
AI Model Engineering팀은 Azure상에 KT자체 개발 모델, 각종 파운데이션 모델을 실제 application에서 사용할수 있도록 제공하는 과정인 모델 서빙 작업을 수행하고 있습니다.
모델을 서빙할 수 있는 다양한 환경들 중 저희는 Azure Machine Learning을 통해 학습된 모델을 안정적으로 사용할 수 있도록 서빙 환경을 구축하였으며 지금까지 약 50종 이상의 다양한 모델을 기반으로 114개 이상의 서빙 작업을 수행하였습니다.
이렇게 다양한 종류의 모델들을 어떻게 안정적으로 서빙할 수 있는 환경을 구축했을까요? 지금부터 그 환경을 구축한 경험을 소개해드리겠습니다.
Azure Machine Learning

Azure machine learning은 Azure에서 제공하는 클라우드 기반의 머신러닝 플랫폼입니다.
데이터 과학자, 개발자, 엔지니어는 Azure Machine Learning을 통해 모델에 대한 학습, 개발, 운영, 배포까지 한 서비스를 통해 수행함으로써 머신러닝 프로젝트 라이프 사이클을 간편하게 구성하고, 모델 개발을 가속화 할 수 있습니다.
Azure ML을 통해 모델을 서빙하게되면 다음과 같은 이점을 얻을 수 있습니다.
-
모델 서빙에 필요한 모든 자원을 한 곳에서 관리가 가능합니다. 곧이어 설명 드릴 모델 서빙에 필요한 다양한 요소들을 하나의 플랫폼에서 관리가 가능합니다.
-
트래픽, 하드웨어 사용량을 기반으로 유연하고 자동화된 auto-scaling을 구현 가능합니다.
-
Azure Monitor, Log Analytics와 통합하여 모델에 대한 가용성, 성능을 모니터링 가능하고 배포 과정을 디버깅 할 수 있습니다.
-
실시간 온라인 엔드포인트, serverless 배포, 배치 배포 등 다양한 배포 방식을 지원하여 다양한 서비스에 적절한 배포 방식을 선택 가능합니다.
이러한 특장점을 통해 고도화된 서빙 플랫폼을 구축하기 위해 저희 팀은 서빙 플랫폼으로 Azure machine learning을 선택하게 되었습니다.
모델 서빙에 필요한 요소
우선 모델을 서빙 하는 데에 필요한 요소들은 다음과 같습니다.
|
요소 |
설명 |
|---|---|
|
모델 아티팩트 |
