
안녕하세요. 저는 KT Agentic AI Lab에서 언어 모델의 연구 및 개발을 담당하고 있는 노경민입니다.이 글에서는 KT와 Microsoft가 협력하여 개발한 SOTA K built on GPT-4o 모델의 탄생 과정을 소개하고자 합니다. 데이터 구축부터 학습 전략, 협업 구조, 성능 평가에 이르기까지 전반적인 흐름을 상세히 설명드릴 예정입니다. SOTA K는 글로벌 최고 성능을 자랑하는 GPT-4o 모델을 기반으로, 한국의 지식과 정서를 깊이 있게 학습하여 한국에 대한 이해와 한국적 표현력이 강화된 모델입니다.
1. Overview: 한국을 위한 최적의 AI 모델, SOTA K
SOTA K는 KT와 Microsoft가 협력하여 개발한 한국 특화 AI 모델입니다. 이 모델은 GPT-4o의 뛰어난 성능을 기반으로, 한국의 역사, 문화, 정서, 언어적 뉘앙스를 정밀하게 학습했습니다. 기존의 글로벌 AI 모델들이 한국어를 지원하더라도, 한국적 표현과 맥락을 완벽히 이해하는 경우는 드물었습니다. 국내에서도 다양한 LLM 모델이 출시되었지만, 글로벌 수준의 모델과는 성능 차이가 존재했습니다.
KT는 이러한 한계를 극복하기 위해, 고품질의 한국어 데이터를 엄선하여 SOTA K에 정밀하게 추가 학습하고, 그 동안 자체 모델 ‘믿:음’과 오픈 소스 모델 ‘Llama K’ 등을 개발하면서 확보한 모델 개발 노하우를 Microsoft사의 모델 개발 노하우와 결합하여, SOTA K는 한국인의 자연스러운 표현과 문화적 맥락을 정확히 반영하는 모델로 완성되었습니다.
KT가 정의하는 ‘한국적 AI’는 다음과 같은 특징을 갖추고 있어야 합니다.
- 한국어에 최적화되어 경어체, 방언, 신조어 등 한국어 고유의 문법과 표현을 자연스럽게 이해하고 생성할 수 있어야 합니다.
- 한국 문화와 사회적 맥락에 대한 높은 이해도를 바탕으로, 한국 사회의 특성을 반영한 자연스러운 대화와 생성이 가능해야 합니다.
- 국내 산업에 특화된 지식과 표현을 포함하여, 법률, 금융, 국방, 역사 등 특정 산업군의 전문 용어와 은어, 그리고 의식주와 같은 사회적 관습까지도 정확하게 반영할 수 있어야 합니다.
- 한국 비즈니스 환경에 맞춘 업무(Task)를 수행할 수 있어야 하며, 고객 상담, 한글 문서 요약, 한국 법률 해석 등 한국 시장에 특화된 작업을 효과적으로 처리할 수 있어야 합니다.
KT는 GPT-4o의 글로벌 최고 수준의 성능을 유지하면서, 위와 같은 ‘한국적 AI’의 특징을 갖춘경쟁력 있는 한국 특화 모델로 SOTA K를 개발하였습니다.
2. 학습 데이터: 한국적 지식의 집대성
데이터 수집 및 정제
KT의 데이터 협의체를 통해 KT 자체 구축한 고품질 데이터 뿐 아니라 여러 협력사의 고품질의 데이터를 확보하여 SOTA K 모델 학습에 활용하였습니다. GPT-4o 모델에 한국적 지식과 한국적 표현이 정제된 고품질 데이터로 인문·역사·정치·경제·법률·사회·교육·자연과학(지리)· 문화·응용 과학 관련 다양한 한국적 도메인을 포함하고 이를 모델 학습에 사용하였습니다.
