고객 주문 목록 조회 사례
전자상거래 시스템에 다음과 같은 Tool과 Resource가 있다고 가정해 보겠습니다.
-
get_customer_orders: 특정 고객의 주문 목록을 사용자 ID로 조회하는 Resource -
_get_customer_sensitive_info: 특정 고객의 개인정보를 사용자 ID로 조회하는 비공개 Resource -
get_customer_full_summary: 특정 고객의 개인정보와 주문정보를 종합해서 전달하는 Tool
모든 것을 Tool로 구현하는 잘못된 설계
Tool 함수 내부에 고객 정보와 주문 정보를 데이터베이스에서 직접 조회하는 로직을 만들었고 어느 날, 회사의 정책이 바뀌어 고객 정보를 기존 데이터베이스가 아닌 외부 마이크로서비스 API를 통해 가져오도록 변경해야 한다면 어떻게 될까요? 개발자는 get_customer_full_summary Tool 뿐만 아니라 해당 정보를 사용하는 모든 Tool을 찾아서 데이터베이스 접속 코드를 지우고, 새로운 HTTP API 호출 코드로 각각 수정해야 합니다. 만약 고객 정보를 사용하는 Tool이 10개라면, 10개의 파일을 모두 수정해야 하는 끔찍한 상황이 발생합니다. 이는 버그를 유발할 가능성이 매우 높고 유지보수가 어렵습니다.
-
올바른 설계 (Resources와 Tools 분리):
-
먼저, 고객 주문 정보를 조회하는
@mcp.resource를 하나 만듭니다 -
다음과 같은 샘플 데이터가 있다고 가정하겠습니다.
JSON▼CUSTOMERS_SENSITIVE_DATA = { "1001": {"name": "케이티", "phone": "010-1234-5678"}, "1002": {"name": "빌게이츠", "phone": "010-8765-4321"}, } CUSTOMER_ORDERS_DATA = { "1001": ["Premium Keyboard", "MacBook"], "1002": ["8K Monitor", "RTX5090"], }12345678Python▼# 데이터 접근을 전담하는 Resource @mcp.resource("ecom://customers/{customer_id}/orders") def get_customer_orders(customer_id: str) -> str: """ 특정 고객의 주문 목록을 JSON 문자열 형태로 조회합니다. """ print(f"[Resource] ecom://customers/{customer_id}/orders 호출됨") orders = CUSTOMER_ORDERS_DATA.get(customer_id, []) # 리스트를 JSON 문자열로 직렬화하여 반환 return json.dumps(orders) # 사용자 민감 정보가 포함된 데이터의 경우 @mcp.resource 데코레이터를 사용하지 않습니다. def _get_customer_sensitive_info(customer_id: str) -> dict: """ 내부 데이터 소스에서 고객의 민감한 기본 정보를 조회합니다. 이 함수는 Tool 내부에서만 호출됩니다. """ print(f"[_Internal] 고객 민감 정보 조회 (ID: {customer_id})") return CUSTOMERS_SENSITIVE_DATA.get(customer_id, {})123456789101112131415161718 -
Tool은 이 Resource를 내부에서 호출하여 데이터를 가져옵니다. Tool은 데이터가 데이터베이스에서 오는지, API에서 오는지 전혀 알 필요가 없습니다.
Python▼# Tool은 비즈니스 로직에만 집중 @mcp.tool() def get_customer_full_summary(ctx: Context, customer_id: str) -> str: """ 고객 ID를 사용하여 전체 요약 정보(민감 정보 + 주문 내역)를 생성합니다. """ print(f"\n[Tool] get_customer_full_summary 실행 (ID: {customer_id})") # [패턴: 직접 함수 호출] # 안정적인 stdio 통신을 위해, Tool 내부에서 다른 리소스나 내부 함수를 직접 호출합니다. sensitive_info = _get_customer_sensitive_info(customer_id) if not sensitive_info: return f"Error: Customer with ID {customer_id} not found." # get_customer_orders 함수를 직접 호출하여 주문 정보를 문자열로 가져옵니다. orders_json_string = get_customer_orders(customer_id) # JSON 문자열을 다시 Python 리스트로 변환합니다. orders_list = json.loads(orders_json_string) # 조회된 데이터를 조합하여 최종 결과물을 생성합니다. name = sensitive_info.get("name") phone = sensitive_info.get("phone") order_summary_text = ", ".join(orders_list) if orders_list else "No orders" summary = ( f"--- Customer Full Summary ---\n" f" Name: {name}\n" f" Phone: {phone}\n" f" Orders: {order_summary_text}\n" f"---------------------------" ) print(f"[Tool] 작업 완료.") return summary1234567891011121314151617181920212223242526272829
-
-
이제 고객 주문 정보 조회가 외부 API로 변경되면, 개발자는 오직
get_customer_orderResource 함수 단 하나만 수정하면 됩니다.Python▼# Resource만 수정하면 모든 Tool에 자동 적용됨 @mcp.resource("ecom://customers/{customer_id}/orders") def get_customer_orders(customer_id: str) -> str: # 데이터 소스가 외부 API로 변경됨 return await httpx.get(f"https://api.customers.com/v2/{customer_id}")12345get_customer_full_summaryTool은 코드를 단 한 줄도 변경할 필요가 없습니다
그리고 Resources는 캐싱이 가능합니다.
4.2.2 주문 배송 상태 조회 사례
상황: 주문의 실시간 배송 상태를 조회하는 외부 API가 매우 느리고 호출 비용이 비싸다고 가정해 보겠습니다.