학습된 모델의 정보가 담긴 파일 |
|
컴퓨팅 자원 |
모델의 추론이 수행될 컴퓨팅 자원 |
|
환경 |
컴퓨팅 자원에 설치될 각종 패키지, OS |
아티팩트
첫 번째로 모델 아티팩트 입니다. 모델을 서빙 하기 위해서 해당 모델의 정보가 담긴 파일이 필요합니다.
KT 자체 개발 모델과 huggingface에 등록된 외부 모델까지 아티팩트를 저장하고 버전 별로 관리가 가능한 모델 카탈로그가 필요했습니다.
Azure ML은 Azure에서 자체적으로 제공하는 Model Catalog와 학습된 외부 모델, 자체 개발 모델에 대한 관리가 가능한 Model Asset을 등록 가능한 카탈로그를 제공합니다.
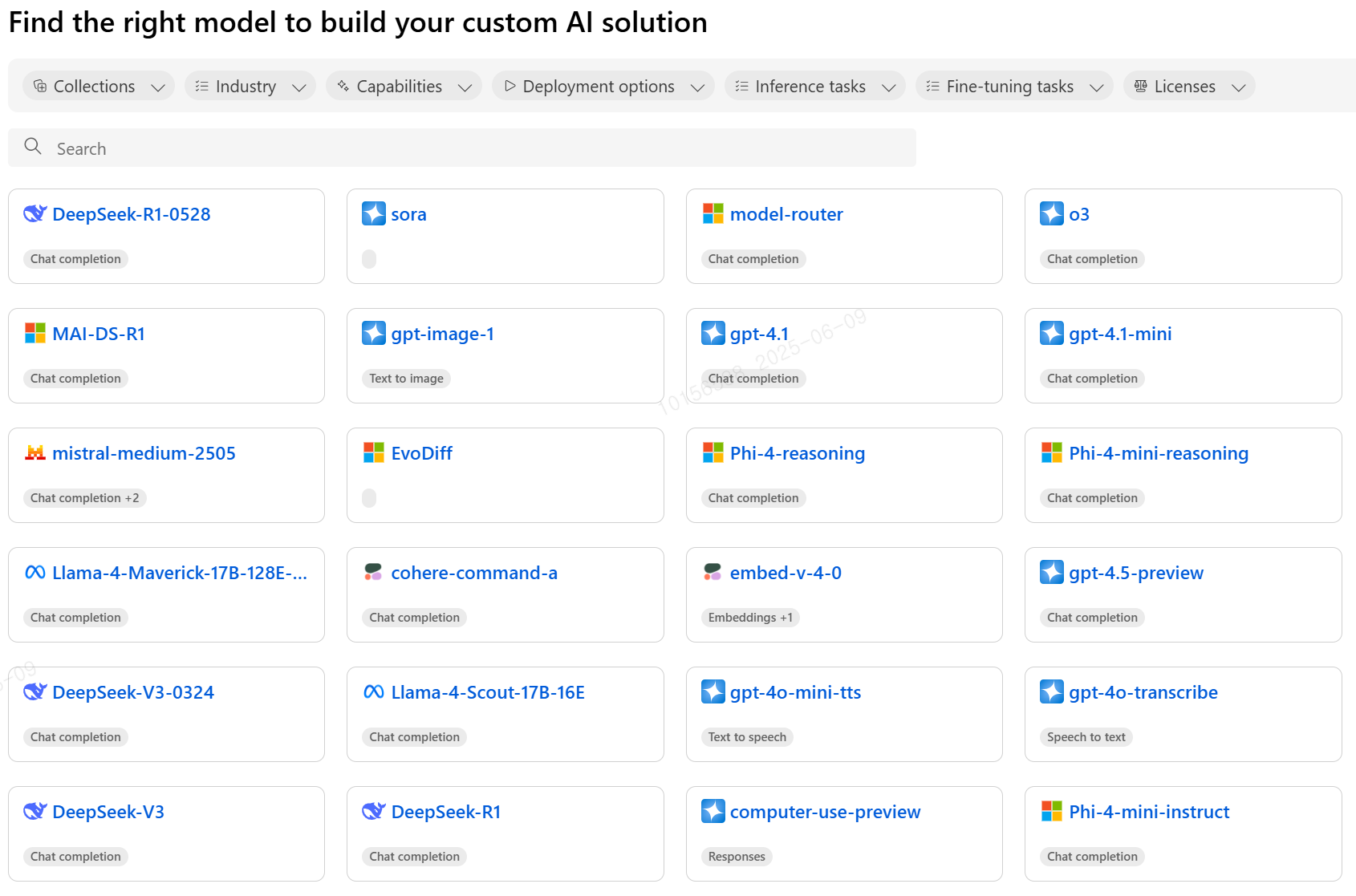
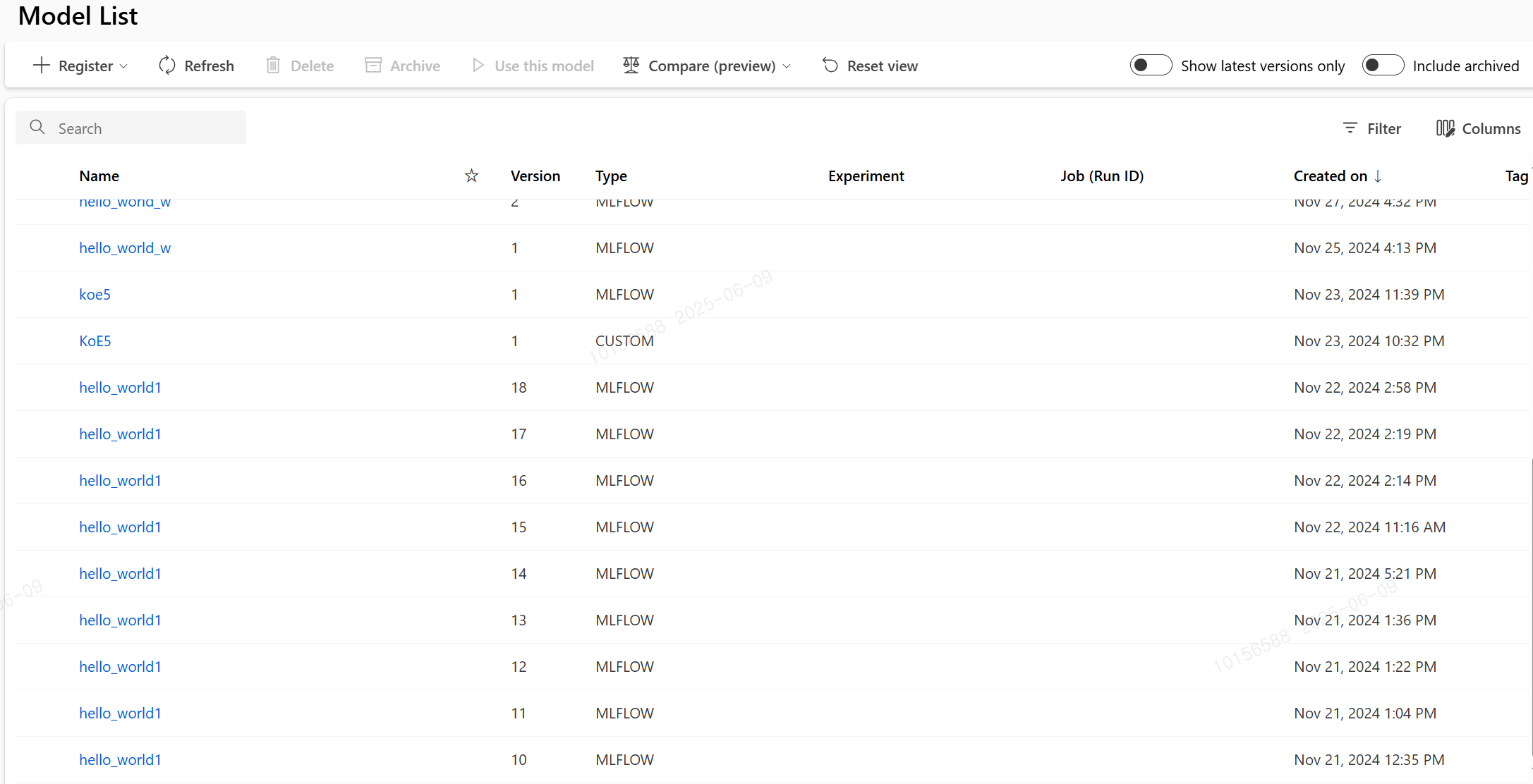
저희는 이 두 저장소 전부를 사용하여 사용할 모델에 대한 아티팩트를 가져와 서빙을 진행하려고 했으나… Azure Model catalog의 모델을 배포할 때는 특정한 컴퓨팅 자원(SKU)을 지정 할 수 없고, 모델 마다 정해진 종류의 SKU만 사용이 가능합니다. (SKU와 관련된 상세한 내용은 바로 앞에서 다시 설명 드리겠습니다.)
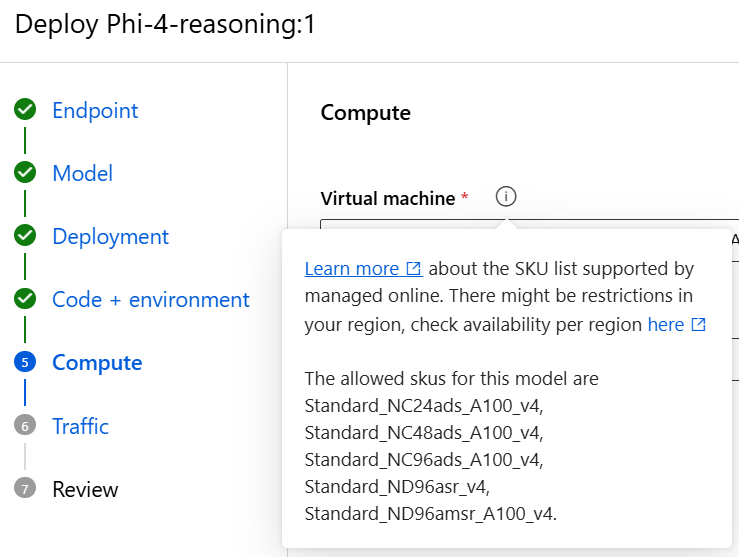
이러한 이유로, Azure Model catalog의 모델들은 저희가 모델 서빙 시 사용하는 nvidia H100 GPU가 포함된 SKU인 STANDARD_NC40ADS_H100_V5, STANDARD_NC80ADS_H100_V5 시리즈를 사용할 수 없어 결국 Model Asset에서 자체 개발 모델, 외부 모델을 전부 관리하도록 하였습니다.
컴퓨팅 자원 - SKU(Stock Keeping Unit)
현재 나와있는 대부분의 LLM은 대규모 언어 모델이라는 이름에 걸맞게 엄청난 수의 Parameter가 존재하고 그에 따라 수십억 개의 parameter를 기반으로 행렬 곱셈 연산을 수행하기 위해 엄청난 컴퓨팅 자원이 소모됩니다.
Azure ML은 배포된 모델의 온라인 엔드포인트에 사용될 컴퓨팅 자원인 SKU(Stock Keeping Unit)를 통해 추론 서비스를 제공합니다.