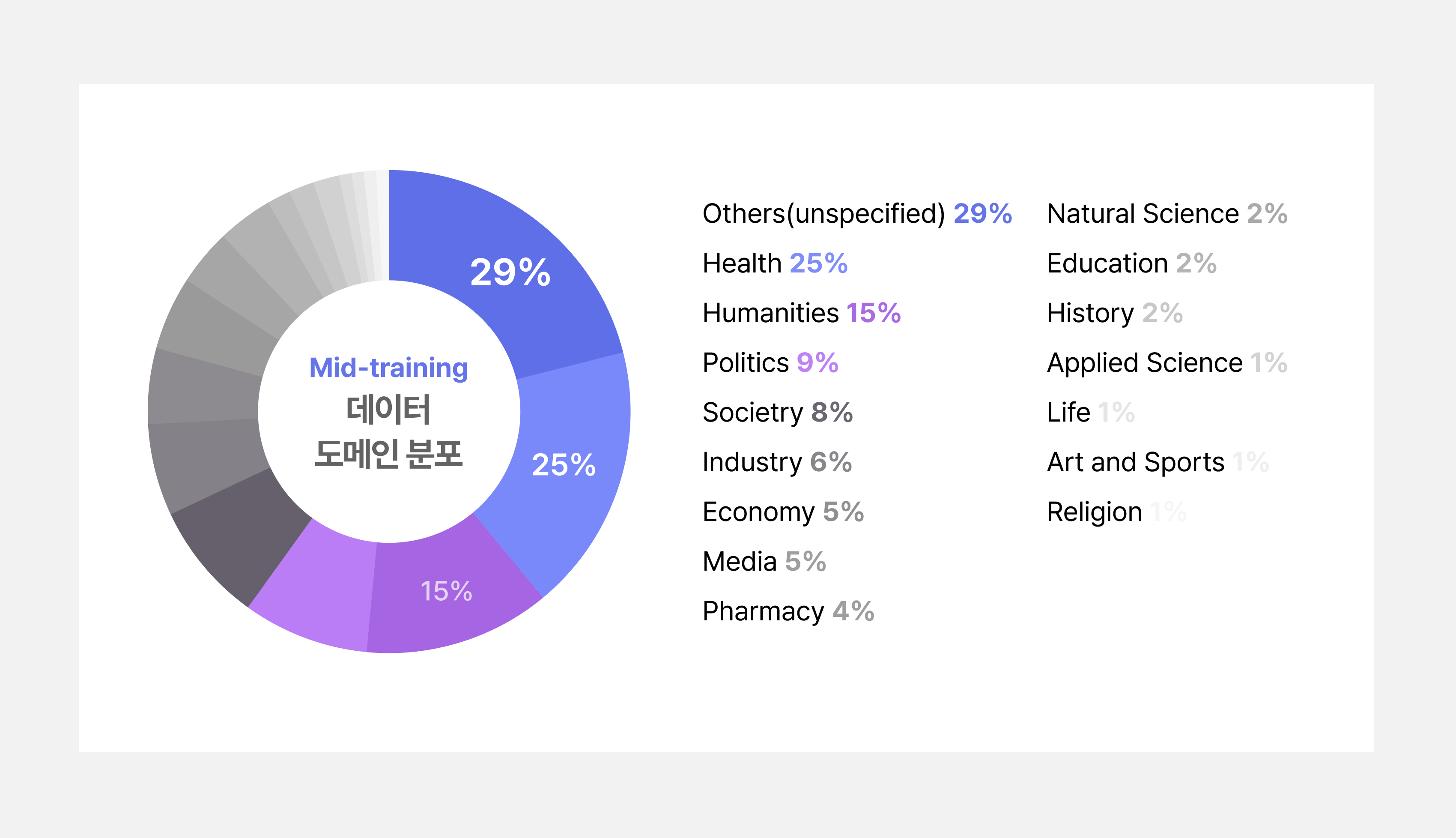
Mid-training 데이터 도메인 분포
3. 모델 구조와 학습 전략
SOTA K는 GPT-4o모델을 기반으로 하되, 한국어 역량 향상을 위해 1. 한국어 지식 향상, 2. 한국적 지시 이행/표현 향상, 3. 한국 정서에 맞은 응답을 목표로 학습을 진행하였습니다. GPT-4o의 취약 분야(정치, 법률, 역사, 경제 등)에 중점이 되는 데이터를 중심으로 지식을 확장하였으며, SFT와 RLHF 데이터를 통해 부족한 한국적 AI 표현과 K RAI 를 학습하였습니다. 한국적 AI는 K-value, K-style, K-knowledge로 정의 되어, K-values 영역에서는 지식보다는 답변 스타일을 정의하고 RLHF의 human feedback을 통해 어떤 답변 스타일을 더 선호하는지 모델에 학습하였습니다. K-knowledge, 와 K-style영역에서는 언어(경어체, 한국어 지시 이행) 와 한국적 지식(역사, 상식, 법률, 지리 등)의 GPT-4o의 취약 영역을 보강하는 것에 힘을 쏟고, 한국적역사관 및 특정 글 작성(E-mail, 사설 등) 에서 선호하는 스타일로 글 작성이 가능하도록 학습 하였습니다.
