안녕하세요. 기술혁신부문 Gen AI Lab Sound AI팀의 김태수 선임과 Vision AI팀의 조문선 전임입니다.
지난 7월, 저희는 캐나다 밴쿠버에서 열린 머신러닝 학회 ICML 2025 (International Conference on Machine Learning)에 참석하고, 직접 논문을 발표하는 기회를 가졌습니다. 이번 학회는 최신 AI 기술의 흐름을 현장에서 체감하고, 글로벌 연구자들과 교류하며 KT의 기술 전략을 점검해볼 수 있는 뜻깊은 자리였습니다.
이번 블로그에서는 저희가 발표한 논문을 간단히 소개한 뒤, 학회 기간 동안 주목할 만했던 연구 발표와 주요 강연 내용을 공유드리고자 합니다.
ICML 2025 KT 발표 논문
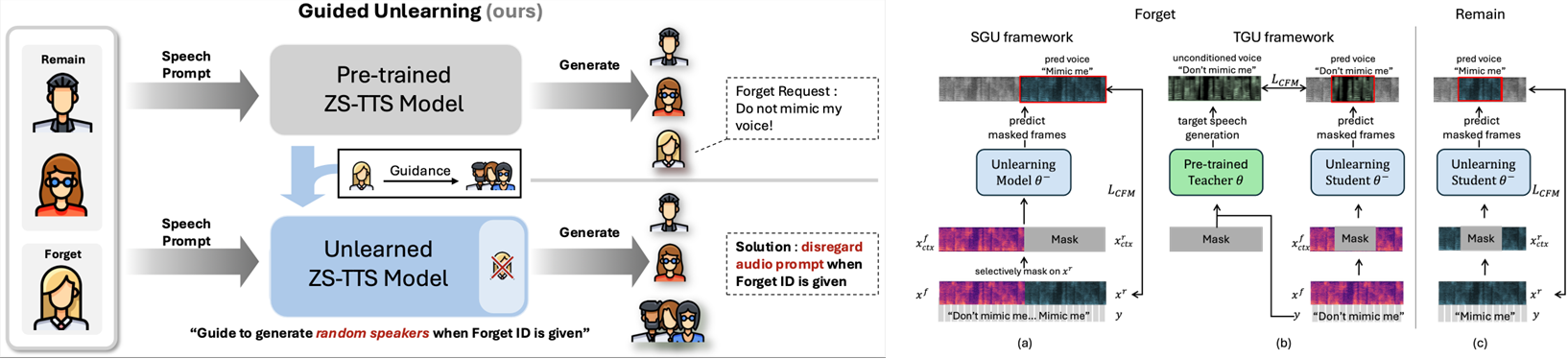
🤫 “내 목소리를 흉내 내지 마”: ZS-TTS를 위한 목소리 방지 시스템
Do Not Mimic My Voice : Speaker Identity Unlearning for Zero-Shot Text-to-Speech (김태수 (KT)*, 김진주 (성균관대)*, 김동찬 (성균관대), 박경문 (고려대), 고종환 (성균관대))
1. 문제 인식: 누구의 목소리든 복제하는 ZS-TTS의 프라이버시 위협
최근 제로샷 텍스트 음성 변환(Zero-Shot Text-to-Speech, ZS-TTS) 기술은 단 몇 초의 음성 샘플만으로 특정인의 목소리를 매우 높은 품질로 복제하는 수준에 이르렀습니다. 이는 분명 놀라운 기술적 발전이지만, 개인의 고유한 생체 정보인 목소리가 동의 없이 무단으로 도용되거나 악용될 수 있다는 심각한 프라이버시 및 윤리적 문제를 야기합니다. 문제는 이미 학습된 거대 AI 모델에서 특정 개인의 목소리 데이터만 선택적으로 ‘잊게’ 만드는, 즉 언러닝(Unlearning)하는 효과적인 방법이 없다는 점이었습니다. 단순히 특정 화자의 목소리를 탐지하고 거절하는 것을 넘어, 모델의 파라미터에 내재된 특정인의 목소리 특성을 제거하는 기술이 필요했습니다.
2. 해결책: 특정 목소리를 ‘무작위’ 음성으로 변환하는 Guided Unlearning
이 논문은 ZS-TTS 시스템을 위한 최초의 머신 언러닝 프레임워크인 가이드 언러닝(Guided Unlearniyng)을 제안하며 이 문제에 대한 해법을 제시합니다. 핵심 아이디어는 ‘잊어야 할(forget)’ 화자의 음성 프롬프트가 입력되었을 때, 단순히 목소리 복제를 피하는 것을 넘어 의도적으로 무작위적인(random) 목소리를 생성하도록 유도하는 것입니다. 예를 들어, 단순히 목소리 톤을 바꾸는 방식은 악의적인 사용자가 쉽게 원본으로 되돌릴 수 있는 위험이 있습니다. 하지만 이 방법은 특정인의 목소리 특성을 추적 불가능한 여러 음성 스타일로 흩어버림으로써, 원본 화자의 신원을 효과적으로 보호하고 모델이 해당 목소리를 ‘완전히 잊도록’ 만듭니다.