미리 정해진 CPU, GPU, Memory조합에 따라 다양하게 선택 가능한 SKU를 통해 대규모 추론에 최적화된 GPU 기반 SKU로 서빙을 진행할 수 있고, Memory 사용량, latency와 같은 메트릭 모니터링을 통해 유연하고 자동화된 오토 스케일링을 구현할 수 있습니다.
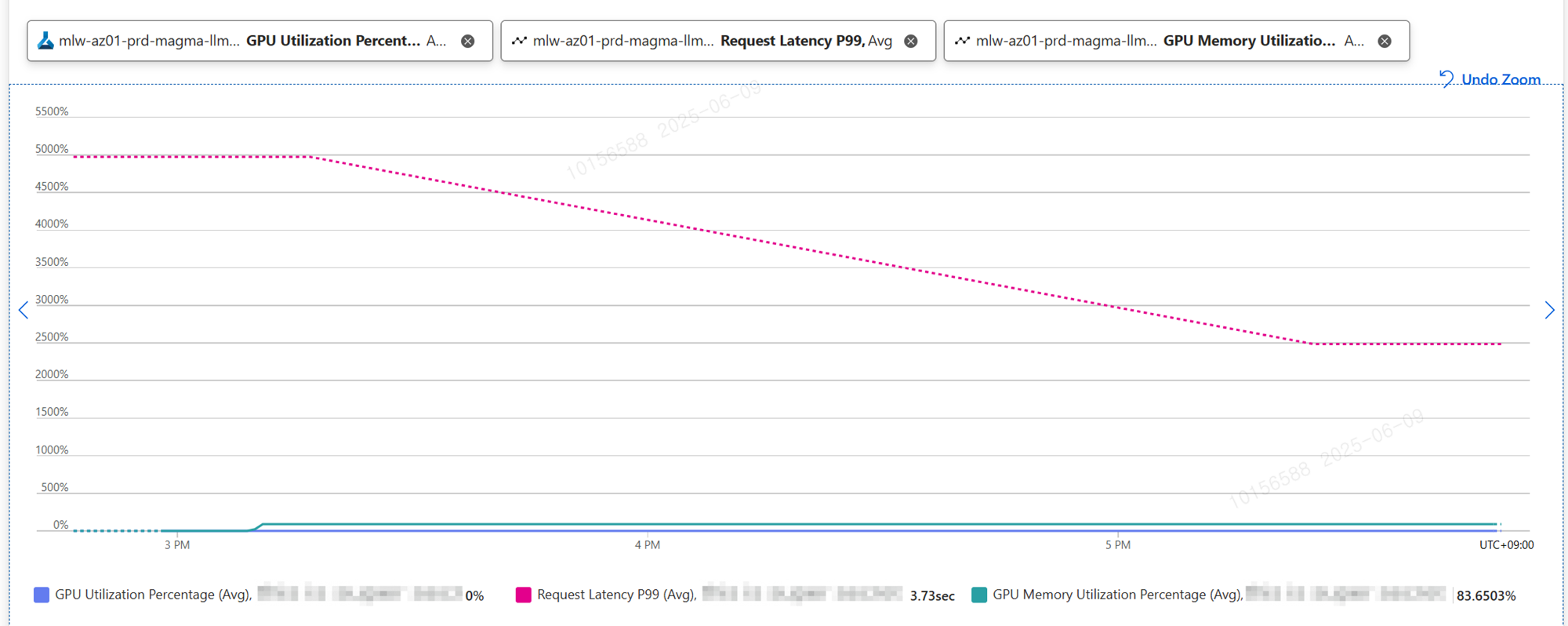
현재 Azure 환경에서 서빙 되고 있는 대부분의 LLM은 1~2장의 H100으로 구성된 Standard_NC40ads_H100_5 Standard_NC80adis_H100_v5 SKU를 통해 서빙 되고 있습니다.
환경
각 모델 별로 추론을 수행 할 때 설치될 python 버전과 패키지, OS, 설정 등이 구성된 다양한 환경이 필요합니다.
Azure ml의 Enviorment는 Conda에 종속성이 있는 Docker image나 Docker 파일을 통해 필요한 환경을 빌드하여 다양한 배포 작업에 대해 공통된 환경을 제공할 수 있습니다.
과정
Azure ML에서 모델을 서빙 하는데 필요한 요소들을 살펴보았으니 다음으로 Azure ML에서 어떤 과정을 통해 서빙을 진행했는지 설명 드리겠습니다.
첫 번째로, Azure ML 서비스를 사용하여 서빙 작업을 수행하는 방법은 여러가지가 있습니다.
-
Azure cli
-
python sdk
-
Azure ml studio(UI)
-
ARM template
모델 등록부터, 환경 구성, 엔드포인트 배포까지 전 과정을 위 4가지 방법을 통해 수행할 수 있지만, 저희는 Databricks notebook을 통해 Python sdk를 사용하는 방식으로 서빙 프로세스를 결정하였고 그 이유는 다음과 같습니다.
-
Databricks catalog에 적재된 모델 아티팩트를 쉽게 사용
현재 KT에서는 모델들에 대한 관리를 Databricks Unity Catalog를 통해 수행하고 있습니다. 해당 카탈로그에 접근 가능한 databricks notebook에서 python sdk를 통해 카탈로그에 적재된 크기가 매우 큰 모델 아티팩트를 Azure ml의 model로 쉽게 등록 할 수 있습니다.
-
코드 템플릿화
다양한 종류의 모델을 서빙 함에 따라 모델을 구동할 환경, 컴퓨팅 사양, 서빙 옵션 등이 매우 다양하기 때문에 서빙용 코드를 템플릿화 시키고, 모델마다 다른 옵션들을 변수로 지정하여 다양한 모델을 유연하게 서빙 가능하도록 하고, 서빙 완료된 모델을 Azure API Management로 wrapping시키는 과정까지 단일 환경에서 진행 가능하도록 프로세스를 설계했습니다.
Azure API Managemnet의 경우 Outbound에서 streaming 응답이 blocking 되어 실제 stream 응답처럼 나오지 않는 현상이 발생해 사용이 어려웠지만
KT의 전략적 파트너인 Microsoft의 PG(Product Group)팀으로 해당 기능 개발을 요청하여 Outbound에 대한 streaming 기능이 사용 가능하도록 배포 되었습니다.
자, 그럼 이제 간단하게 Databricks catalog와 연동된 ADLS gen2에 적재된 모델을 기준으로 Databricks notebook에서 python sdk를 통해 모델을 서빙 하는 과정을 살펴보겠습니다.
