
안녕하세요, KT에서 Data Engineering을 담당하고 있는 이지우입니다. 지난 6월, 샌프란시스코에서 열린 Databricks Data + AI Summit 2025에 직접 참여하며, Databricks의 기술 전략과 로드맵을 현장에서 생생하게 확인할 수 있었습니다. 현장에서 발표된 기술들은 단순한 기능 개선을 넘어, 데이터 플랫폼의 구조 자체를 재정의하는 방향으로 진화하고 있었습니다. 특히 Databricks가 제시한 기술 로드맵은 “데이터와 AI의 통합”이라는 키워드를 중심으로, 실시간 처리, 자동화된 에이전트, 오픈 포맷 기반 거버넌스 등 다양한 영역에서 혁신을 보여주었습니다.
현장에서는 keynote 세션 시작 전, 스크린을 통해 CTO의 메시지가 소개되었습니다.
“In a world of constant change, data is the compass. Those who cultivate it won’t just survive – they’ll lead the future.”
데이터가 단순한 자산을 넘어, 조직의 방향성과 경쟁력을 결정짓는 핵심 요소임을 다시금 상기시켜주는 인상 깊은 슬로건이었습니다.

2025 Databricks summit 행사 시작 전, 스크린을 통해 송출된 CTO 메시지
이번 포스트에서는 Summit에서 발표된 기술 중, KT의 데이터 플랫폼에 실질적으로 적용 가능한 내용을 중심으로 정리했습니다. KT 데이터 플랫폼은 KT의 대규모 데이터 처리와 분석을 위한 핵심 인프라이며, 이번 발표에서 소개된 기술들을 통해 플랫폼의 성능, 확장성, 운영 효율성을 높이는 데 있어 검토 및 적용 가능한 부분들도 많이 엿볼 수 있었습니다.
아래에서는 각 기술의 주요 특징과 KT 환경에서의 적용 가능성을 기술적으로 정리해보았습니다.
1. Lakehouse 아키텍처의 진화: 오픈 포맷 + 통합 거버넌스

하지만 2023~2024년 사이 Databricks는 Iceberg에 대한 지원을 점진적으로 확대해왔고, 2025년 Summit에서는 “Delta와 Iceberg를 모두 100% 지원한다”고 공식 발표했습니다. 이는 단순한 기능 추가를 넘어, 특정 포맷에 종속되지 않고 오픈 생태계를 수용하는 방향으로 전략을 전환했다는 점에서 의미가 큽니다.
Iceberg는 Apache 커뮤니티 기반의 테이블 포맷으로, 다양한 분석 엔진과의 호환성, 고급 파티셔닝, 버전 관리 기능을 갖추고 있어 Snowflake, Dremio, Presto 등 여러 플랫폼에서 널리 사용되고 있습니다. Databricks가 Iceberg를 완전하게 지원함으로써, 이제 Hive Metastore와 Iceberg Catalog 인터페이스까지 호환되는 구조를 갖추게 되었고, 사용자는 포맷에 구애받지 않고 유연하게 데이터 저장 방식을 선택할 수 있게 되었습니다.
여기에 Unity Catalog를 통해 구조화/비구조화 데이터, ML 모델, BI 대시보드까지 포함한 모든 데이터 자산에 대해 통합 거버넌스를 적용할 수 있게 되었습니다. Unity Catalog는 단일 메타데이터 레이어로서, 엔터프라이즈 환경에서 필요한 모든 거버넌스 기능을 제공합니다. 특히 다양한 포맷과 도구를 사용하는 복잡한 데이터 환경에서도 일관된 정책을 유지할 수 있다는 점에서 KT와 같은 대규모 조직에 적합하여, KT의 데이터 플랫폼은 이미 Unity Catalog를 기반으로 데이터 자산에 대한 권한 관리, lineage 추적, 품질 모니터링 등 주요 기능을 활용해 운영되고 있습니다.