3. 학습 방식: Teacher-Guided Unlearning (TGU)
이러한 가이드 언러닝을 구현하기 위해 제안된 핵심적인 학습 방식은 TGU(Teacher-Guided Unlearning)입니다.
- Teacher-Student 구조: 기존에 학습된 ZS-TTS 모델을 ‘선생님(Teacher)’ 모델로 활용합니다.
- 랜덤 음성 타겟 생성: ‘잊어야 할’ 화자의 음성과 텍스트가 주어지면, 선생님 모델은 음성 프롬프트를 무시하고 오직 텍스트 정보만을 이용해 음성을 생성합니다. 이 과정에서 생성되는 음성은 초기화 값에 따라 매번 다른 사람의 목소리가 됩니다.
- ‘잊도록’ 학습: ‘학생(Student)’ 모델(언러닝을 적용할 모델)은 ‘잊어야 할’ 화자의 음성이 들어왔을 때, 선생님 모델이 생성한 무작위 음성을 정답으로 삼아 학습합니다.
- 성능 유지: 동시에 ‘기억해야 할(remain)’ 화자들의 데이터로는 기존 방식대로 학습을 진행하여, 다른 목소리 생성 성능은 그대로 유지합니다.
또한, 이 논문은 단순히 목소리 유사도(SIM)가 낮은지를 넘어, ‘잊어야 할’ 화자에 대해 얼마나 무작위적인 음성을 생성하는지를 측정하는 새로운 평가지표 spk-ZRF를 제안하여 언러닝 효과를 더욱 정밀하게 검증했습니다.
🏢 인사이트: 우리 서비스에의 적용 가능성
이 논문은 생성형 AI 시대에 필수적인 ‘잊힐 권리’를 기술적으로 구현한 선도적인 사례입니다. 특히 AI 모델에서 특정 사용자 데이터의 ‘영향력’ 자체를 제거한다는 점이 시사하는 바가 큽니다.
- AICC(AI 컨택센터) 고객 정보보호 강화: KT의 AICC는 수많은 고객의 음성 데이터로 학습됩니다. 만약 고객이 정보 삭제를 요청할 경우, 단순히 원본 녹취 파일을 지우는 것을 넘어 TGU와 같은 언러닝 기술을 적용할 수 있습니다. 이를 통해 모델 파라미터에 남아있는 고객의 음성 특징까지 제거하여, 해당 고객의 목소리를 더 이상 인식하거나 생성하지 못하도록 만들어 PII(개인 식별 정보) 보호 수준을 획기적으로 높일 수 있습니다.
- 개인화 추천 모델에서의 ‘고객 잊기’: 이 아이디어를 음성 외 다른 도메인으로 확장할 수 있습니다. 예를 들어, KT 상품 추천 모델이 특정 고객의 이용 패턴을 학습했을 때, 해당 고객이 마케팅 정보 활용 동의를 철회한다면 언러닝을 통해 모델에서 해당 고객의 데이터가 미친 영향(가중치)을 제거할 수 있습니다. 이는 단순히 DB에서 고객 정보를 지우는 것보다 더 근본적인 데이터 주권 보장 방식이 될 것입니다.
결론적으로, 이 연구는 AI 서비스 제공자로서 고객 데이터 프라이버시를 어떻게 기술적으로 책임질 수 있는지에 대한 중요한 방향을 제시하며, 향후 더욱 신뢰도 높은 AI 서비스를 구축하는 데 핵심적인 역할을 할 것입니다.
_______________________________________________________________________________________________________________
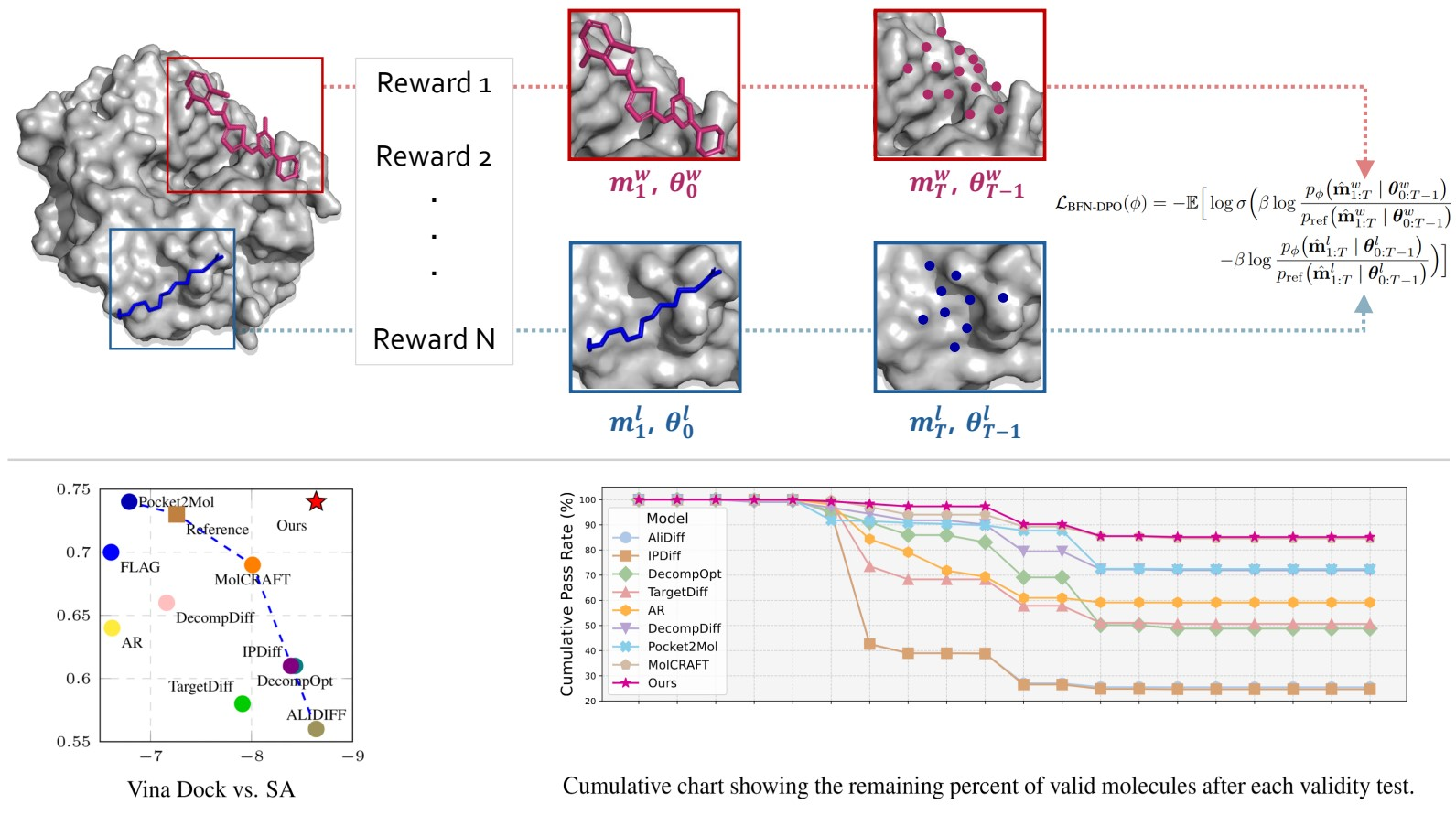