-
잘못된 설계 (모든 것을 Tool로 구현):
여러 Tool들이 각자 이 느린 외부 배송 API를 직접 호출합니다. 성능을 개선하기 위해 캐싱을 도입하려면, 이 API를 호출하는 모든 Tool을 일일이 찾아다니며 캐싱 로직을 추가해야 합니다. 이는 번거롭고 일관성을 유지하기 어렵습니다.
-
올바른 설계 (Resources와 Tools 분리):
-
Resources는 "어떻게 데이터를 가져올 것인가(How to get data)" 라는 관심사만 책임집니다.
-
Tools는 "그 데이터로 무엇을 할 것인가(What to do with data)" 라는 비즈니스 로직 관심사만 책임집니다.
-
느린 API를 호출하는 get_shipping_status Resource를 만들고, 이 Resource 함수에만 캐싱 데코레이터를 추가합니다
@cached(TTLCache(maxsize=1024, ttl=300)) # 5분 캐싱 @mcp.resource("ecom://shipping/{order_id}") async def get_shipping_status(order_id: int) -> dict: # 느리고 비용이 비싼 외부 API 호출 return await httpx.get(f"https://api.shipping.com/tracking/{order_id}")12345
이제 위 API를 ecom://shipping/{order_id} 리소스를 호출해서 캐싱할 수 있습니다. 서버의 응답 속도는 향상되고 불필요한 API 호출 비용은 절감됩니다. Resources를 활용해서 Tools을 구현할 시 코드 확장과 관리하기 용이해집니다.
5. 결론
MCP 서버 아키텍처를 도입하는 과정에서 다음과 같은 결론을 얻을 수 있었습니다.
MCP 서버를 활용했을 때 가장 큰 장점은 다양한 기능(Tools, Resources, Prompts)을 @mcp.tool, @mcp.resource, @mcp.prompt와 같은 일관된 인터페이스로 정의하고 호출할 수 있다는 점입니다. 이는 시스템 전체의 확장성과 일관성을 크게 향상시킵니다. 각 컴포넌트가 명확한 책임을 가지므로 새로운 기능을 추가하거나 기존 기능을 수정할 때 다른 부분에 미치는 영향을 최소화할 수 있으며, 이는 특히 여러 LLM 에이전트가 협업하거나 다양한 외부 도구와 연동해야 하는 멀티 에이전트 시스템으로의 확장에 매우 최적화된 구조라고 판단됩니다.
하지만 모든 상황에서 MCP 서버 도입이 최선은 아닐 수 있습니다. 예를 들어, 단순히 몇 개의 간단한 API를 호출하는 기능만을 LLM에 제공하고자 할 때 MCP 서버 전체를 구축하는 것은 초기 설정의 부담과 호출 과정에서의 오버헤드가 있을 수 있습니다. 이 경우, 더 가벼운 연동 방식이 효율적일 수 있습니다.
그럼에도 불구하고, 향후 AI 에이전트 간의 협업이 더욱 활발해지고, LLM이 활용해야 할 도구의 종류와 복잡성이 증가할수록 MCP와 같은 표준화된 프로토콜의 중요성은 더욱 커질 것입니다. MCP는 다양한 기능과 데이터를 일관된 방식으로 통합하고 관리할 수 있는 강력한 프레임워크를 제공하며, 이는 미래의 복잡한 AI 시스템에서 확장성과 상호운용성의 핵심적인 역할을 할 것으로 기대됩니다.
이번 MCP 연구를 통해 실제적인 효용성과 장단점을 경험할 수 있었으며, 향후 더 발전된 AI 에이전트 시스템 구축에 있어 MCP가 중요한 기반이 될 것이라는 확신을 얻었습니다. 감사합니다.
참고 논문
- A Survey of the Model Context Protocol(MCP): Standardizing Context toEnhance Large Language Models(LLMs) , Aditi Singh*,Abul Ehtesham*,Saket Kumar,Tala Talaei KhoeiPosted Date: 2 April 2025
- LiteCUA: Computer as MCP Server forComputer-Use Agent on AIOS, Kai Mei, Xi Zhu, Hang Gao, Shuhang Lin, Yongfeng Zhang, Rutgers University, AIOS Foundation
- A Survey on Model Context Protocol: Architecture, State-of-the-art,Challenges and Future Directions, Partha Pratim Ray,Senior Member, IEEE
- TAIJI: MCP-based Multi-Modal Data Analytics on Data LakesChao Zhang, Shaolei Zhang, Quehuan Liu, Sibei Chen, Tong Li, Ju Fan*Renmin University of China
- Model Context Protocol (MCP): Landscape, Security Threats,and Future Research Directions, XINYI HOU,,YANJIE ZHAO, SHENAO WANG, ChinaHAOYU WANG,Huazhong University of Science and Technology, China
- MCP Safety Audit: LLMs with the Model Context ProtocolAllow Major Security Exploits, Brandon Radosevich∗John T. Halloran∗Leidos
- Large Language Model Agent: A Survey onMethodology, Applications and Challenges, Junyu Luo, Weizhi Zhang, Ye Yuan, Yusheng Zhao, Junwei Yang, Yiyang Gu, Bohan Wu, Binqi Chen,Ziyue Qiao, Qingqing Long, Rongcheng Tu, Xiao Luo, Wei Ju, Zhiping Xiao, Yifan Wang, Meng Xiao,Chenwu Liu, Jingyang Yuan, Shichang Zhang, Yiqiao Jin, Fan Zhang, Xian Wu, Hanqing Zhao,Dacheng Tao,Fellow, IEEE, Philip S. Yu,Fellow, IEEEand Ming Zhang
- MCP Bridge: ALightweight,LLM-AgnosticRESTful Proxy for Model Context ProtocolServers, Arash Ahmadi, Sarah Sharif, Yaser M. Banad, School of Electrical, and Computer Engineering, University ofOklahoma, Norman, Oklahoma, United States