
들어가는글
안녕하세요. KT에서 Data Engineer로 근무하고 있는 김기영 입니다.
자고 일어나면 새로운 AI 모델과 기술이 발표되고, 전세계적으로 AI를 활용한 서비스 개발에 기업의 모든 역량을 집중하고 있고 있습니다. KT도 MS와의 전략적 파트너십과 더불어 한국형 AI 개발에 박차를 가하여 전사의 모든 역량을 투입하고 있으며, AI 성능의 중요한 역할을 하는 Data 에 대해서도 그 어느때 보다 중요성이 대두되고 있습니다.
KT 내에서도 Azure Cloud를 활용한 서비스/플랫폼의 Migration이 한창인 가운데, 국내를 포함한 전세계적으로 Data Platform의 On-premise 에서 Cloud로의 전환이 가속화 되고 있으며, KT에서는 기존 On-premise에 구축된 Data Platform을 Public Cloud로 전환하는 작업을 신속하게 진행하고 있습니다.
물론 국내 스타트업을 포함한 많은 기업들이 서비스를 Public Cloud를 통해 구축하기도 하지만 전통적으로 규제산업(금융, 통신 등) 내 기업의 경우 On-premise 에 시스템을 구축하여 서비스를 하고 있기 때문에, 규제산업에서의 Public Cloud로의 전환하는 것에는 아래의 같은 의미가 있습니다.
-
기존 서버 구매 → 딜리버리 → 시스템 설치 → 서비스 구축과 같은 단계에 비해 신속하게 Infrastructure Provisioning 하여 lead-time 을 단축하고, 고객 Leeds에 맞는 서비스를 빠르게 개발하여 제공하겠다는 의지
-
기존의 의사결정 데이터 생성, 리포트 개발, 모델 개발 등과 같은 내부 분석 업무의 활용에서 벗어난 B2B, B2C의 고객 서비스 접점에서 활용하기 위한 플랫폼 구축으로의 포지셔닝
KT에서는 Databricks, Snowflake, Fabric, Palantir 등의 Cloud Platform 시장을 Lead하고 있는 Platform을 활용하여 내외부의 문제를 해결하기 위해 플랫폼을 설계하고 있으며, 통합 Data Lakehouse 구축 영역은 데이터 수집부터 관리 까지의 강점을 가지고 있는 Azure Databricks를 선정하게 되었으며, 이를 기반으로 Data Lakehouse를 구축하고 있습니다. (물론 기업 내의 다양한 문제를 해결하기 위한 다양하고, 최신의 Cloud 솔루션들을 같이 사용하고 있습니다.)
Data Platform 구성 요소
KT에서 Azure Cloud의 최신 기술과 서비스들을 활용하여 Data Platform 을 어떻게 설계하였는지 알아 보기 전에 Data Lakehouse에 대해서 간단히 알아 보겠습니다.
Data Lakehouse
빅데이터 분석을 위한 다양한 원천 데이터의 중앙 저장소로서, Data Warehouse -> DataLake → Data Lakehouse 로 확장된 개념입니다.
데이터 저장 및 관리 영역에 따른 장단점은 아래와 같으며, Data Warehouse와 DataLake의 장점을 결합하여 정형/비정 데이터 분석 부터 ML모델 개발 및 AI 서비스를 위한 유연한 아키텍처를 제공합니다.
|
|
Data Warehouse |
Data Lake |
Data Lakehouse |
|---|---|---|---|
|
장점 |
|
|
|
|
한계 |
정형 데이터만의 처리에 한계가 있으며, 유연한 데이터 구조 변경 어려움 |
원시 형태로 저장하여 데이터 품질 관리가 어려우며, 데이터 탐색에 어려움 |
높은 비용과 관리 역량 필요 |
Public Cloud 기반이든 On-premise 든 Data Platform에서 기본적으로 제공해야 하는 기능은 동일하지만, 최근 Public Cloud의 SaaS 서비스들은 최신 기술에 대해서 신규 개발이나 구축이 아닌 기능 업데이트로 빠르게 사용자에게 기능을 제공합니다. 예를 들면, 테슬라 전기차의 소프트웨어가 최신 버전으로 업데이트 되면, 완전히 새로운 차가 되는 것 처럼 말입니다. 이렇듯 Data Platform은 어느 한 시스템을 기반으로 구축하기 보다는 현재의 문제점을 해결하기 위한 최선의 기술들을 조합하여 문제 해결을 최우선적으로 고려하여 설계/구축 하고 있습니다. 아래는 각 항목별로 구축시 사용한 기술들을 나열해 두었습니다.