🧬 RL 기반 다중 보상 최적화: 신약 설계의 새로운 가능성
Enhancing Ligand Validity and Affinity in Structure-Based Drug Design with Multi-Reward Optimization (조문선 (KT)*, 이승범 (포항공대)*, 옥정슬 (포항공대), 김동우 (포항공대))
구조 기반 신약 설계(Structure-based Drug Design, SBDD)는 단백질 구조를 기반으로 결합 가능한 3차원 분자를 생성하는 기술입니다. 하지만 기존의 분자 생성 모델들은 대부분 학습 데이터의 통계적 분포를 모사하는 데 집중하여, 실제 신약 개발에서 필요한 결합 친화도, 합성 용이성, 구조적 안정성 등 다양한 특성을 동시에 만족시키는 데 어려움을 겪었습니다. 일부 연구에서는 결합 친화도라는 특정한 특성 하나에만 최적화된 분자를 생성했지만, 그 결과 다른 중요한 특성이 저하되는 문제가 발생했습니다. 신약 개발은 단일 지표가 아닌 다양한 특성의 균형이 핵심이기에 이를 동시에 고려할 수 있는 새로운 접근이 필요했습니다.
2. 해결책: 다중 보상 선호도 최적화
이러한 문제를 해결하기 위해 다중 보상(Multi-Reward)을 정의하고, 다중 보상을 기준으로 직접 선호도 최적화(Direct Preference Optimization, DPO) 방식을 새롭게 제안했습니다(그림 1). Bayesian Flow Networks(BFNs)을 분자 생성의 백본으로 사용하여, 사전 학습된 BFN 모델을 DPO 방식으로 파인튜닝하는 방법론입니다. 외부 평가 지표를 활용하여 생성된 분자의 다양한 특성에 대한 리워드 값을 계산한 뒤, 서로 다른 특성의 리워드 간 스케일 차이 정규화 및 불확실성 패널티 부여로 다중 보상을 정의했습니다. 이렇게 통합된 보상 신호를 기반으로 DPO를 수행하여 다양한 특성을 균형 있게 학습하는 방식입니다. 이러한 방식은 SBDD 분야에서 BFN과 DPO를 결합한 최초의 시도이고, 기존의 단일 보상 최적화 접근을 뛰어넘는 전략이기도 합니다.
3. 학습 방식: 다양한 특성을 모두 만족하는 신약 분자 생성
기존 분자 생성 모델들은 결합 친화도에만 최적화되고, 합성 용이성이나 구조적 유효성의 성능은 떨어지는 경향이 있었습니다. 하지만 우리의 모델은 다양한 특성 간의 균형을 학습하는 데 중점을 둡니다. DPO는 단순히 보상을 최대화하는 것이 아니라, 선호도 기반의 학습을 통해 모델이 어떤 분자를 더 "선호"하는지를 학습합니다. 이 과정에서 각 보상 지표의 중요도를 반영하고, 불확실성이 높은 보상에는 패널티를 부여함으로써 모델이 신뢰도 높은 리워드 신호를 중심으로 학습하도록 유도합니다. 결과적으로, 모델은 결합 친화도, 구조적 안정성, 약물화 가능성 등 다양한 지표에서 동시에 높은 성능을 달성할 수 있게 됩니다.