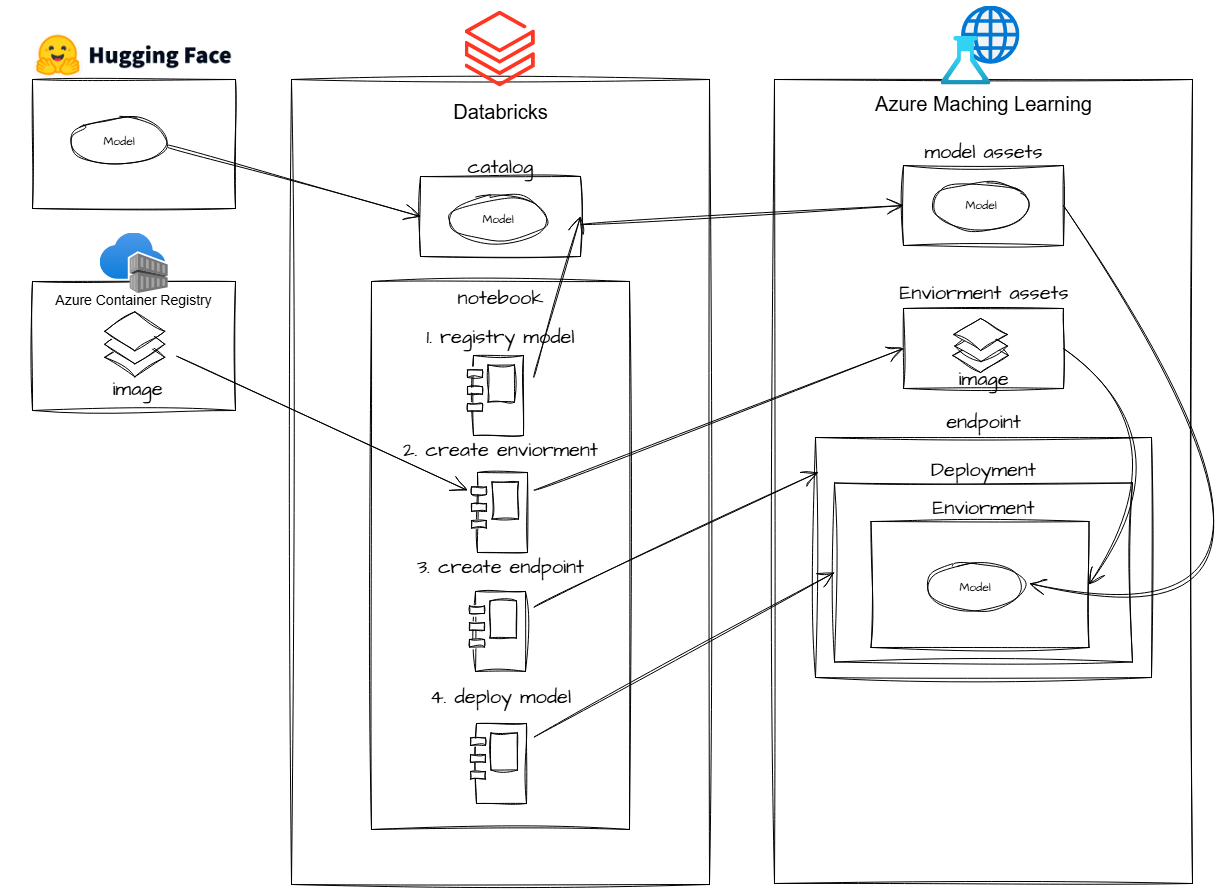
[서빙 프로세스 구조]
[로고 출처] :
https://www.databricks.com/solutions/industries/education
https://learn.microsoft.com/en-us/azure/architecture/icons/
기본 정보 입력
모델을 등록하기 전에, 모델과 구독, Azure ML 워크스페이스에 대한 기본 정보를 Databricks notebook의 widget에 입력합니다.
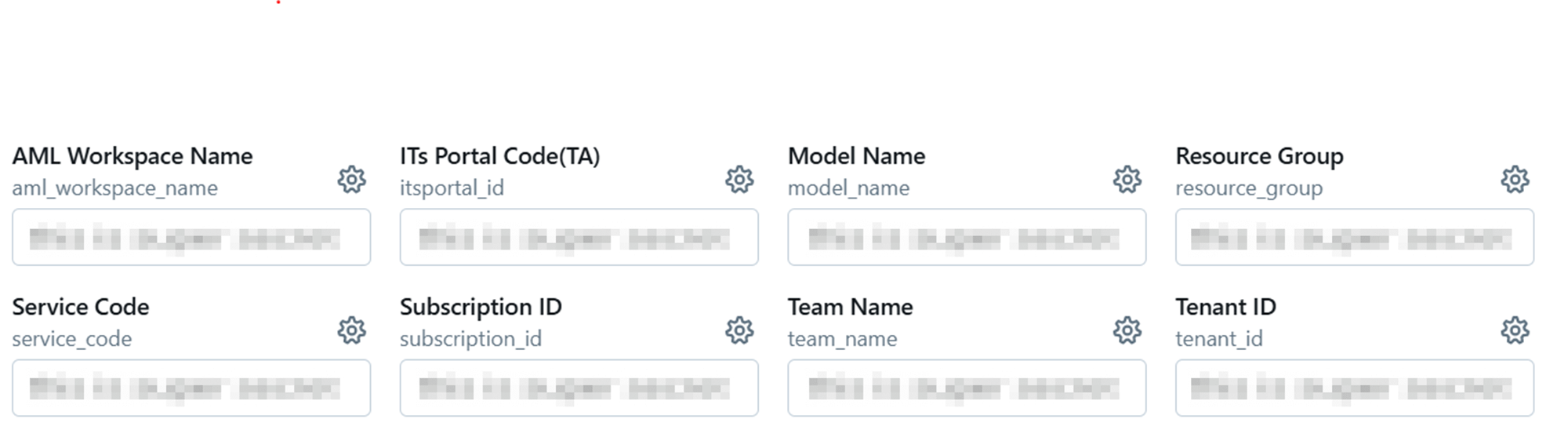
Azure ML의 워크스페이스, 모델 이름 등 태깅에 필요한 정보와 모델 배포에 대한 다양한 정보를 widget에 미리 등록하여 배포 과정에 사용하도록 하였습니다.
Azure ML 클라이언트 등록
azureml_client = MLClient(DefaultAzureCredential(), subscription_id, resource_group, workspace_name)1
Azure ML의 클라이언트를 등록하기 위해 widget에 등록된 정보들을 활용한 모습을 볼 수 있습니다.
이렇게 Azure ML의 workspace와 연결을 완료하면 해당 workspace의 모든 아티팩트에 대한 접근과 사용이 가능해지게 됩니다.