|
기능 |
요구사항 |
Azure Cloud + 2nd/3rd Party SaaS |
|---|---|---|
|
수집 (ingestion) |
소스 시스템(정형, 비정형, 반정형)에 구애받지 않는 형태의 다양한 데이터 수집 기능 제공 (원천 시스템, 데이터의 형태, 입수 주기 등) |
Azure Data Factory Azure Eventhub Azure Power Platform, Databricks Live Table |
|
처리 (transformation) |
기존 query 기반의 데이터 처리 형태를 유지하면서, 더 높은 성능과 새로운 기능 제공 |
Spark (Databricks Spark SQL, PySpark) |
|
적재 (Load) |
기존 정형 데이터 뿐만 아니라 AI 학습, RAG 등에 필요한 이미지, 영상, 음성 등의 다양한 형태의 데이터 적재가 가능한 스토리지 제공 |
ADLS Gen2 Deltalake (포맷: parquet/압축: zstd) |
|
데이터 탐색 (Search) |
데이터의 형태와 목적에 상관없는 통합된 catalog 와 lineage 기능을 자동화하여 입력 가능하는 기능을 제공 |
Databricks Unity Catalog Azure Purview |
|
분석 환경 (Environment) |
사용자의 SQL, Python, R, Java 등을 활용한 다양한 분석 도구를 제공하며, CI/CD 및 타 시스템과의 연동 기능을 포함 |
Databricks Notebook VSCode |
|
서비스 (Serve) |
데이터를 서비스하기 위한 기능으로 분산된 환경이 아닌 하나의 통합된 UI에서 연결성 있는 프로세스를 제공 |
Databricks Unity Catalog Databricks Mosaic AI Azure ML Azure Foundry MS Fabric Azure AI Search Snowflake |
Reference Architecture