🏢 인사이트
우리의 모델은 기존 연구들이 도달했던 파레토 프론트(Pareto front)를 성공적으로 확장했습니다. 파레토 프론트란, 서로 상충할 수 있는 여러 특성들 사이에서 최적의 균형점들을 의미합니다. 예를 들어 결합 친화도가 높으면서도 합성 용이성이 뛰어난 분자는 일반적으로 찾기 어려운 조합입니다. 하지만 우리의 모델은 이러한 트레이드오프를 극복하고 두 특성을 동시에 만족시키는 분자들을 생성해냈습니다(그림 2). 또한 생성된 분자의 유효성을 평가하는 벤치마크에서도 기존 방법론들 대비 현저히 높은 유효성 통과율을 기록했습니다(그림 3). 이는 단일 지표에 최적화된 기존 모델들과 달리, 다양한 특성을 고려한 균형 잡힌 분자 생성이 실제 신약 후보로서의 가능성을 높일 수 있음을 입증합니다. 이러한 RL 기반 접근은 신약 설계뿐 아니라, 다양한 생성 분야 태스크에도 확장 가능성이 높다고 생각합니다.
_______________________________________________________________________________________________________________
ICML 2025 논문 소개
🤖 단기 응답을 넘어서: LLM의 대화 흐름 최적화 전략
CollabLLMs: From Passive Responders to Active Collaborators (Stanford & Microsoft, Outstanding)
대형 언어 모델(LLM)은 지금까지 대부분 Singleturn reward, 즉 다음 응답의 품질을 기준으로 학습되어 왔습니다. 이 방식은 빠르고 정확한 정보 제공에는 효과적이지만, 사용자의 궁극적인 목적이나 의도를 파악하는 데는 분명한 한계가 있습니다. 예를 들어, 사용자가 모호하거나 열린 질문을 던졌을 때, 모델은 종종 수동적이고 방어적인 태도로 응답하며 대화를 이어가지 못하는 경우가 많습니다. 이런 상황에서는 대화가 단절되거나 비효율적으로 흐르게 되고, 결국 사용자는 원하는 결과에 도달하지 못하게 됩니다. 이는 단기적인 응답 품질만을 중시한 학습 구조의 한계라고 볼 수 있습니다.
이러한 문제를 해결하기 위한 하나의 유망한 접근법이 바로 멀티턴 보상 함수(Multiturn-aware Rewards)의 도입입니다. 기존의 단일 응답 중심 평가 방식에서 벗어나, 모델이 전체 대화 흐름에서 얼마나 기여했는지를 평가하는 방식입니다. 즉, 모델이 한 번의 응답으로 끝나는 것이 아니라, 장기적인 협업 성과를 고려하여 능동적으로 대화를 이끌어가도록 유도하는 것입니다.
이러한 멀티턴 보상 구조를 실제로 적용하기 위해서는 두 가지 핵심 학습 방식이 필요합니다. 첫 번째는 Collaborative Simulation입니다. 다양한 대화 시나리오를 시뮬레이션하여, 각 응답이 전체 대화에 어떤 영향을 미치는지를 추정하는 과정입니다. 두 번째는 RL 기반의 파인튜닝입니다. 시뮬레이션을 통해 얻은 장기적 효과를 기반으로 모델을 미세 조정함으로써, 단순히 질문에 답하는 수준을 넘어서 사용자의 의도를 능동적으로 탐색하고 제안하는 능력을 갖추게 됩니다.
🏢 인사이트: 우리 서비스에의 적용 가능성
이러한 접근 방식은 단순한 기술적 개선을 넘어, 사용자 경험의 본질적인 향상을 의미합니다. 우리 KT 서비스에도 적용 가능성이 있는 부분은 고객이 원하는 분석 결과를 얻기까지의 대화 흐름을 학습하고 최적화하거나, 고객 지원 챗봇이 문제 해결까지 능동적으로 유도할 수 있도록 설계할 수 있습니다. 또한 문서 자동화 도우미가 사용자의 목적을 파악하고 필요한 정보를 제안하거나, AI 기반 협업 툴이 팀의 목표 달성에 기여하는 방식으로 대화를 설계하는 것도 가능합니다.
이러한 방식은 특히 RL 기반 멀티턴 보상 설계를 통해 더욱 효과적으로 구현될 수 있으며, 단기 응답의 품질을 넘어 장기적인 대화 흐름 최적화라는 새로운 패러다임을 제시합니다. 기술적 관점뿐 아니라 서비스 설계 관점에서도, 이 전략은 사용자 만족도와 성과를 동시에 높일 수 있는 강력한 도구가 될 것입니다.