다음은 개략적으로 표현한 SOTA K의 학습 절차 입니다.
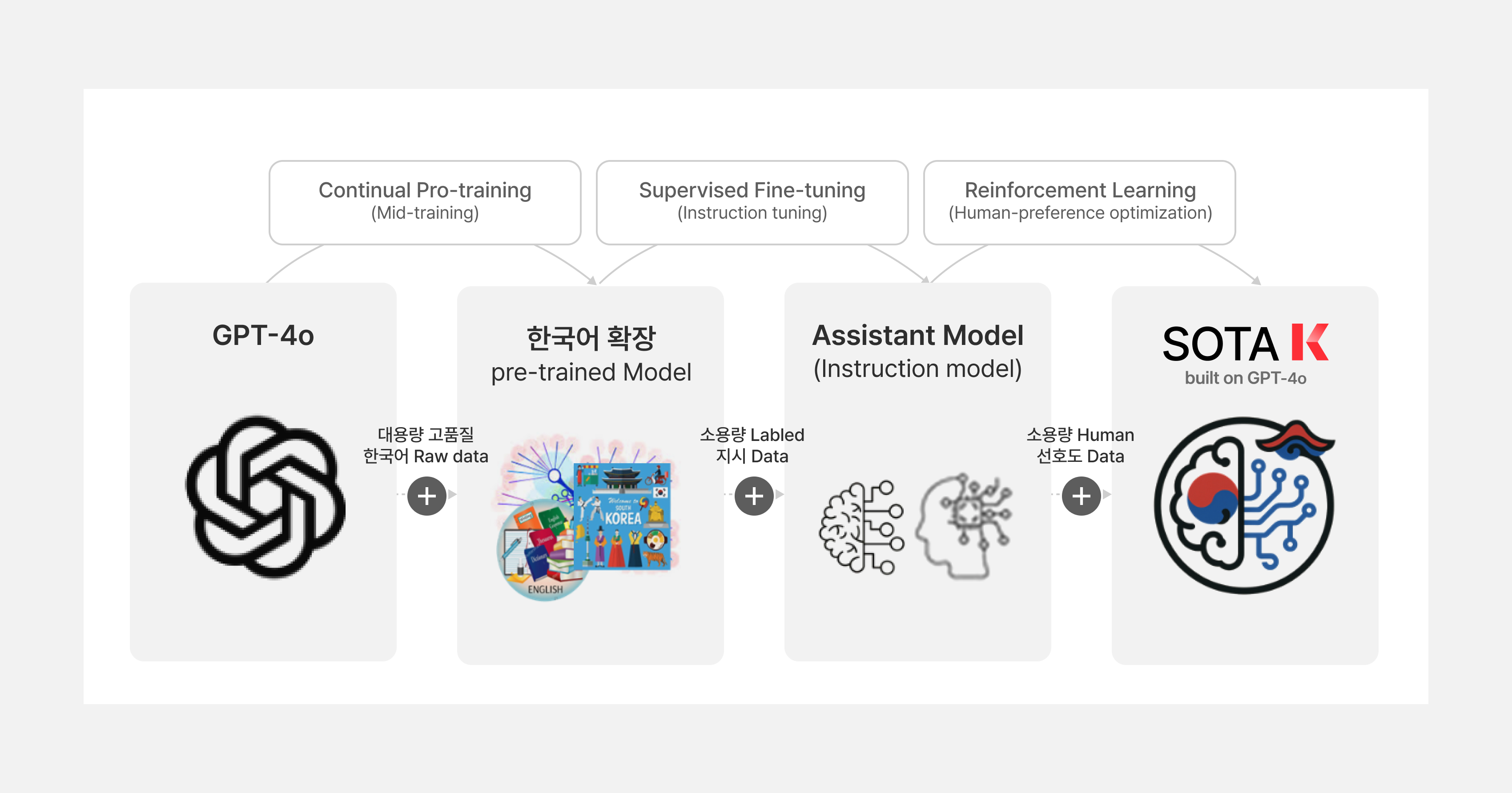
Continual Pre-training(Mid-training)
SOTA K의 주요한 목표 중 하나는 GPT-4o의 기본 지식을 잊어버리지 않고, 한국적 지식을 확장시키는 것입니다. 이를 위한 학습 기법이 Continual Pre-training 이며 한국어 지식 확장을 목표로 정제된 고품질 한국어 데이터로 추가 학습을 진행하였습니다. 이 단계에서는 GPT-4o 모델에 최대한 다양한 도메인의 CPT 데이터를, Microsoft의 대용량 모델 학습 기술로 학습시켰습니다. 각 데이터는 직접 구입/수집하였고, KT와 Microsoft의 데이터 전처리 기술을 통해 정교하게 정제되었습니다. 학습 데이터는 “Clearn room” 에 저장되며 특정 개발자만이 사용할 수 있고, 사용 로그를 남겨 SOTA K 개발 외 목적으로 사용되는 것을 전적으로 차단하였습니다.
Supervised Fine-tuning
Supervised Fine-tuning 단계에서는 한국적 명령 이행/표현 향상을 목표로 소량의 Labeled지시 데이터로 학습을 진행하였습니다. 학습한 지식을 잘 표현하고 이행 할 수 있도록 prompt-response 쌍으로 구성하여 GPT-4o의 취약 분야(한국적 지식에 대한 QA, 관계/상황에 따른 경어체 사용 이해도, 한국어 지시 이행, 부자연스러운 번역, 역사 지식, 글 작성(E-mail, 사설 등),전통 문화 등)에 대하여 SFT 데이터를 중점적으로 추가하여 학습하였습니다.
또한, 한국적 Responsible AI인 K RAI를 강화 하였습니다. K RAI는 5가지 Responsible AI 원칙(Accountability, Sustainability, Transparency, Responsibility, Inclusivity)을 가지고 있으며, 특히 RAI (Violence, Sexual, Self-harm, Hate and Unfairness, Misinformationand Disinformation, Political Neutrality, Anthropomorphism, Sensitive Usage,Privacy/Copyrights, Illegar or Unethical, Weaponization) 관련 답변의 경우, 한국적 입장에서 유해한 분야의 답변은 거절/회피 표현, 이유 등을 반드시 포함하도록 학습 하였습니다.
Reinforcement Learning
Reinforcement Learning 단계에서는 Human Alignment를 목표로, Human 선호도 데이터 학습을 진행하였습니다. 가장 중점을 둔 부분은 한국적 AI와 K RAI 관련하여 강화 학습을 진행하였습니다. KT 모델의 답변 스타일에 대한 답변 원칙을 세우는 과정이었고, 차후 KT의 한국적 AI 모델로써, 한국적인 RAI 기준으로 활용, 확장될 수 있는 토대를 구축하는 작업이기도 하였습니다.