- Lakehouse 구축을 위한 기본적인 아키텍처 구성에 대해서 확인할 수 있습니다.
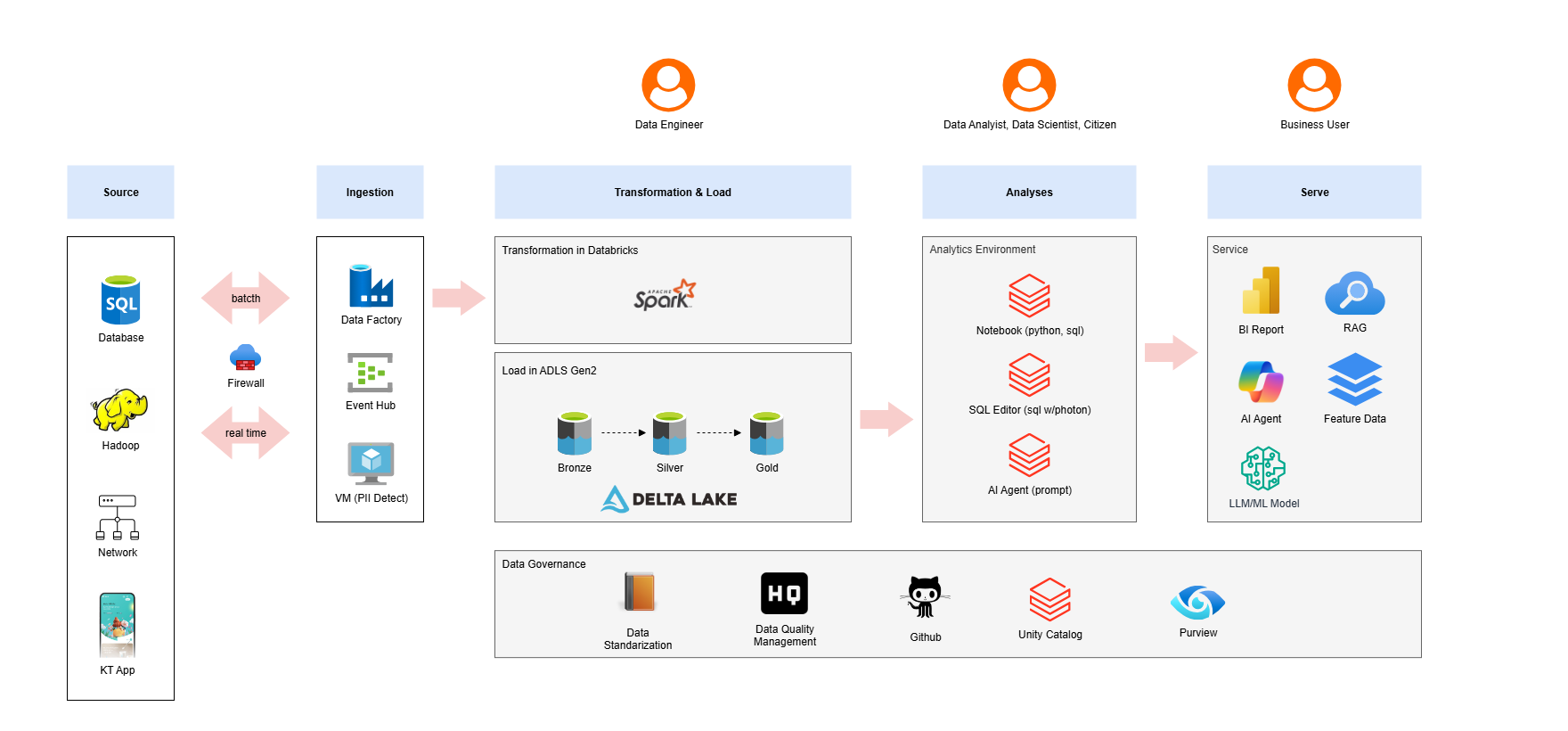
1) 수집 (ingestion)
- azure data factory는 현재 KT에서 운영중인 모든 시스템과의 호환성을 유지하고, Azure 내의 시스템과도 연동 호환성을 거의 완벽하게 제공합니다.
- azure eventhub는 kafka기반의 실시간 메시지 브로커의 역할을 수행하며, DLT (Databricks Live Table)과 연동을 포함하여 Azure 내의 타 서비스로의 데이터 중계 역할을 제공합니다.
2) 처리 (transformation)
- ingestion 영역을 통해 수집된 데이터들은 잠시 임시 스토리지로 저장되고, Databricks Spark작업을 통해서 Bronze → Silver → Gold 영역으로 필요한 형태로 처리를 수행합니다.
- Bronze: 원천 시스템 데이터의 형태와 동일하며, 기본 컴플라이언스 정책이 적용한 데이터로 짧은 기간의 보관 기간을 가집니다.
- Silver: Bronze 영역의 데이터를 표준화, 클렌징, 비즈니스 모델링 적용 등을 반영하여 사용자들에게 직관적인 데이터의 형태로 제공합니다.
- Gold: BI 및 서비스에 바로 활용이 가능한 형태로 transformation, aggregation, summarize 된 데이터의 형태로 각 플랫폼 및 사용자에게 제공됩니다.
- 데이터 처리과정에서 Databricks Workflow 을 통해서 모든 데이터는 스케줄링 되며, 품질, 모니터링 되어 관리됩니다.
3) 적재 (Load)
- 각 영역(Bronze, Silver, Gold) 에 적합한 형태로 처리된 데이터는 ADLS(Azure Data Lake Storage) Gen2 스토리지에 Parquet/zstd 형식으로 저장관리 됩니다.
- 데이터의 형태에 따른 ADLS Gen2 스토리지 형식을 분리하여 저장하고, 서비스/활용하는 영역에 제공합니다.