_______________________________________________________________________________________________________________
🧠 소형 LLM의 한계 돌파: 스스로 진화하는 깊이 있는 수학적 사고
rStar-Math: Small LLMs Can Master Math Reasoning with Self-Evolved Deep Thinking (Xinyu Guan)
1. 문제 인식: 복잡한 추론의 벽에 부딪힌 소형 LLM
수학적 추론 능력은 LLM의 지능을 가늠하는 중요한 척도이지만, 이는 막대한 파라미터를 가진 거대 모델의 전유물로 여겨져 왔습니다. 소형 LLM은 경량화와 빠른 속도라는 장점에도 불구하고, 복잡하고 여러 단계의 사고가 필요한 수학 문제 해결에는 명확한 한계를 보여왔습니다. 단순히 정답을 맞추는 것을 넘어, 문제 해결 과정 전체를 논리적으로 전개하고 설명하는 '연쇄적 사고(Chain-of-Thought)' 능력이 부족하기 때문입니다. 이는 결국 특정 영역(domain-specific)에 소형 LLM을 적용하는 데 큰 걸림돌이 되어 왔습니다.
2. 해결책: 깊이 있는 사고를 스스로 학습하는 rStar-Math
이러한 한계를 극복하기 위해 제안된 핵심 아이디어는 스스로 깊이 있는 사고(Deep Thinking)를 진화시키는 rStar-Math 방법론입니다. 이는 정답과 오답이라는 이분법적 평가를 넘어, '더 나은' 풀이 과정을 선호하도록 모델을 점진적으로 학습시키는 방식입니다. 기존의 정답(Ground Truth)보다 더 논리적이고 효율적인 해결책이 있다면, 모델이 이를 스스로 발견하고 학습하도록 유도합니다. 즉, 정해진 길을 따라가는 학습에서 벗어나, 모델 스스로가 더 나은 길을 개척하며 문제 해결 능력을 키워나가는 것입니다.
3. 학습 방식: Rejection Sampling + Iterative Refinement
rStar-Math의 핵심 학습 방식은 다음과 같습니다.
- Rejection Sampling (기각 샘플링): 먼저, 모델이 하나의 문제에 대해 여러 가지 풀이(reasoning paths)를 생성합니다. 그리고 정답을 맞춘 풀이들만 남기고 나머지는 기각합니다. 이는 기본적인 논리적 오류를 줄이는 첫 단계입니다.
- Iterative Refinement (반복적 개선): 다음으로, 정답을 맞춘 풀이들 중에서도 '가장 뛰어난(superior)' 풀이를 보상 모델(reward model)을 통해 선별합니다. 이 선별된 데이터를 다시 학습에 활용하여 모델을 파인튜닝하는 과정을 반복합니다. 이 과정을 통해 모델은 점차 더 정교하고 논리적인 풀이 방식을 내재화하게 됩니다.
이러한 반복적인 자기 개선(self-evolution)을 통해, 소형 LLM은 복잡한 수학 문제에 대해 깊이 있고 다각적인 추론 능력을 갖추게 됩니다.
🏢 인사이트: 우리 서비스에의 적용 가능성
rStar-Math는 소형 LLM도 충분한 학습 전략을 통해 특정 분야의 전문가로 성장할 수 있음을 보여준 중요한 사례입니다. 이는 막대한 리소스 없이도 고도의 추론 능력을 갖춘 AI 모델을 확보할 수 있다는 가능성을 시사합니다. 핵심은 '하나의 정답'이 아닌 '최적의 과정'을 학습한다는 점이며, 이는 우리 KT의 서비스에 깊은 영감을 줍니다.
- 네트워크 장애 분석 및 예측: 장애 발생 시, 가능한 원인과 해결책의 경로를 여러 개 생성하고, 그중 가장 효율적이고 근본적인 해결책을 찾아내도록 모델을 학습시킬 수 있습니다. 이를 통해 초동 대응 시간을 단축하고 재발을 방지할 수 있습니다.
- AICC(AI 컨택센터) 상담 최적화: 고객 문의가 들어왔을 때, 문제를 해결하는 경로는 여러 가지일 수 있습니다. 단순 답변, 심층 상담, 담당 부서 연결 등 다양한 해결책 중, rStar-Math의 접근법을 적용하면 가장 짧은 시간에 고객 만족도를 최대로 이끌어내는 상담 경로를 스스로 학습하게 할 수 있습니다. 여러 성공적인 상담 시나리오를 생성하고 그중 가장 효율적인 프로세스를 선택하도록 모델을 반복적으로 개선하여, AICC가 단순 응대 에이전트를 넘어 문제 해결 전문가로 진화할 수 있습니다.
- 고객 맞춤형 상품 추천 고도화: 고객에게 유무선 통신, 미디어, 부가서비스 등을 추천할 때, 단순히 요금제 몇 개를 제시하는 것을 넘어 고객의 생애 가치(LTV)를 극대화하는 최적의 조합을 찾아내는 데 활용할 수 있습니다. 모델이 고객 데이터에 기반하여 여러 추천 조합(reasoning paths)을 생성한 후, 장기적인 고객 유지와 만족도에 가장 긍정적인 영향을 미치는 '가장 뛰어난(superior)' 추천안을 선택하도록 학습시키는 것입니다. 이는 단기적인 매출보다 장기적인 고객 관계 형성에 기여하는 추천 로직을 구축하는 데 도움이 됩니다.
결론적으로, rStar-Math의 접근 방식은 단순히 정답을 찾는 모델을 넘어, '최적의 과정'을 스스로 탐색하고 발전하는 모델을 만들 수 있다는 점에서 우리 AI 서비스의 지능을 한 단계 끌어올릴 중요한 열쇠가 될 수 있습니다.