이번 Summit에서는 Unity Catalog의 기능이 한층 더 고도화되었는데, 특히 다음과 같은 확장이 눈에 띕니다:
Unity Catalog의 주요 기능 및 확장 사항
-
Delta Lake & Iceberg 모두에 대한 완전한 거버넌스 적용
-
Hive Metastore 및 Iceberg REST Catalog API 호환
-
데이터 lineage 시각화 및 추적
-
Row/Column-level 보안 정책 설정
-
감사 로그 및 액세스 이력 관리
-
품질 모니터링 및 정책 기반 접근 제어
-
Unity Catalog Metrics 도입: KPI 등 비즈니스 메트릭을 데이터 자산으로 정의하고 공유 가능
-
도메인 기반 데이터/AI 자산 마켓플레이스 기능 추가
특히 Unity Catalog Metrics 기능은 KPI 정의 및 공유, AI 기반 분석 자동화에 활용할 수 있는 기반을 제공하며, KT 데이터 플랫폼 내 BI/ML/AI 자산 간의 일관된 메트릭 관리가 가능해집니다.
KT 데이터 플랫폼에서의 활용 가능성
현재 KT는 Unity Catalog를 기반으로 데이터 플랫폼을 운영하고 있으며, 부서 간 협업 시 데이터 접근 권한을 세분화하여 관리하고, lineage 추적을 통해 데이터 흐름을 시각적으로 파악하는 등 거버넌스 기능을 실무에 적극 활용하고 있습니다. 이번 Summit에서 발표된 Iceberg 지원 확장과 Unity Catalog의 기능 고도화는 KT 데이터 플랫폼의 저장 포맷을 보다 유연하게 구성할 수 있는 기술적 기반을 제공하며, 외부 시스템과의 호환성 확보 및 오픈 생태계와의 통합에도 긍정적으로 활용할 수 있을 것으로 보였습니다.
-
Delta → Iceberg 포맷 전환 테스트 : KT 데이터 플랫폼 내 일부 테이블을 Iceberg로 변환한 후, 쿼리 성능, 스냅샷 관리, 파티셔닝 효율성 등을 Delta와 비교 분석
-
Unity Catalog 기반 거버넌스 고도화 시나리오 : 기존에 적용 중인 Unity Catalog 기능을 확장하여, Iceberg 기반 테이블에 대한 lineage 시각화, 감사 로그, 권한 관리 기능을 통합적으로 검증
2. Agent Bricks: 고품질 AI 에이전트의 자동 최적화 프레임워크

이번 Databricks Summit 2025에서는 AI 에이전트 개발의 복잡도를 획기적으로 낮춰주는 새로운 프레임워크, Agent Bricks가 공개되었습니다. 단순한 프롬프트 기반 접근을 넘어, 다양한 최적화 기법을 자동으로 조합해 도메인 특화 고품질 에이전트를 빠르게 구축할 수 있도록 설계된 것이 특징입니다.
현재 KT에서는, 다양한 부서가 생성형 AI를 활용한 데이터 기반 업무 자동화에 관심을 갖고 있습니다. Agent Bricks는 이러한 수요에 대응할 수 있는 실질적인 기술 기반을 가지고 있고, 특히 복잡한 설정 없이도 고품질 에이전트를 빠르게 구현할 수 있다는 점에서, KT의 실무 환경에 Agent Bricks를 적용한다면 데이터 플랫폼을 더 개선할 수 있겠다는 인사이트를 얻었습니다.
Agent Bricks가 해결하는 문제
기존의 에이전트 개발은 다음과 같은 문제를 안고 있었습니다:
-
프롬프트 설계, 모델 선택, 파인튜닝 등 수많은 설정을 직접 조율해야 함
-
품질 평가 기준이 불명확하거나 수작업에 의존
-
도메인 지식 반영이 어렵고, 유지보수가 복잡함
Agent Bricks는 이러한 모든 과정을 자동화하는 프레임워크입니다.