모델 등록
if register_aml_model: from azure.ai.ml.constants import AssetTypes file_model = Model( path=f"/Volumes/<MODEL_CATALOG_PATH>/", type=AssetTypes.CUSTOM_MODEL, name=aml_model_name, description="description", ) model_reg_result = azureml_client.models.create_or_update(file_model) model = f"azureml:{model_reg_result.name}:{model_reg_result.version}" else: model_list = azureml_client.models.list(aml_model_name) model_reg_result = model_list.next()12345678910111213
catalog에 저장된 모델 아티팩트를 기반으로 Azure ml에 모델 업로드 작업을 수행합니다,
/Volumes/<MODEL_CATALOG_PATH>/는 notebook에서 catalog에 접근 가능한 경로이며 해당 경로에 담긴 파일로 Model class를 생성한 뒤
그 객체를 azureml_client.models.create_or_update(file_model)를 통해 Azure ml의 Model로 등록하는 작업입니다. 위 작업을 수행하고 나면 아래처럼 databricks catalog의 모델 아티팩트가 Azure ML에서 학습, 배포 가능한 상태로 등록됩니다.
| Databricks catalog | Azure Machine Learning Model |
|---|---|
|
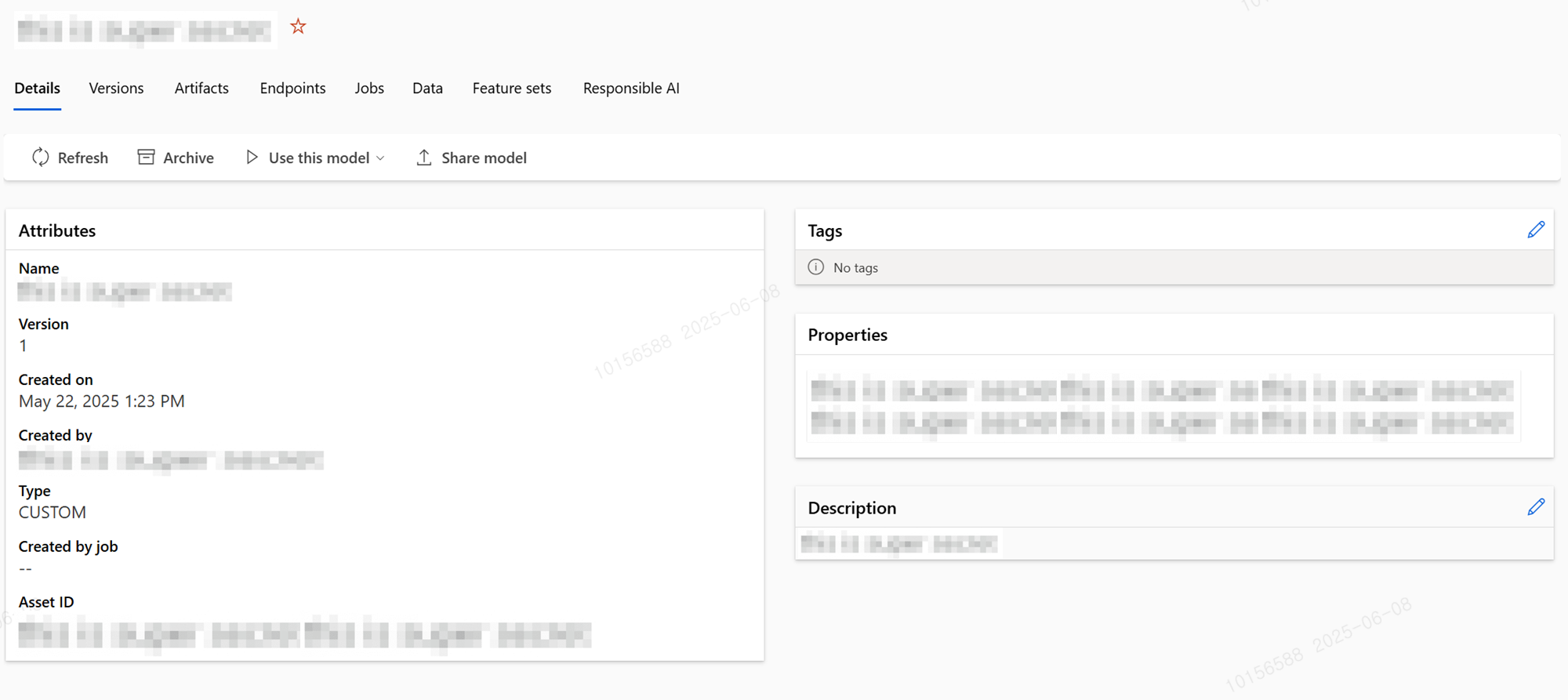
|
Environment 구성
모델이 등록되었다면, 이제 등록된 모델을 구동할 환경을 만들 차례입니다.
다양한 모델을 서빙 하기 위해서는 다양한 환경이 필요한데, OS / python version / package(vllm..)에 따라 각 배포마다 yaml파일을 작성하여 환경을 만들 수 있지만, 저희는 크게 VLLM의 버전 별로 Docker Image를 생성해 Azure Container Registy에 미리 등록 해놓고, 해당 공통 이미지를 기반으로 각 서빙마다 분리된 Environment를 생성 할 수 있도록 하였습니다.
env = Environment( image="acr01.azurecr.io/azureml/<IMAGE_URL> )123
엔드포인트 생성
다음으로는 모델을 요청, 호출 가능한 온라인 엔드포인트를 생성합니다. 엔드포인트에는 Serviece code, 요청 팀, ist portal id등의 다양한 태그를 추가하여, 비용 / 할당량에 관련된 모니터링을 수행 가능하도록 구성합니다.
endpoint = ManagedOnlineEndpoint( name = endpoint_name, description=f"{aml_model_name} for {team_name}", public_network_access="disabled", auth_mode="key", tags={ "Name" : workspace_name, "Service" : service_code, "Environment" : "prd", "ServiceGrade" : "C", "ProvisionedBy" : "NotTerraform", "CreatedBy" : user_email, "CreatedAt" : today, "TeamName": team_name, "TAID" : itsportal_id } )1234567891011121314151617
모델 배포
모델 아티팩트, 환경, 엔드포인트까지 전부 구성이 완료되었다면 이제 이를 기반으로 모델 배포를 수행합니다.
deployment = ManagedOnlineDeployment( name=deployment_name.replace('_', '-'), endpoint_name=endpoint_name, model=model_reg_result, environment=env, environment_variables={ "MODEL_NAME": aml_model_name, "MODEL_PATH": f"/var/azureml-app/azureml-models/{aml_model_name}/{model_reg_result.version}/{aml_model_name}", "TOKENIZER_PATH": f"/var/azureml-app/azureml-models/{aml_model_name}/{model_reg_result.version}/{aml_model_name}", "VLLM_ARGS": f"--served-model-name {aml_model_name} --tensor-parallel-size 1" }, instance_type=instance_type, scale_settings=DefaultScaleSettings(), liveness_probe=ProbeSettings(), instance_count=1, request_settings = OnlineRequestSettings(max_concurrent_requests_per_instance=20, request_timeout_ms=30000), tags={ "Name" : workspace_name, "Service" : service_code, "Environment" : "prd", "ServiceGrade" : "C", "ProvisionedBy" : "NotTerraform", "CreatedBy" : user_email, "CreatedAt" : today, "TeamName": team_name, "TAID" : itsportal_id } )12345678910111213141516171819202122232425262728
앞의 과정에서 생성한 Model, Enviorment Assets, endpoint와 vllm에 입력할 인자, 컴퓨팅 자원에 해당하는 SKU와 그 인스턴스 개수까지 입력하여 Deployment 객체를 생성하면 모든 서빙 준비가 완료됩니다. 이제 마지막으로 처음에 연결한 Azure ML의 클라이언트에 배포 명령을 수행하면 서빙 과정이 끝나게 됩니다.
azureml_client.online_deployments.begin_create_or_update(deployment).wait()
배포 과정은 평균적으로 15~20분 가량 소요되며, 모델 아티팩트의 크기와 Enviorment 빌드 시간에 따라 약간의 차이가 존재합니다. 성공적으로 배포까지 수행이 완료되었다면 해당 엔드포인트에 각 배포 별로 트래픽을 조정하여 실제로 모델을 추론할 준비를 완료합니다.