_______________________________________________________________________________________________________________
ICML 2025 초청 강연
🧭 AI와 인간 가치의 Alignment: 변화하는 사회에 적응하는 시스템 설계
Adaptive Alignment: Using Quality Data in Designing AI for a Changing World (Frauke Kreuter)
AI와 Alignment을 주제로 한 Kreuter의 초청 강연은 기술 중심의 논의가 아닌, 사회적 맥락과 인간 중심 설계에 초점을 맞춘 내용이라 특히 인상 깊었습니다. 발표는 AI가 점점 더 사회와 제도, 일상에 깊숙이 관여하게 되면서, 단순히 성능 좋은 모델을 만드는 것을 넘어서 사람들이 실제로 받아들이고 신뢰할 수 있는 AI를 만드는 것이 중요하다는 문제 의식에서 시작되었습니다. 이를 위해 사회과학적 데이터(예를 들어 공공 여론조사나 국제 가치 조사)를 적극적으로 활용할 수 있다는 제안이 있었습니다. 특히 기억에 남았던 부분은 Alignment 기준이 고정되어서는 안 된다는 점이었습니다. 사회적 가치와 문화는 시간이 지나면서 변화하기 때문에, AI 시스템도 이에 맞춰 동적으로 업데이트되어야 합니다. 예를 들어, 프라이버시에 대한 인식이나 윤리적 소비에 대한 관심은 최근 몇 년 사이에 크게 달라졌고, 이런 변화에 적응하지 못하는 AI는 결국 신뢰를 잃게 됩니다.
하지만 현실적으로 AI 학습에 사용되는 데이터는 여러 문제를 안고 있습니다. 대표성 부족, 프레이밍 효과, 측정 오류 등 다양한 데이터 편향이 존재하며, 이를 해결하기 위해서는 사회과학자와 머신러닝 전문가 간의 협업이 필수적이라는 점이 강조되었습니다. 서로의 전문성을 결합해 정확하고 신뢰할 수 있는 데이터 수집 및 해석 체계를 구축해야 한다는 메시지가 인상 깊었습니다. 또한 발표에서는 AI/ML 커뮤니티에서 아직 충분히 활용되지 않고 있는 고품질 사회과학 데이터셋에 대한 소개도 있었습니다. CPS, GSS, ESS 같은 데이터는 인간의 선호와 가치에 대한 정량적 기준을 제공하며, AI 시스템의 정렬을 위한 강력한 기반이 될 수 있다는 점에서 실무적으로도 매우 유용한 정보였습니다.
🏢 인사이트: 사용자 피드백 Alignment 재설계
단순히 사용자 피드백을 수집하는 것을 넘어서, 사회적 맥락과 가치 변화를 반영하는 방식으로 Alignment 전략을 재설계할 수 있다는 점은 특히 실무자 입장에서 큰 도움이 되었습니다. 예를 들어, 제품의 윤리적 사용에 대한 인식 변화나 프라이버시 우려에 대한 민감도를 반영한 모델 업데이트는 사용자와의 신뢰를 강화하는 데 중요한 역할을 할 수 있습니다. 마지막으로, 데이터 오류를 해결하기 위한 두 가지 핵심 질문—“답이 정확한가?”, “누가 답하느냐?”—는 매우 실질적인 가이드라인이었습니다. 정답성 평가 기준을 명확히 정의하고, 도메인 전문가 기반의 라벨링 체계를 구축하는 것이 바람직하다는 제안은 현업에서도 바로 적용해볼 수 있는 부분이라 느꼈습니다.
정렬 기준은 특정 시점이나 문화에 국한되어서는 안 되며, 정기적인 사회적 가치 조사 결과를 반영한 모델 리트레이닝을 통해 지속적으로 변화에 적응하는 AI 시스템을 구축해야 한다는 결론은, 앞으로 우리가 AI를 어떻게 설계하고 운영해야 할지를 다시금 생각하게 해주었습니다. 이번 세미나는 기술과 사회를 연결하는 관점에서 매우 유익했고, 앞으로 우리 팀의 AI Alignment 설계 방향에도 많은 영감을 줄 수 있을 것 같습니다.
_______________________________________________________________________________________________________________
🛡️ 적대적 머신러닝의 새로운 지형: LLM 시대의 보안과 평가 과제
Adversarial ML: harder than ever (Nicholas Carlini)
언러닝 워크샵에서는 적대적 머신러닝(Adversarial ML)의 최신 동향과, LLM 시대에 우리가 직면하게 될 보안 및 평가 과제에 대한 논의가 있었습니다. 기존의 이미지 분류기나 악성코드 탐지기 중심의 연구에서 벗어나, 이제는 언어적 맥락과 사용자 의도까지 고려해야 하는 복잡한 공격 시나리오가 등장하고 있다는 점이 특히 인상 깊었습니다.