4. 성능 평가
SOTA K 의 성능은 한국적 영량 향상과 추가 학습에 따라 기존 성능을 잃어버리게 되는 Catastrophic Forgetting 여부를 성능 지표로 삼았습니다. 그리고 한국적 특성에 맞는 RAI 평가 원칙을 세우고, 한국 비즈니스와 KT 사업 도메인에 필요한 Task를 고려하여 평가 기준을 마련하였습니다. 각각의 평가 기준에 맞는 지표를 수립하고 Microsoft와 협업하여 모델 평가를 진행하였습니다.
영어 능력의 Catastrophic Forgetting 여부를 판단하기 위해서 GPT-4o, Llama, Phi 등 메이저 LLM 모델이 사용한 평가 지표인, 허깅페이스 리더보드v1(H6), v2의 공개된 글로벌 정량 지표(영어 기반 평가)를 사용하여 모델을 평가하였습니다. 그리고 한국어 역량 향상을 평가 하기 위하여 KMMLU, LogicKor(LLM-Judge)와 같은 공개된 한국어 정량 지표(한국어 기반 평가)를 사용하였고, 부족한 한국 표현과 문맥, 문화 등을 평가 하기 위해서 한국적 AI 평가 지표를 추가 구축하였습니다. 이를 위해 고려대학교와 총 9개 영역(언어 및 문학, 역사, 문화 및 민속, 법률,경제 및 금융, 정치, 지리, 사회, 교육)에서 유창성, 최신성, 사실성, 편향성, 문화 맥락 이해 등 정량 평가 지표를 구축하여 활용하였고, 실제 체감 성능 향상을 위하여 소버린 영역의 주력 task를 선별(작문, 생성, 대화/QA, 이해, 분석/분류, 수리 등) 하여 전문가의 가이드에 따른 정성 평가를진행하였습니다.
마지막으로, KT는 한국어 및 한국 문화를 반영한 RAI 지표(3개 유형, 12종) 를 설계 하여 SOTA K가 한국 정서와 문화에 맞는 답변을 하는지 평가 하였습니다. KT RAI가 검토 하는 분야는 우선적으로, 국내외 AI 모델 모두 채택하고 사회적 이견이 적은 지표 영역(Hate / Sexual /Violence / Self-Harm 등) 이며, 다음은 주요 AI 모델(Claude, GPT-4) 등에서 채택한 영역(정치 및 종교 선동 / AI 무기화 / Misinformation 등)입니다.
마지막으로 AI모델의 사용 유형에 따라 선택적 제외 가능한 영역입니다. 예를 들어, 고위험 사용(법률, 의료, 금융 등), 과도한 의인화 방지 관련 영역입니다. 이렇게 총 12가지 다양한 영역에서 KT의 RAI 평가 지표를 세우고, 평가를 통해 보다 안전한 답변을 하는 모델로 개발하였습니다.
SOTA K는 영어 정량 평가에서 대부분 기존 GPT-4o보다 우수하여 기본 성능의 Catastrophic Forgetting 이 없다는 것을 확인하였고, 한국어 정량 평가 결과 또한 GPT-4o 대비 한국어 생성,한국어 추론, 한국 사회/문화, 한국 전문 지식 분야에서 우수함을 확인 할 수 있었습니다. 뿐만 아니라 정성 평가에서도 GPT-4o대비 생성(변환), 대화/QA, 이해, 수리 영역 등에서 우수함을 보였습니다.