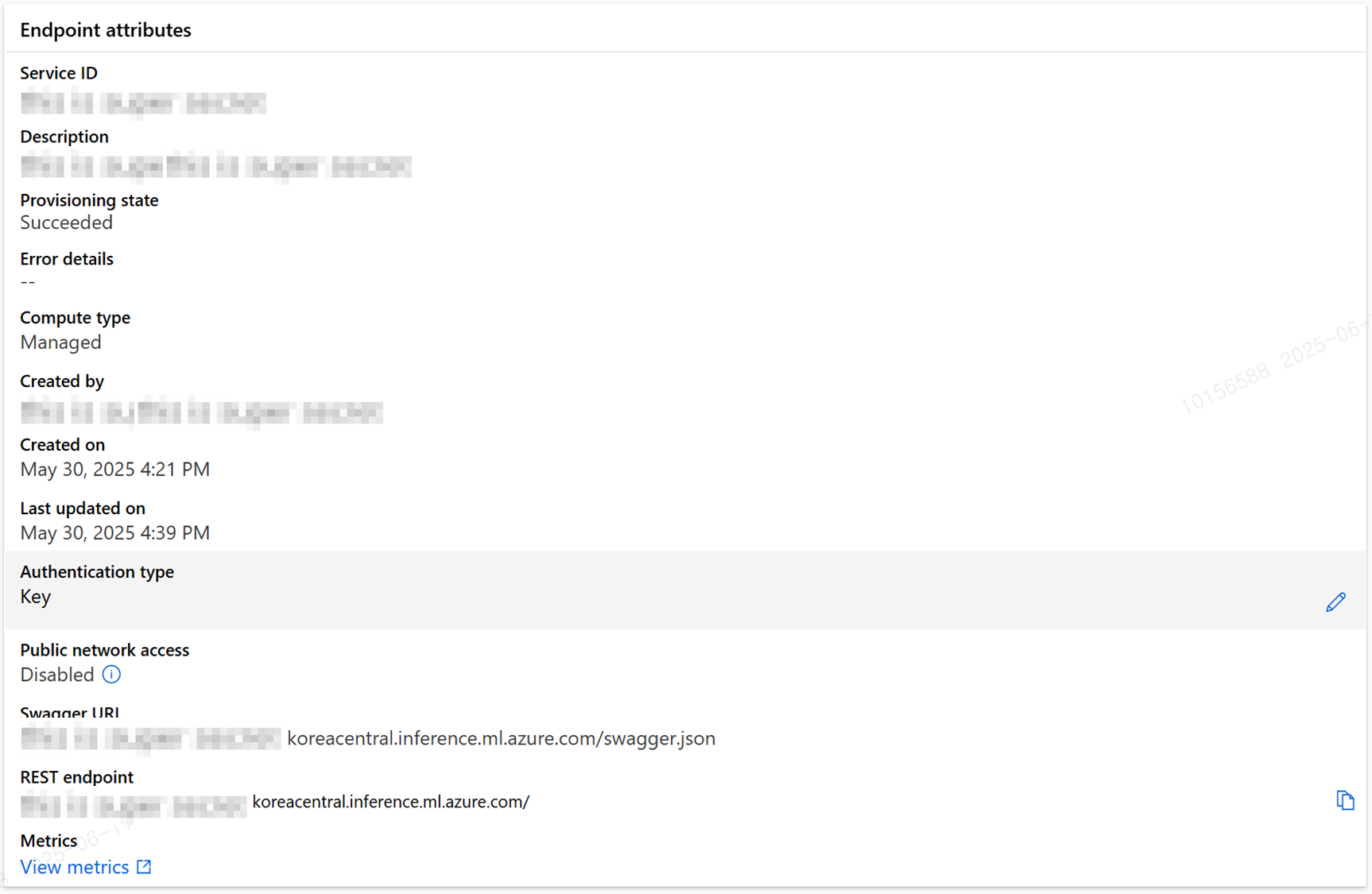
Azure ML - endpoint
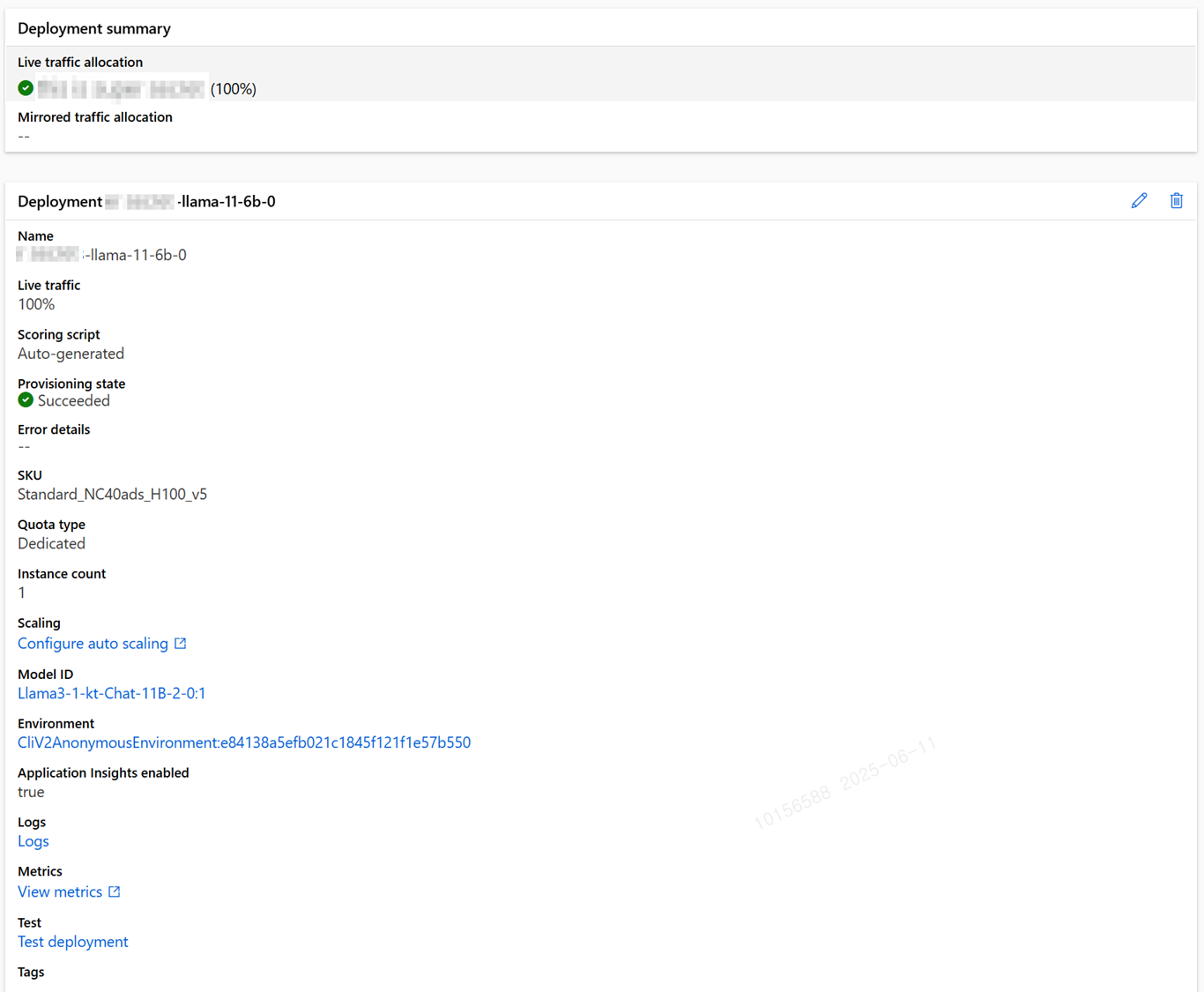
오토스케일 설정
배포가 완료된 모델은 배포시 설정한 인스턴스 개수만큼 SKU를 할당받아 추론을 수행합니다.