먼저 적대적 ML의 지형이 어떻게 변화하고 있는지를 짚었습니다. 과거에는 입력을 미세하게 조작해 모델의 예측을 틀리게 만드는 방식이 주를 이뤘다면, 이제는 LLM을 대상으로 한 대화 흐름 조작, 의도 왜곡, 정렬 우회 등 훨씬 더 정교하고 복합적인 공격이 가능해졌습니다. 이로 인해 기존의 방어 기법이 쉽게 무력화되며, 문제 정의 자체가 모호해지고 평가가 어려워지는 새로운 도전 과제가 등장하고 있습니다. 특히 흥미로웠던 부분은 “Unfinetunable 모델”에 대한 논의였습니다. 특정 목적에 맞게 파인튜닝이 불가능한 모델을 만드는 것이 보안 측면에서 중요한 목표로 제시되었지만, 최근 연구에서는 제안된 방어 기법들이 모두 우회되었다는 결과가 공유되었습니다. 이는 단순한 패치나 규칙 기반 방어로는 충분하지 않으며, 모델의 보안성을 근본적으로 재설계해야 할 필요성을 시사합니다.
또한 발표에서는 적대적 공격에 대한 정량적 평가 기준 부족이 AI 안전성 연구의 신뢰성과 산업적 적용에 미치는 영향을 강조했습니다. 방어 기법의 효과를 검증하기 어려운 상황에서는 연구 결과의 재현성이 떨어지고, 정책적 의사결정에 필요한 근거가 부족해지며, 실제 서비스에 적용하는 데도 큰 제약이 생깁니다. 이에 따라 공격 시나리오별 성능 저하율, 방어 기법 적용 전후의 성능 변화 등 새로운 평가 지표의 도입이 필요하다는 제안이 있었습니다.
🏢 인사이트: 우리 서비스에 적용 가능한 보안 전략
실무 관점에서도 많은 인사이트를 얻을 수 있었습니다. 특히 우리 서비스에 적용 가능한 보안 전략으로 다음과 같은 방향이 제시되었습니다:
- 보안성 강화: VLM을 비롯한 모델 기반 시스템이 의도치 않게 조작되거나 오용될 가능성에 대비해, 적대적 공격 시나리오를 사전에 고려한 설계가 필요합니다. 예를 들어, 이미지 기반 인증 시스템에서 입력 조작을 방지하거나, CCTV 분석 시스템에서 적대적 이미지 삽입에 대응하는 전략을 수립할 수 있습니다.
- 평가 체계의 정립: 모델의 Alignment뿐만 아니라, Robustness에 대한 내부 평가 기준을 마련해야 합니다. 공격 시나리오별 성능 저하율, 방어 기법 적용 전후의 성능 변화, 오탐/누락 비율 변화 등 실질적인 지표를 도입하는 것이 중요합니다.
- 데이터 파이프라인 보안: Carlini가 소개한 데이터 poisoning 공격 사례처럼, 외부에서 수집한 이미지나 텍스트 데이터에 의도된 악성 샘플이 포함될 수 있습니다. 이를 방지하기 위해 출처 검증, 샘플 무결성 검사 등 데이터 수집 단계에서의 보안 절차가 필요합니다.
- 협업 기반 연구 문화: 발표에서는 학제 간 협업의 중요성이 강조되었습니다. 우리도 보안 전문가, 윤리 담당자, 데이터 엔지니어 간의 긴밀한 협업 체계를 구축함으로써, 기술적 완성도뿐 아니라 사회적 책임을 다하는 AI 시스템을 만들어갈 수 있을 것입니다.
이번 세미나는 단순한 기술적 논의에 그치지 않고, AI 보안과 윤리의 접점에서 우리가 어떤 방향으로 나아가야 하는지를 고민하게 해준 자리였습니다. 앞으로 우리 팀에서도 Safety 평가 체계에 대한 논의를 더욱 강화해 나가야겠다는 생각이 들었습니다.
_______________________________________________________________________________________________________________
⚖️ 생성형 AI와 저작권법의 충돌: 혁신과 권리의 균형점 찾기
Generative AI’s Collision with Copyright Law (Pamela Samueson, 초청 강연)
1. 문제 인식: AI 학습 데이터, 저작권의 회색지대에 서다
생성형 AI 모델의 폭발적인 발전은 인터넷의 방대한 데이터를 학습에 활용했기에 가능했습니다. 하지만 이 과정에서 수많은 텍스트, 이미지, 코드 등 저작권이 있는 창작물이 무단으로 사용되었다는 주장이 제기되며 심각한 법적 문제에 직면했습니다.
AI 개발사들은 미국의 ‘공정 사용(Fair Use)’ 원칙이나 유럽의 ‘텍스트 및 데이터 마이닝(TDM)’ 예외 조항이 학습을 보호해 줄 것이라 기대했지만, 현실은 달랐습니다. 미국, 캐나다, EU 등 전 세계적으로 AI 개발사를 향한 저작권 침해 소송이 잇따르고 있으며, 기술 혁신과 창작자의 권리 보호라는 두 가치가 정면으로 충돌하고 있습니다.
2. 해결책: 글로벌 라이선스 체계와 커뮤니티의 법적 참여
이 복잡한 문제를 해결하기 위한 단일 해법은 존재하지 않습니다. 전 세계 모든 저작물을 포괄하는 ‘글로벌 라이선스’ 시스템은 현실적으로 불가능에 가깝습니다. 대신, 이 강연에서는 두 가지 현실적인 방향을 제시합니다.