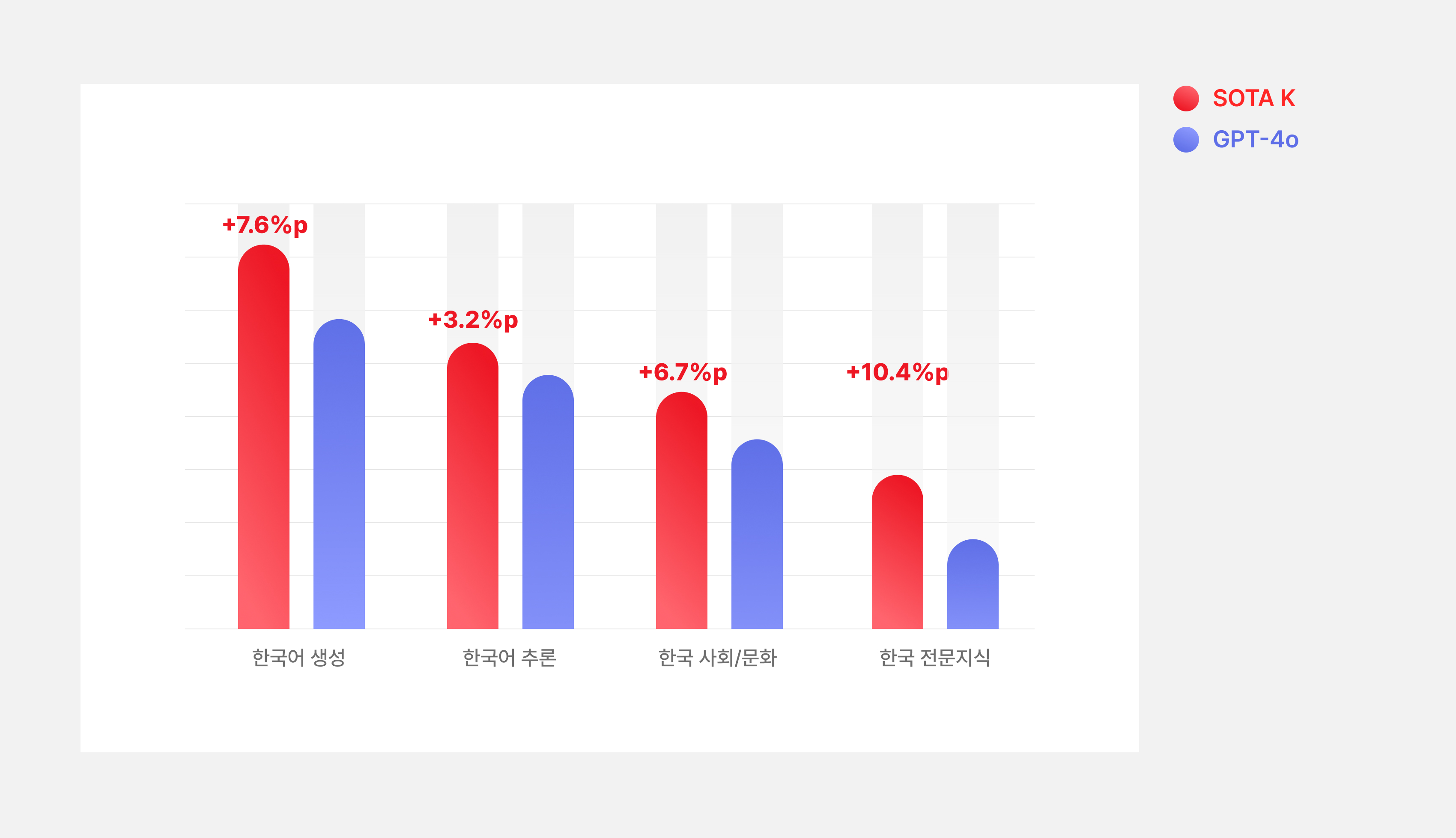
한국 특화 벤치마크 성능
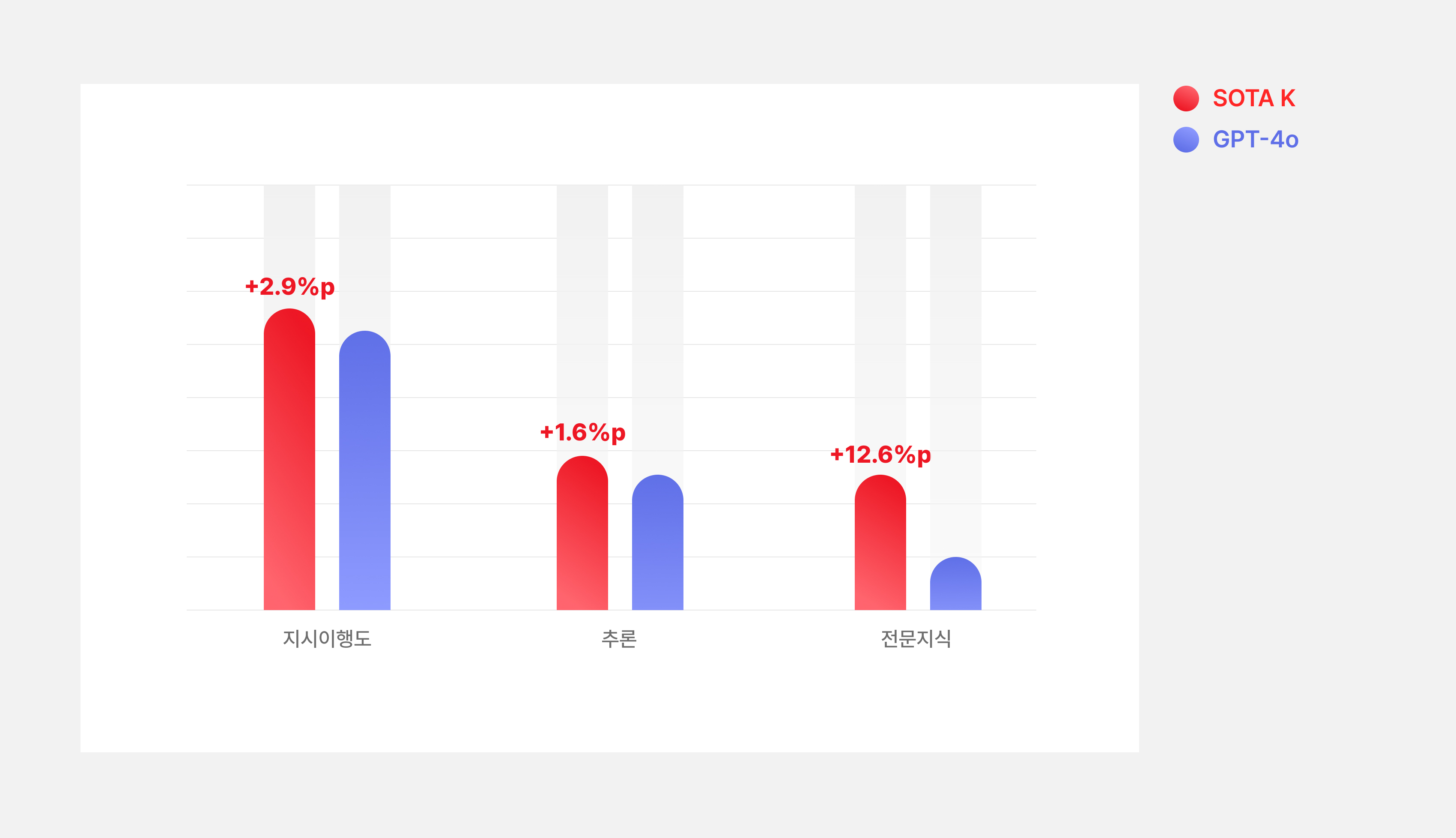
영어 벤치마크 성능
5. 윤리적 고려사항 및 한계
SOTA K는 학습 과정에서 비윤리적 표현을 최대한 제거했지만, 모든 위험을 완전히 배제할 수는 없습니다. 따라서 모델 사용 시 다음 사항을 반드시 유의해야 합니다.
- 전문 영역(법률·의료·금융): 모델의 답변은 참고용이며, 반드시 전문가의 검토가 필요합니다.