하지만 실제 서비스에서 해당 인스턴스로 처리 불가능할 만큼 많은 양의 요청이 오게 된다면 이를 대비하여 인스턴스 개수를 증가시키고(Scale-up) 요청이 다시 적어지면 인스턴스 개수를 감소시키는(Scale-out) 오토 스케일 기능이 필요합니다.
AML은 배포된 모델의 다양한 메트릭을 사용하여 조건을 만들고 그 조건에 따라 자동으로 동작하는 오토스케일을 구현 할 수 있습니다.
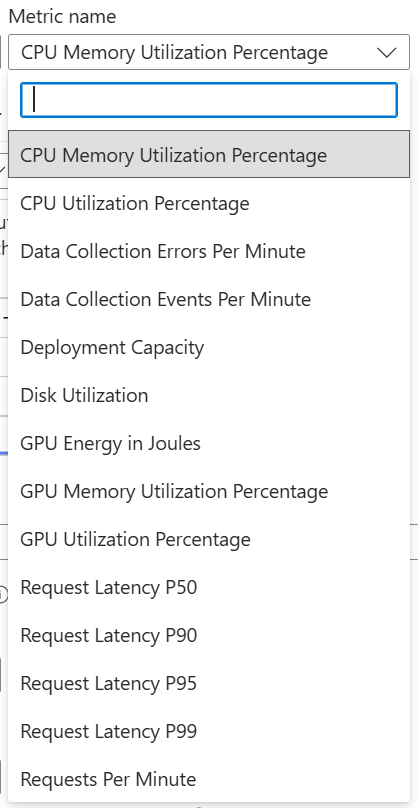
사용 가능 메트릭
| Scale Up | Scale Out |
|---|---|
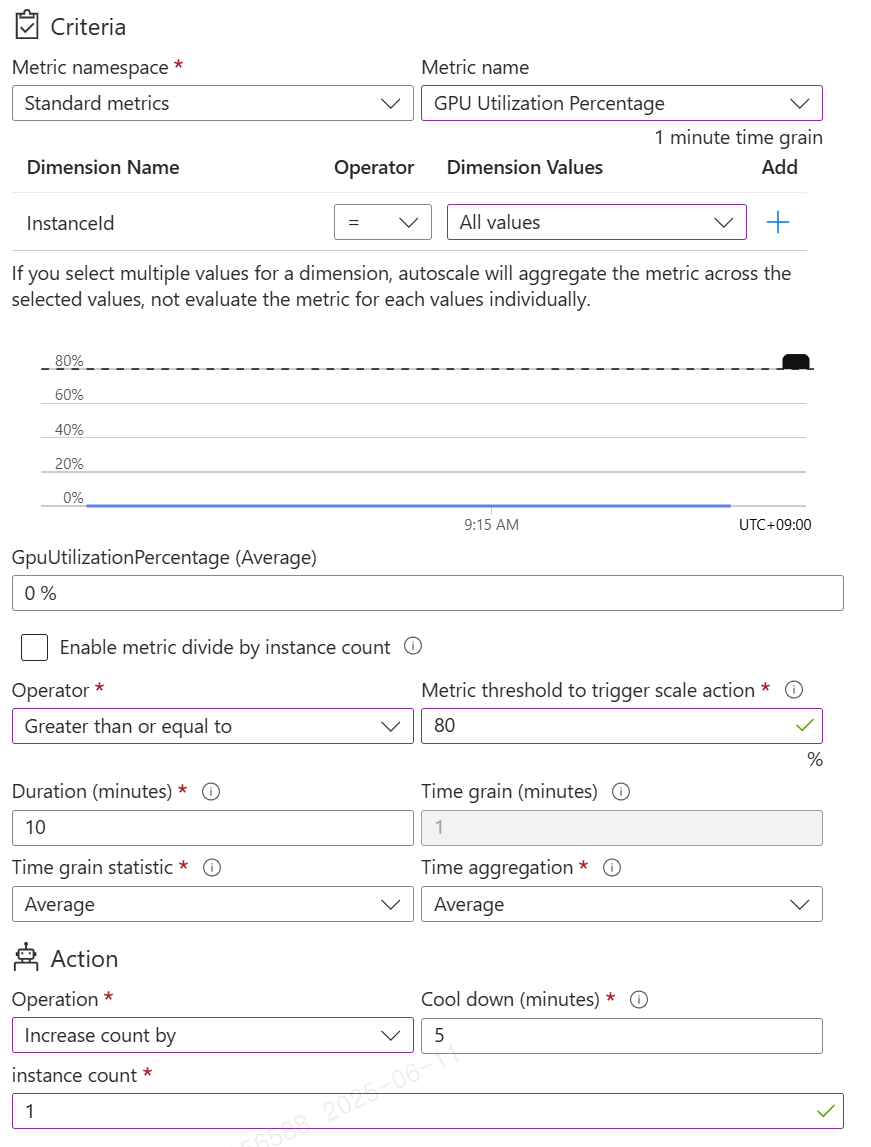
|
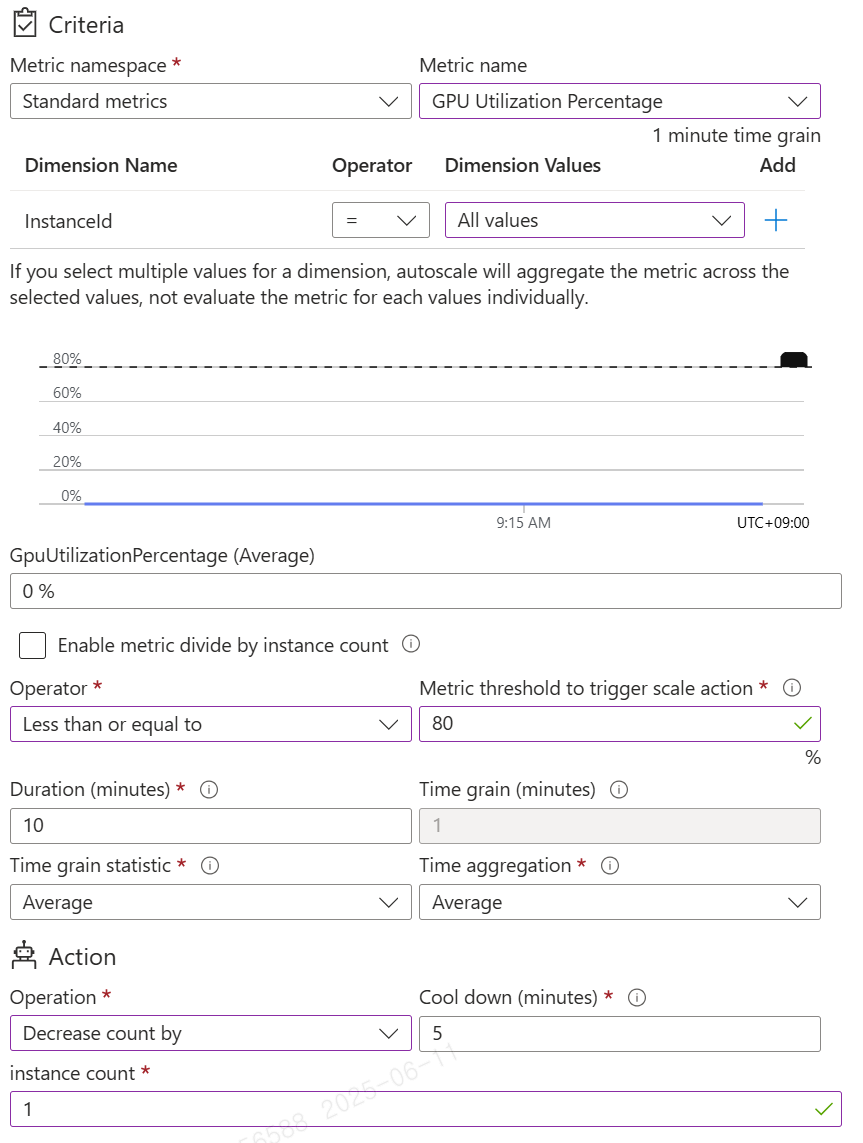
|
위 사진은 GPU 사용률 메트릭을 통해 Scale up, Scale out을 구현한 모습입니다.
이를 통해 평균 GPU사용률이 10분(Duration)동안 90%이상(Metric threshold)을 유지하는 경우 현재 인스턴스 개수에서 1개를 자동으로 늘리고, 반대로 90% 이하로 10분이상 유지 될 경우 다시 인스턴스 개수를 1개 감소 시키는 모습을 확인할 수 있습니다.
서빙 끝…?
이전 단계까지 완료했다면 REST API를 통해 엔드포인트에 배포된 모델에 정상적으로 추론 기능을 이용할 수 있습니다.
//요청 content : "안녕하세요! 좋은 글귀 하나만 부탁드려요!" //응답 content : "안녕하세요! 오늘의 글귀로는 다음과 같은 문구를 추천드립니다:\n\n\"진정한 용기는 두려움을 극복하는 것이 아니라, 두려움 속에서도 도전하는 것입니다.\"\n\n이 글귀는 어려움과 도전 앞에서도 자신의 길을 굽히지 않는 용기를 강조하고 있어요. 어떤 상황에서도 자신의 길을 찾고 걸어가는 힘을 얻길 바랍니다!"1234567
하지만 배포된 모델을 실제 서비스에 사용할 경우 다양한 시나리오를 고려해야 합니다.
요청이 어느정도 올 지, payload의 용량에 따른 bandwidth얼마나 설정해야 할 지, 요청에 대한 timeout은 어느정도 일지 등등 요청에 대한 다양한 리미트를 고려하여 테스트를 진행하던 중 아쉽게도 Azure ml 엔드포인트의 기본 리소스 제한이 저희의 예상 사용량보다 적다는 사실을 알게 되었습니다.