4) 거버넌스 & 데이터 탐색 (Governance & Search)
- Lakehouse 의 모든 데이터는 Unity Catalog의 표준화된 형식에 따라 관리되며, 사용자는 통합 검색을 통해서 다양한 데이터(정형, 비정형, 모델 등)를 검색할 수 있도록 기능을 제공합니다.
- 처리된 데이터는 Data Lineage 를 자동으로 입력받아, 데이터의 흐름을 추적하여 데이터의 출처와 변화 과정, 최종 목적지를 명확하게 파악할 수 있는 정보들을 Catalog에서 제공합니다.
- Unity Catalog는 delta, iceberg를 포함하여 다양항 데이터 레이어 기술들을 연동하고, 빠르게 새로운 기능들이 업데이트를 제공합니다.
5) 분석 환경 (Environment & Analyses)
- Databricks Notebook, VSCode에서 ANSI SQL, Python 같은 도구로 데이터를 자유롭게 분석할 수 있으며, 다양한 도구들을 통해서 자유롭게 자동화 할 수 있는 분석 환경을 제공합니다.
- 분석 환경에 필요한 라이브러리들은 보안에서 안전할 수 있도록 Nexus를 통해서 내부에서 관리하여 통제되고 있습니다.
6) 서비스 (Serve)
- 도서관과 같이 잘 정리된 데이터와 연동 인터페이스를 통해서 기능들이 구성이 되어 있기 때문에, 이를 활용하기 위한 다양한 플랫폼(기술 스택)을 활용하여 문제를 해결 할 수 있습니다.
- BI OLAP -> AI Agent까지 활용이 필요한 서비스 연계를 통해서 기업내의 의사결정에서 부터 대고객 서비스까지의 활용을 위한 인터페이스를 제공합니다.
향후 주제
최신 Cloud 기술을 활용하여 많은 부분이 자동화 됨에도 불구하고, 물론 여러 제약 조건과 한계 기능들이 존재하며, 자동화가 어려운 부분들은 직접 설계하고 개발해야 하는 부분들도 많습니다. 아래에 구축시 추가적으로 고려해야 할 점에 대해서 간단히 이야기하고, 이슈 해결을 위한 고민했던 경험들과 개선된 내용들에 대해서는 연재물로 작성해 보도록 하겠습니다.
-
Network 데이터 실시간 수집 파이프라인 구축 - Azure 환경에서 안정적으로 실시간 데이터를 분석 및 서비스에 직접적으로 활용하기 위한 아키텍처 구성과 최적화 방안들에 대해서 구축 과정
-
데이터 입수 모니터링 대시보드 구현 - 데이터의 수집/적재에 대한 운영 효율화를 위한 모니터링 체계 및 대시보드 개발 과정
-
안정적인 Workspace Backup 및 Migration 범위 및 기능 확인 - Databricks Workspace를 안정적으로 운영하기 위한 Backup 관리 정책과 Migration 수행 과정
-
통합 메타 관리 - 전사 데이터 거버넌스 관리를 위한 데이터 메타를 통합하고 관리할 수 있는 전문 솔루션을 제공하고 있지 않기 때문에, 이를 위한 별도의 통합 메타 시스템 구축 방안
-
Cloud 비용 효율화 (Storage Tiering) - ADLS Gen2 는 현재 자동으로 Data 분류에 따른 Tiering이 되지 않으며, 각 Storage를 목적에 맞게 분리하고, 해당 Storage별로 Hot, Cool, Cold, Archive 설정하여 데이터를 분리 적재 보관을 위한 효율화 방안
-
CI/CD Pipeline 설계 및 구축 - ETL 작업에 필요한 소스들은 Github 를 통해서 관리하고, Github Action등을 활용해서 배포 관리를 하고 있지만, 많은 시스템/플랫폼을 활용하여 구축하기 따라서 전체 자동화를 위해서 관리 자동화 방안
-
Spark Job 최적화 - Spark Job을 최적화 하기 위해서 데이터 정렬 및 분산, Spark Configuration, Instance (Executor) Spec 등을 적절히 설정해서 관리 방안