핵심 기능
-
자동 최적화 조합: 파인튜닝, 프롬프트 최적화, 강화학습, 에이전트 워크플로우 등을 상황에 맞게 조합
-
LLM Judge: 에이전트 품질을 자동으로 평가하고 개선
-
Agent Learning: “1990년 이전 데이터는 무시해 주세요” 같은 자연어 피드백을 기반으로 시스템을 재설계
-
멀티 에이전트 슈퍼바이저: 여러 에이전트를 연결해 복잡한 질의에 대한 종합 응답 생성
특히 Agent Learning은 단순한 피드백 수집을 넘어, 실제 벡터 인덱스 수정, 프롬프트 재구성, 툴 설명 변경 등 시스템 전반을 자동으로 최적화합니다.
KT 데이터 플랫폼에서의 활용 가능성
KT는 현재 내부 지식 검색, 부서 간 협업형 에이전트 구축 등 다양한 AI 기반 업무 혁신을 추진 중입니다. Agent Bricks를 잘 활용한다면, KT의 과제들에 다음과 같이 활용할 수 있을 것으로 생각했습니다:
-
내부 지식 어시스턴트 : 사내 정책, 기술 문서, 업무 프로세스를 기반으로 한 검색형 에이전트 구축
-
멀티 에이전트 슈퍼바이저를 통한 부서 간 협업형 질의 응답 시스템 구현 : 예) 사용자 문의에 대해 유관 부서가 협업 하여 종합 응답 생성
기존 챗봇과 달리, Agent Bricks는 도메인 지식 기반 응답, 지속적인 품질 개선, 복수 에이전트 간 협업이 가능한 구조를 제공하는 이점을 살려 에이전트를 구축 및 개발 할 수 있을 것입니다.
3. Spark 4.0과 LakeFlow: 실시간 스트리밍과 ETL의 새로운 기준
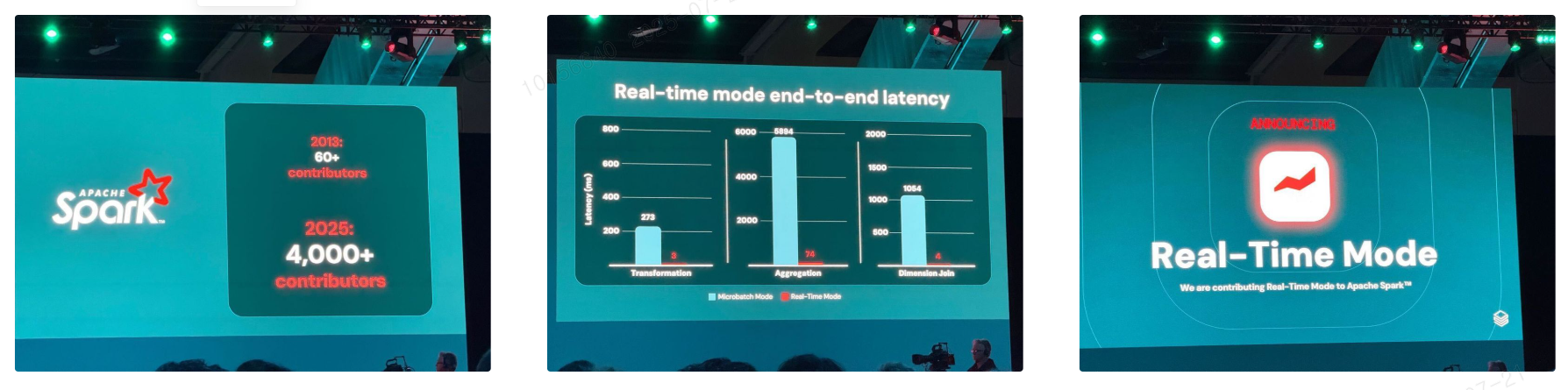
이번 Summit 에서는 Apache Spark 4.0과 함께, 실시간 스트리밍과 ETL 자동화를 위한 새로운 기능들 또한 대거 발표되었습니다. 특히 Real-Time Mode와 LakeFlow는 기존 Spark 기반 파이프라인의 복잡도를 줄이고, 운영 효율성과 성능을 동시에 개선할 수 있는 기술로 주목받았습니다.