|
리소스 |
제한 |
|---|---|
|
구독당 배포 수 |
500 |
|
엔드포인트당 배포 수 |
20 |
|
배포당 인스턴스 수 |
50 |
|
엔드포인트당 초당 총 요청 수 |
500 |
|
엔드포인트당 초당 총 연결 수 |
500 |
|
엔드포인트당 활성화되는 총 연결 수 |
500 |
|
엔드포인트당 총 대역폭 |
5MBPS |
위 리소스 제한은 aml의 워크스페이스에서 직접 변경할 수 없어서 MS에 지원 요청을 접수해야 합니다.
저희는 실제 서비스의 예측 사용량을 바탕으로 각 항목별로 필요한 할당량을 계산하였고 Support Request 티켓을 발행 후 해당 값과 시나리오를 전달하여 빠르게 리소스 제한을 해제 할 수 있었습니다.
마치며
모델 서빙 업무를 수행하며 서빙 방법에 대하여 많은 변화가 있었고, 앞으로도 많은 변화가 이뤄질 것이라 예상됩니다. 6개월간 서빙 업무를 수행하며 모델들의 다양한 특성으로 인해 많은 어려움이 있었고, 앞으로 등장할 모델들과 서빙 환경의 변화로 인해 많은 난관에 부딪힐거라 생각됩니다.
다만 지금까지 쌓아온 경험을 토대로 이러한 난관을 보다 빠르게 해결하고, 자동화 프로세스를 구축하여 보다 효율적으로 서빙 업무를 수행 할 수 있을것이라 생각합니다.
마지막으로 각자 맡은 위치에서 열심히 업무를 수행해주시는 저희 팀원들에게 감사 인사를 드리면서 글을 마칩니다.
참고자료
Expanding AI tools and resources for developers and data scientists on Azure | Microsoft Azure Blog
Azure Machine Learning이란? - Azure Machine Learning | Microsoft Learn
Azure Machine Learning - ML as a Service | Microsoft Azure
Managed online endpoints VM SKU list - Azure Machine Learning | Microsoft Learn
Azure AI 파운드리 모델 | Microsoft Azure
Manage resources and quotas - Azure Machine Learning | Microsoft Learn