- 집단 라이선스 체계 (Collective Licensing Regime): 특정 지역(EU, UK, 미국 등)이나 특정 저작물 유형에 한정하여 저작권자 단체와 AI 개발사가 협상하는 집단 라이선스 모델을 도입하는 방안입니다. 이를 통해 저작권자에게는 정당한 보상을, 개발사에게는 안정적인 데이터 확보를 가능하게 할 수 있습니다.
- ML 커뮤니티의 적극적인 법·정책 환경 조성 참여: 가장 중요한 해결책은 기술 개발자들이 법적, 정책적 논의에 직접 참여하는 것입니다. 혁신, 과학 연구의 자유를 지키면서도 창작자의 권리를 존중하는 균형 잡힌 법률 환경을 만드는 데 목소리를 내야 한다는 것입니다.
3. 주요 법적/정책적 쟁점: 공정 사용과 소송 리스크
이 강연은 기술적 방법론이 아닌, AI가 마주한 핵심적인 법적 쟁점들을 다룹니다.
- ‘공정 사용’의 엄격한 4가지 잣대: 미국의 공정 사용 원칙은 자동 면죄부가 아닙니다. ①사용 목적(상업적/비영리), ②저작물의 성격, ③사용한 양과 질, 그리고 가장 중요한 ④원저작물 시장에 미치는 영향을 종합적으로 따져 매우 까다롭게 판단됩니다.
- 불법 복제 데이터 사용의 위험: 학습 데이터에 저작권이 침해된 불법 복제(pirated) 자료가 포함된 경우, 공정 사용 주장이 매우 불리해지며 소송의 핵심 쟁점이 됩니다. (Bartz v. Anthropic 사례)
- 소송의 파괴적인 결과: 소송에서 패배할 경우, 막대한 금전적 손해배상을 넘어 모델의 배포 및 사용을 금지하는 금지명령(injunction)이나, 최악의 경우 학습된 모델 자체를 파괴(destruction)하라는 명령까지 내려질 수 있습니다.
🏢 인사이트: 우리 서비스에의 적용 가능성
이 강연은 AI 기술을 개발하고 서비스하는 KT에 매우 중요한 법적/전략적 시사점을 던져줍니다. 단순히 기술을 개발하는 것을 넘어, ‘어떻게 지속가능하게 사업을 영위할 것인가’에 대한 문제입니다.
- 학습 데이터의 출처 관리 및 문서화 필수: 모든 AI 모델의 학습 데이터 출처, 라이선스 여부를 철저히 기록하고 관리하는 시스템을 구축해야 합니다. 저작권이 불분명하거나 불법 복제된 데이터는 초기 단계에서부터 필터링하는 내부 정책이 시급합니다.
- AI 출력물의 ‘실질적 유사성’ 정기적 평가: 우리의 AI 서비스가 생성하는 결과물이 특정 원저작물과 법적으로 문제 될 소지가 있는 ‘실질적 유사성’을 보이는지 판단하는 기술적, 법률적 검토 프로세스를 마련해야 합니다.
- 국내외 규제 동향 전담 모니터링 및 정책 참여: 저작권 관련 법률과 판례는 국가별로 빠르게 변화하고 있습니다. 이를 전담하여 모니터링하고 사내에 전파하는 노력이 필요합니다. 더 나아가, 국내 저작권법 논의나 정책 수립 과정에 KT와 같은 기술 선도 기업이 적극적으로 참여하여 혁신과 권리가 균형을 이루는 합리적인 규제 환경을 만드는 데 기여해야 합니다.
맺음말
CML 2025는 최신 AI 연구 동향을 직접 접하고, 비슷한 분야를 연구하는 많은 연구자들과 교류하며 큰 영감을 얻을 수 있었던 뜻깊은 경험이었습니다. 특히 저희가 진행한 연구를 발표하고 다양한 피드백을 받을 수 있었던 점은 앞으로의 기술 개발 방향을 고민하는 데 큰 도움이 되었습니다. 또한 AI가 어디로 향하고 있는지, 그리고 우리가 그 흐름 속에서 어떤 역할을 할 수 있을지를 깊이 고민하게 만든 자리였습니다. LLM 시대의 보안과 정렬 문제, 평가 체계의 재설계 등은 단순한 모델 성능을 넘어서 AI의 책임성과 실용성을 함께 고려해야 한다는 흐름을 보여주었습니다. 발표와 토론을 통해 기술이 단지 “잘 작동하는 것”을 넘어서, 어떻게 연결되고, 어떤 문제를 해결하며, 실제 환경에 어떻게 녹아들 수 있는지를 이해하는 것이 점점 더 중요해지고 있음을 실감했습니다. 특히 RL 기반 접근법은 다양한 도메인에서 점점 더 강력한 도구로 자리잡고 있으며, 우리 모델에도 적용 가능한 가능성이 충분하다는 확신을 얻을 수 있었습니다.
기술의 흐름을 따라가며 배우는 과정은 어렵지만, 그만큼 흥미롭고 보람 있는 경험이라고 느꼈습니다. 이번 학회를 통해 얻은 인사이트는 앞으로의 연구와 서비스 설계에 있어 중요한 방향성을 제시해줄 것이라고 생각합니다. 앞으로도 이런 글로벌 기술 교류를 통해 새로운 시야를 넓히고, 현업에 적용 가능한 아이디어를 지속적으로 발굴해 나가고 싶습니다.