KT의 데이터 플랫폼은 실시간성과 안정성이 중요한 대규모 데이터 환경에서 운영되고 있는 만큼, 이번에 발표된 Spark 4.0과 LakeFlow는 플랫폼의 구조를 보다 유연하고 효율적으로 설계하는 데 실질적인 도움이 될 수 있는 기술로 보였습니다. 특히 실시간 로그 수집, IoT 센서 데이터 처리, 외부 시스템과의 연동 등 다양한 파이프라인에서 복잡도를 줄이고 운영 부담을 낮출 수 있는 가능성이 엿보였습니다.
Spark 4.0의 주요 변화
-
SQL UDF 및 Pipe 문법 도입: 복잡한 변환을 직관적으로 연결 가능
-
Variant 타입 추가: Delta 및 Iceberg와 호환되는 유연한 데이터 표현
-
Spark Connect 확장: Swift, Rust, Go 클라이언트 지원
-
Streaming API 개선:
transformWithStateAPI로 복잡한 상태 기반 집계 간소화 -
Real-Time Mode 도입: 마이크로 배치 대신 지속 폴링 방식으로 밀리초 단위 지연 시간 구현
Real-Time Mode는 기존 구조적 스트리밍의 한계를 극복하고, 운영 시스템 수준의 초저지연 처리를 가능하게 합니다. Databricks는 이를 Apache Spark에 오픈소스로 기여하며, 향후 Spark 기반 실시간 처리의 표준으로 자리잡을 것으로 기대됩니다.

LakeFlow는 데이터 수집부터 변환, 운영까지 ETL 전 과정을 통합한 플랫폼으로, 다음과 같은 구성 요소로 이루어져 있습니다:
-
LakeFlow Connect: Salesforce, Workday, FTP 등 다양한 소스에서 데이터 수집
-
Zero Bus (Direct Write API): Kafka 없이 테이블에 직접 데이터 푸시 (5초 미만 지연)
-
Declarative Pipelines: 선언형 방식으로 ETL 구성 (DLT → Spark 오픈소스화)
-
Enzyme Engine: 변경된 데이터만 자동 감지 및 처리
-
LakeFlow Jobs: Power BI, DBT, Snowflake 등 외부 시스템과의 오케스트레이션 지원
Declarative Pipelines는 기존 DLT를 기반으로 하며, 코드 없이도 안정적인 ETL 파이프라인을 구성할 수 있도록 지원하며, 특히 Enzyme Engine은 변경된 데이터만 처리함으로써 비용 절감과 성능 향상을 동시에 달성합니다.
KT 데이터 플랫폼에서의 활용 가능성
앞서 언급했듯, KT의 데이터 플랫폼은 대규모 데이터 수집과 분석이 이루어지고 있는 시스템입니다. 실시간성과 안정성이 중요한 운영 환경에서, 이번 Summit에서 발표된Spark 4.0과 LakeFlow는 플랫폼의 구조를 보다 유연하고 효율적으로 개선하는 데 실질적인 인사이트를 제공했습니다.
이러한 인사이트를 기반으로, Spark 4.0과 LakeFlow를 KT 데이터 플랫폼에 적용해볼 수 있는 아이디어를 도출할 수 있었습니다:
-
KT 데이터 플랫폼 내 실시간 데이터 수집 파이프라인을 Zero Bus 기반으로 전환 : Kafka 인프라를 최소화하고, 운영 복잡도 및 비용을 절감
-
기존 DLT 파이프라인을 Declarative Pipelines 기반 ETL 구성으로 마이그레이션 : 기존 DLT 기반 파이프라인을 선언형 방식으로 전환함으로써, 코드 복잡도를 줄이고 유지보수 효율성 향상
-
LakeFlow Jobs를 통한 Snowflake, Power BI 등 외부 시스템과의 통합 오케스트레이션 : Snowflake, Power BI 등 외부 분석 도구와의 연동을 자동화하여, 생성된 데이터 자산을 다양한 채널로 손쉽게 전달
4. AI BI와 Databricks Designer: 비즈니스 사용자를 위한 데이터 인텔리전스
마지막으로, 이번 Databricks Summit 2025에서는 비즈니스 사용자를 위한 AI 기반 BI 플랫폼(AI BI)과 시각적 데이터 파이프라인 도구인 Lakeflow Designer가 공개되었습니다. 특히 Lakeflow Designer는 프리뷰 버전으로 첫 선을 보였으며, 비개발자도 자연어와 드래그 앤 드롭 방식으로 ETL 파이프라인을 구성할 수 있도록 설계된 점이 인상적이었습니다.