- 개인정보·유해 콘텐츠: 개인정보 요청이나 유해한 내용 생성은 금지되어 있습니다.
- 책임 있는 사용: 모델의 한계를 인식하고, 필요한 경우 추가 검증을 수행해야 합니다.
마무리
지금까지 SOTA K built on GPT-4o 모델의 개발 과정을 소개해드렸습니다. Microsoft와의 협업 모델을 만들면서 프로젝트 계획부터 모델 배포까지 각 단계별 lesssons learned가 많이 있었습니다.
프로젝트 계획에서 부터 데이터 구축/ 준비, Mid-training, Post-training, RLHF 의 단계별로 일정을 계획하고 추진했습니다. 한국적 AI를 만드는 데 있어서 RLHF가 끝이 아니라, 이후 한국 지정학적 이슈 등 한국 정서에 맞는 모델 alignment가 계획보다 오랜 일정 진행되었습니다. 개발 초기에 고려하지 못했던 상용화 관점의 모델 설계가 매우 필요함을 느꼈습니다. 뿐만 아니라, 데이터 구축 단계에서도 GPT-4o 모델을 기반한 모델이기에 GPT-4o의 취약 영역을 파악하고 개선하기 위한 데이터 구축이 중심으로 진행하였고, 여러 한국적 도메인 별 데이터를 확보하여 학습하였습니다. 다만, 몇 건의 특수 문자/ 학습 데이터의 형태가 전체 답변에 크게 영향을 줄 수 있다라는 것을 경험하였고, CPT 데이터 뿐만 아니라 SFT/RLHF 데이터에서의 데이터 선별도 매우 중요함을 느꼈습니다.
SOTA K 개발은 LLM 모델 개발 end to end 전 과정을 Microsoft와 함께 검증하는 시간이었고, 데이터 설계부터, 최종 평가/배포까지 모든 단계에서 KT 내부적으로는 모델 전 과정의 프로세스를 확립하는 좋은 기회이면서, 실무자들의 실무 역량이 높일 수 있는 기회이기도 하였습니다. 작년 9월부터 매주 금요일 오전 미국 Redmond의 Microsoft 엔지니어와의 미팅은 효과적인 prompt engineering, 모델 답변 이슈에 따른 대응 방식 등 비개발 인력의 개발 지식을 습득 할 수 있는 기회이기도 하였습니다. 하지만, Redmond와 서울과의 17시간의 시차로 인한 협업 지연도 있었고, 한번의 실무워크샵이 있긴 하였지만, 더 많은 교육/교류를 하지 못한 점은 매우 아쉽습니다. 부서간의 협업이 아닌 회사간의 협업이었기에 IP 이슈로 공유 하지 못한 데이터 레서피나 구체적인 alignment방식 등이 특히 아쉬움으로 남습니다.
SOTA K는 초기 개발 목표였던 base model 대비 한국 특화 유의미한 성능 개선을 보였으며, base model인 GPT-4o의 영어 성능 또한 유지 할 수 있었습니다. 이 평가 과정에서 정량/정성평가 프로세스를 확립하고, 자체 평가지표를 개발하는 등 평가 프로세스를 새로 정밀하게 확립할 수 있었습니다. 뿐만 아니라 KT DSB(Depolyment Safety Board)라는 위원회/배포 절차를 확립함으로써 모델을 좀 더 안전하게 배포 할 수 있는 초석을 마련하였습니다.
이렇게 SOTA K는 한국 특화 모델 개발이라는 결과물 이외에도 KT 내부 모델 개발 전 과정을 검증하고 프로세스를 확립하는 프로젝트였습니다. SOTA K는 한국 비즈니스의 다양한 분야에서 AI 기술이 더 자연스럽고 안전하게 활용될 수 있도록 개발 되었습니다. 앞으로도 KT는 지속적인 연구와 개선을 통해 더욱 발전된 모델을 선보일 예정입니다. 많은 관심과 기대 부탁드립니다. 감사합니다.