최근 데이터 플랫폼 전반에서 비개발자 중심 기능이 빠르게 확장되는 흐름이 이어지고 있습니다. 이러한 변화는 단순한 시각화 도구를 넘어, AI가 분석을 도와주는 환경이 기본값이 되어가는 변화는 KT와 같은 대규모 조직에서도 매우 긍정적인 방향이라 생각됩니다.
KT의 데이터 플랫폼에서도 기술 부서 뿐 아니라 마케팅, 운영, 전략 등 다양한 부서가 데이터를 직접 분석하고 활용하는 수요가 점점 늘어나고 있는 만큼, 향후 AI BI 플랫폼과 Lakeflow Designer을 활용할 수 있는 가능성이 많아 보였고, 기대되는 부분 중 하나였습니다.
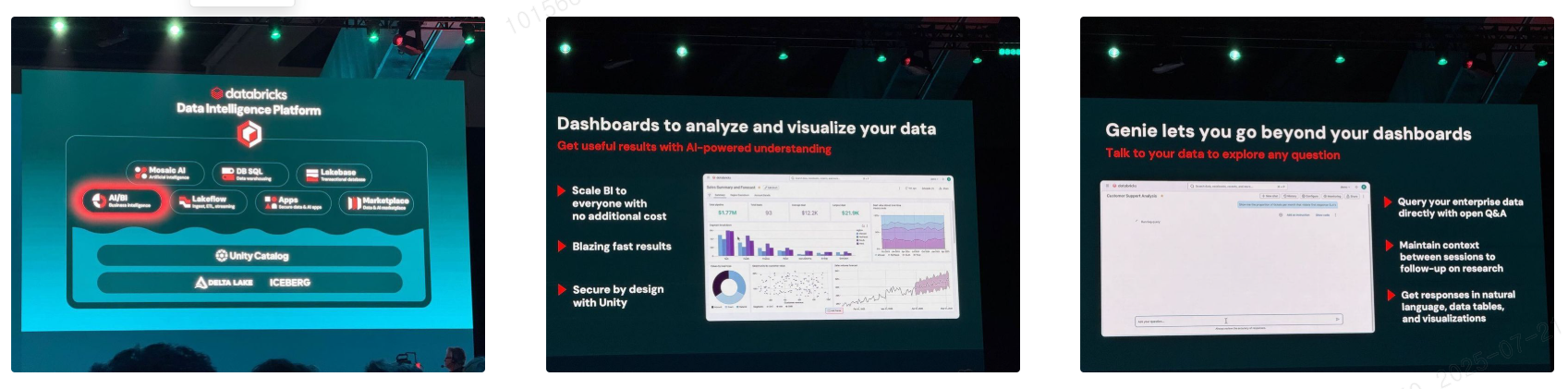
AI BI: 분석을 넘어선 인텔리전스
Databricks의 AI BI는 단순한 시각화 도구를 넘어, 자연어 기반의 데이터 탐색과 AI 분석 기능을 제공합니다.
-
Genie: 자연어 질의 → SQL 자동 생성 → 시각화 결과 제공
-
AI Forecast: 클릭 한 번으로 시계열 예측
-
AI Top Drivers: 이상값에 대한 원인 분석 자동화
-
Deep Research Mode (프리뷰 예정): 복잡한 질문에 대해 분석 계획 수립 및 병렬 분석 수행
특히 Genie는 대화 중 학습한 지식을 Unity Catalog Metrics로 승격하여 조직 전체에서 재사용할 수 있도록 지원합니다. 이를 통해 반복되는 분석 로직을 표준화하고, 다양한 AI 클라이언트에서 일관된 결과를 제공할 수 있습니다.

Lakeflow Designer: 코드 없이 파이프라인을 구성하는 시각적 도구
Lakeflow Designer는 프리뷰 버전으로 공개된 시각적 데이터 파이프라인 도구로, 비개발자도 ETL 파이프라인을 손쉽게 구성할 수 있도록 설계되었습니다. Databricks의 통합 데이터 엔지니어링 플랫폼인 Lakeflow 기반으로 작동하며, 다음과 같은 기능을 제공합니다:
-
자연어 기반 파이프라인 생성
-
예시 기반 변환(Transform by Example)
-
Genie와 연동된 분석 흐름 구성
-
생성된 파이프라인은 Declarative Pipelines로 자동 변환되어 프로덕션 환경에 바로 배포 가능
Lakeflow Designer는 아직 정식 출시(GA)는 되지 않았으며, 현재는 프리뷰 단계에서 일부 기능을 제한적으로 제공하고 있습니다.
KT 데이터 플랫폼에서의 활용 전략
KT의 데이터 플랫폼은 다양한 부서가 데이터를 기반으로 의사 결정을 내리는 환경에서 활용하고 있고, 운영되고 있습니다. AI BI와 Lakeflow Designer를 활용해 다음과 같은 방식으로 플랫폼의 활용성을 높일 수 있는 전략 아이디어를 생각해볼 수 있었습니다:
-
Genie를 통한 자연어 기반 데이터 탐색 : 비개발자도 SQL 없이 데이터를 질의하고 시각화 가능
-
Lakeflow Designer를 통한 셀프서비스 파이프라인 구성 : 마케팅, 운영, 전략 부서 등 비즈니스 사용자 대상 데이터 처리 자동화 및 분석 흐름 구성
마무리하며: 기술의 흐름 속에서 배우는 즐거움
이번 Databricks Summit 2025는 단순한 기술 발표를 넘어, 데이터와 AI가 어떻게 조직의 구조와 일하는 방식을 바꾸어가고 있는지를 현장에서 직접 체감할 수 있는 자리였습니다. 특히 실시간 처리, 자동화된 에이전트, 오픈 포맷 기반 거버넌스, 자연어 기반 분석 환경 등 다양한 기술들이 하나의 흐름으로 연결되어 있다는 점이 인상 깊었습니다.
개인적으로는, 기술이 단순히 “새롭다”는 것을 넘어서 어떻게 연결되고, 어떤 문제를 해결하며, 어떤 방식으로 조직에 녹아들 수 있는지를 이해하는 과정이 매우 흥미로웠습니다. 발표를 들으며 “이건 KT 데이터 플랫폼에 바로 써볼 수 있겠다”는 생각이 드는 순간들이 많았고, 그런 기술들을 현장에서 바로 눈으로 보고, 데모를 통해 직관적으로 확인할 수 있다는 점이 정말 새로웠습니다.
기술의 흐름을 따라가며 배우는 과정은 때로는 어렵지만, 그만큼 흥미롭고 보람 있는 경험입니다. 그리고 그 흐름 속에서 KT의 데이터 플랫폼이 어떤 방향으로 진화할 수 있을지 생각해보는 것도 매우 의미 있는 시간이었습니다. 앞으로도 이런 기술 컨퍼런스를 통해 새로운 시야를 넓히고, 현업에 적용 가능한 인사이트를 계속해서 발굴해나가고 싶습니다.
함께한 사람들
한슬기(IT Dev 본부), 김민지(IT Dev 본부), 김도영(Decision Intelligence Lab)